
目标
- 整理对 块大小 副本数的理解
- 整理对小文件的理解
- 整理HDFS架构
- 整理SNN流程
修改hdfs的数据保存文件
在开始完成今天的目标之前,我们还要做一个事情,那就是修改hdfs的nn、nd、snn文件保存的目录,这个目录默认保存在/tmp目录下,那么为什么会保存在/tmp目录下呢,实际上是由core-default.xml默认参数决定的
| KEY | VALUE | DESC |
|---|---|---|
| hadoop.tmp.dir | /tmp/hadoop-${user.name} | A base for other temporary directories. |
因为/tmp目录具有固定周期清除文件的特性,所以我们这里需要改变hadoop的存储文件路径,防止丢失文件
[hadoop@aliyun hadoop]$ vim core-site.xml |
在这之后我们还要对/home/hadoop/tmp目录做一下调整
chmod -R 777 /home/hadoop/tmpmv /tmp/hadoop-hadoop/dfs /home/hadoop/tmp/test
对块大小和副本数的理解
块的理解
hadoop1.x的块大小是64M,hadoop2.x的块大小是128M,块的大小是hdfs-default.xml文件中的dfs.blocksize属性控制,它是hdfs存储处理数据的最小单元,可以根据实际需求改变块大小,但是一般不建议这么做。
| KEY | VALUE |
|---|---|
| dfs.blocksize | 134217728(128M) |
hadoop1.x的块大小是64M,hadoop2.x的块大小是128M,块的大小是hdfs-default.xml文件中的dfs.blocksize属性控制,它是hdfs存储处理数据的最小单元,可以根据实际需求改变块大小,但是一般不建议这么做。
块大小为什么要设计成128M?
是为了最小化寻址时间,目前磁盘的传输速率普遍是在100M/S左右,所以设计成128M每块。
副本数的理解
副本的设置让hadoop具有高可靠性的特点,数据不会轻易丢失。副本是存储在dn中的,由hdfs-default.xml文件的dfs.replication参数控制,伪分布式部署是1份,集群部署是3份,不建议修改。
| KEY | VALUE |
|---|---|
| dfs.replication | 3 |
对小文件的理解
一般来说,小文件是文件大小小于10M的数据,由于hadoop的架构特性,它只能有一台主nn,如果小文件特别多的话,小文件的块也特别多,nn需要维护的块的元数据信息的条数也多,所以我们一般把小文件合并成大文件再放到hdfs上,也有上传hdfs后合并,这样来减少nn维护的块的元数据数量。具体合并的方式,以后再讲。
整理HDFS架构
HDFS由NameNode、SecondaryNameNode、DataNode三个组件组成
NameNode
NameNode也被称为名称节点或元数据节点,是HDFS主从架构中的主节点,相当于HDFS的大脑,它管理文件系统的命名空间,维护着整个文件系统的目录树以及目录树中所有子目录和文件。
这些信息以两个文件的形式持久化保存在本地磁盘上,一个是命令空间镜像FSImage(File System Image),主要是用来存储HDFS的元数据信息。还有一个是命令空间镜像的编辑日志(Editlog),该文件保存用户对命令空间镜像的修改信息。
SecondeayNameNode
SecondaryNameNode也被称为元数据节点,是HDFS主从架构中的备用节点,主要用于定期合并命名空间镜像(FSImage)和命令空间镜像的操作日志(Editlog),是一个辅助NameNode的守护进程。
定期合并FSImage和Editlog的周期时间是由hdfs-default.xml文件的dfs.namenode.checkpoint.period属性决定的,默认一小时合并一次,同时如果Editlog操作日志记录满 1000000条也会触发合并机制,由dfs.namenode.checkpoint.txns属性控制,两者满足一个即可。
| KEY | VALUE | DESC |
|---|---|---|
| dfs.namenode.checkpoint.period | 3600 | 两个周期性检查点之间的秒数。 |
| dfs.namenode.checkpoint.txns | 1000000 | 两个周期性检查点之间的名称空间记录数。 |
虽然SecondaryNameNode能够减轻单点故障,但是还会有风险,因为总有一段时间的数据是没有同步的。
问题: 为什么SecondaryNameNode要辅助NameNode定期合并FSImage文件和Editlog文件?
FSImage文件实际上是HDFS文件系统中元数据的一个永久性检查点(checkpoint),但也并不是每一个写操作都会更新到这个文件中,因为FSImage是一个大型文件,如果频繁地执行写操作,会导致系统运行极其缓慢,那么如何解决呢?
解决方案就是NameNode将命令空间的改动信息写入命令空间的Editlog,但随着时间的推移,Editlog文件会越来越大,一旦发生故障,那么将需要花费很长的时间进行回滚操作,所以可以像传统的关系型数据库一样,定期地合并FSImage和Editlog,但是如果由NameNode来做合并操作,由于NameNode在为集群提供服务的同时可能无法提供足够的资源,所以为了解决这一问题,SecondaryNameNode就应运而生了。
DataNode
DataNode也被称为数据节点,它是HDFS主从架构在的从节点,它存储数据块和数据块校验和它在NameNode的指导下完成数据的IO操作。
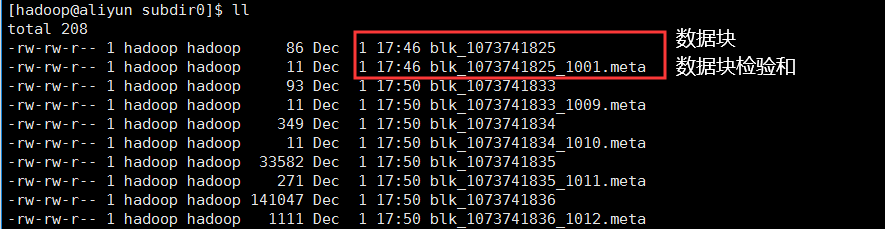
DataNode会不断地向NameNode发送心跳和块报告信息,并执行来自NameNode的指令。
发送心跳是为了告诉nn我还活着,通过hdfs-default.xml文件的dfs.heartbeat.interval参数可以得知,每3秒发送一次
| KEY | VALUE | DESC |
|---|---|---|
| dfs.heartbeat.interval | 3 | Determines datanode heartbeat interval in seconds. |
发送块报告信息是为了扫描数据目录并协调内存块和磁盘块之间的差异的,从hdfs-default.xml文件的dfs.datanode.directoryscan.interval属性和dfs.blockreport.intervalMsec可以得知每6小时发送一次块报告,生产环境下建议缩短周期(3小时)
| KEY | VALUE | DESC |
|---|---|---|
| dfs.datanode.directoryscan.interval | 21600 | DataNode扫描数据目录并协调内存块和磁盘块之间的差异的时间间隔(以秒为单位),发现损坏块 |
| dfs.blockreport.intervalMsec | 21600000 | 确定以毫秒为单位的块报告间隔,恢复数据块 |
在这里我们需要知道一个hadoop命令,该命令仅适用于高级用户,不正确的使用可能会导致数据丢失。
[hadoop@aliyun subdir0]$ hdfs debug |
手动修复
hdfs debug的作用是在多副本的环境下手动修复元数据、块或者副本,我们在这里只说修改副本,这里的xxx是指副本路径,该路径必须驻留在HDFS文件系统上,由hdfs fsck命令查找。
hdfs debug recoverLease -path xxx -retries 10 |
自动修复
但是有可能: 手动修复 + 自动修复都是失败的
这就需要保证数据仓库的数据质量和数据重刷机制恢复
问题: DataNode是如何存储和管理数据块的?
- DataNode节点是以数据块的形式在本地Linux文件系统上保存HDFS文件的内容,并对外提供文件数据访问功能。
- DataNode节点的一个基本功能就是管理这些保存在Linux文件系统上的数据
- DataNode节点是将数据块以Linux文件的形式保存在本地的存储系统上
SecondaryNameNode和NameNode的交互流程
.JPG)
SecondaryNameNode引导NameNode滚动更新操作日志,并开始将新的操作日志写进edits.new。SecondaryNameNode将NameNode的FSImage文件和Edits文件复制到本地的检查点目录。SecondaryNameNode将FSImage文件导入内存,回放编辑日志Edits文件,将其合并到FSImage.ckpt文件,并将新的FSImage.ckpt文件压缩后写入磁盘。SecondaryNameNode将新的FSImage.ckpt文件传回NameNode。NameNode在接收新的FSImage.ckpt文件后,将FSImage.ckpt替换为FSImage,然后直接加载和启用该文件NameNode将Edits.new更名为Edits。默认情况下,该过程1小时内发生1次,或者当编辑日志达到默认值1000000条也会触发。
补充
NN的fsimage的个数默认是保留2个

控制的参数是
hdfs-default.xml文件的dfs.namenode.num.checkpoints.retained参数KEY VALUE dfs.namenode.num.checkpoints.retained 2 NN的editlog文件不会保留所有的,至于保留的个数还是周期,解决中。。。
