
目标
- 整理副本放置策略
- 整理读写流程
- 整理pid文件
- 整理hdfs dfs 常用命令
- 整理多节点,单节点的磁盘均衡
- 整理安全模式
副本放置策略
副本存放策略存在新旧两个版本
具体可参考我的另一个博客:https://yerias.github.io/2018/10/11/DataWarehouse/hadoop/5/
hadoop2.7.6之前的副本存放策略
- 副本一:同机架的不同节点
- 副本二:同机架的另一节点
- 副本三:不同机架的另一节点
- 其他副本:随机挑选
hadoop2.8.4之后的副本存放策略
- 副本一:同Client的节点上
- 副本二:不同机架中的节点上
- 副本三:同第二个副本的机架中的另一个节点上
- 其他副本:随机挑选
副本存放策略优点
- 提高系统的可靠性
- 提供负载均衡
- 提高访问效率
读写流程
读取流程(FSData InputStream)
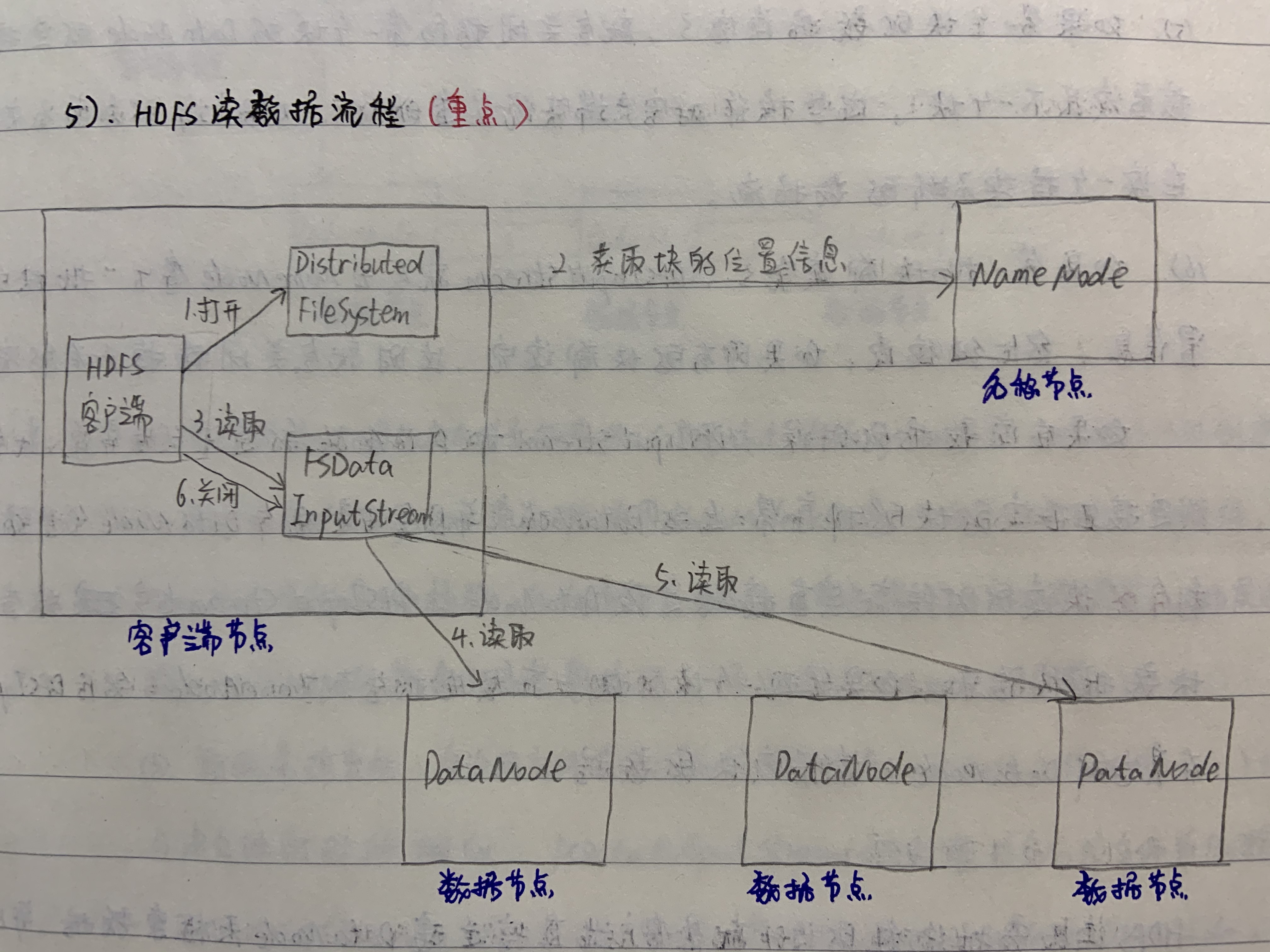
- 首先调用FileSystem对象的open()方法,获得一个分布式文件系统(DistributedFileSystem)的实例。
- 分布式文件系统(DistributedFileSystem)通过RPC获得文件的第一批块(Block)的位置信息,同一个块按照副本数会返回多个位置信息,这些位置信息按照Hadoop拓扑结构排序,距离客户端近的排在前面。
- 前两步会返回一个文件系统数据输入流(FSDataInputStream)对象,该对象会被封装为分布式文件系统输入流(DFSInputStream)对象,DFSInputStream可以方便地管理DataNode和NameNode的数据流。客户端调用read方法,DFSInputStream会找出离客户端最近的DataNode并连接。
- 数据从DataNode源源不断地流向客户端
- 如果第一个块的数据读完了,就会管理指向第一个块的DataNode的连接,接着读取下一个块。这些操作对客户端来说是透明的,从客户端的角度看来只是在读一个持续不断的数据流。
- 如果第一批块都读取完了,DFSInputStream就会去NameNode拿下一批块的位置信息,然后继续读,如果所有的块都读完了,这时就会关闭掉所有的流。
注意: 如果在读数据的时候,DFSInputStream和DataNode的通信发生异常,就会尝试连接正在读的块的排序第二近的DataNode,并且会记录哪个DataNode发生错误,剩余的块读的时候就会直接跳过该DataNode。DFSInputStream也会检查块的校验和,如果发现一个坏的块,就会先报告到NameNode,然后DFSIputStream在其它的DataNode上读取该块的数据。
写入流程(FSData OutputStream)
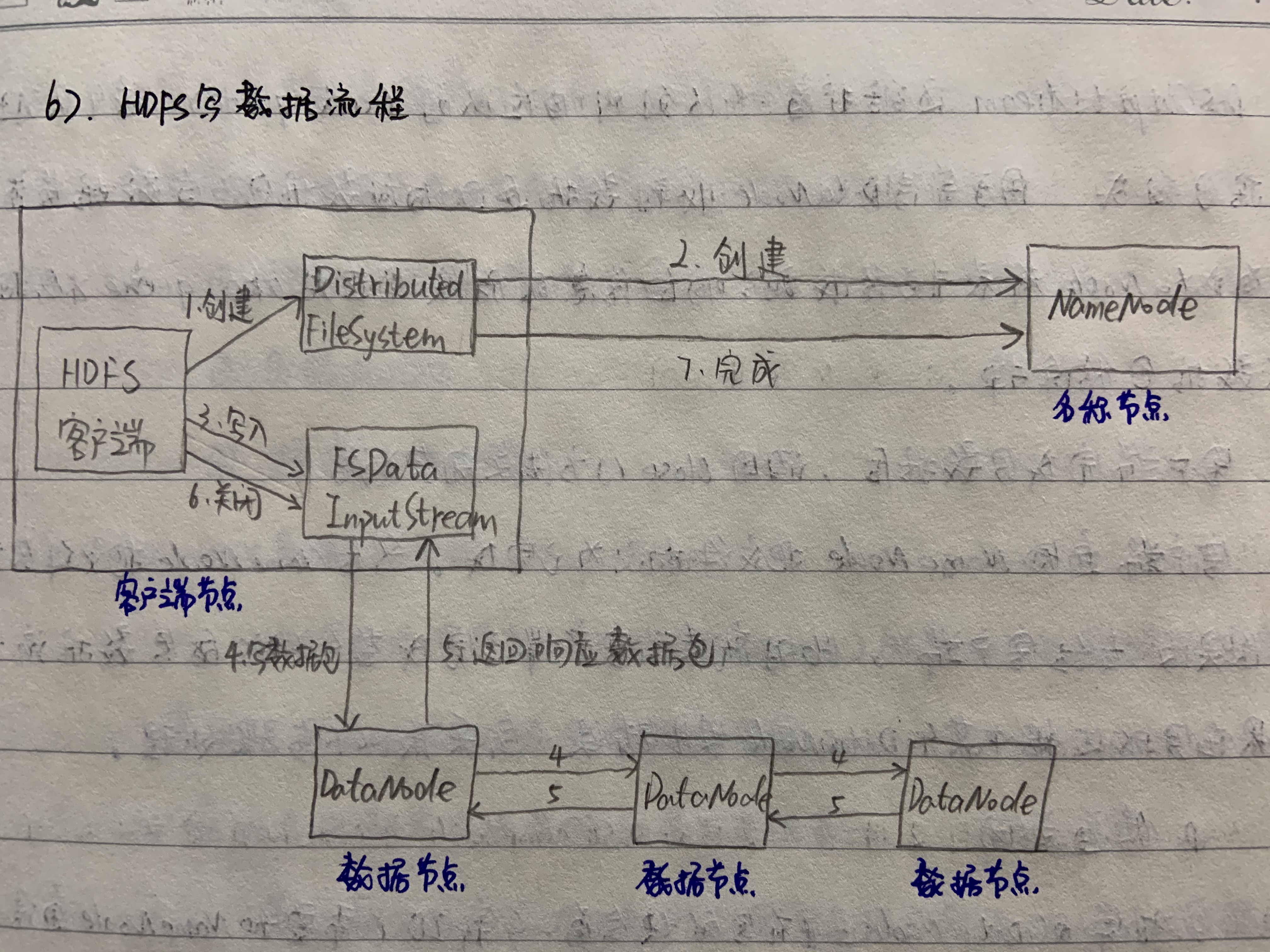
- 客户端在同过调用分布式文件系统(DistributedFileSystem)的create()方法创建新文件
- DistributedFileSystem通过RPC调用NameNode去创建一个没有块关联的新文件,创建前NameNode会做各种校验,比如文件是否存在,客户端有没有权限等。如果通过校验,NameNode就会记录下新文件,否则就会抛出I/O异常。
- 前两步结合,会返回文件系统数据输出流(FSDataOutputStream)的对象,与读文件的时候相似,DistributedFileSystem被封装成分布式文件系统的输出流(DFSOutputStream)。DFSOutputStream可以协调NameNode和DataNode的通信。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切分成一个个的数据包(packet),然后排成数据队列(data quenc)
- 接下来,数据队列中的数据包首先输出到数据管道(多个datanode节点组成数据管道)中的第一个DataNode(写数据包),第一个DataNode又把数据包输出到第二个DataNode中,依次类推。
- DFSOutputStream还维护着一个队列叫做确认队列(ack quenc),这个队列也是由数据包组成,用于等待DataNode收到数据返回确认数据包,当数据管道中的所有DataNode都表示已经收到了确认信息的时候,这时ack quenc才会把对应的数据包移除掉。
- 客户端完成写数据后,调用close()方法关闭写入数据流。
- 客户端通知NameNode把文件标记为已完成。然后NameNode把文件写成功的结果反馈给客户端。此时就表示客户端已完成整个HDFS的写数据流程。
如果写数据的过程中某个DataNode发生错误,会采取以下的步骤处理。
- 管道关闭
- 正常的DataNode上正在写的块会有一个新ID(需要和NameNode通信),而失败的DataNode上的那个不完整的块会在上报心跳的时候被删除。
- 失败的DataNode会被移除出数据管道,块中剩余的数据包继续写入管道中的其他两个DataNode。
- NameNode会标记这个块的副本个数少于指定值,块的副本会稍后在另一个DataNode创建。
- 有些时候多个DataNode会失败,只要
dfs.replication.min(缺省是1个)属性定义的指定个数的DataNode写入数据成功了,整个写入过程就算成功,缺少的副本会进行异步的恢复。
注意: 只有调用sync()方法,客户端才确保该文件的写操作已经全部完成, 当客户端调用close()方法时,会默认调用sync()方法。
pid文件
pid文件具体作用请参考我的另外一个博客:https://yerias.github.io/2018/10/12/DataWarehouse/hadoop/6/
在这里我们只简单说一下修改pid文件的生成目录的步骤,在修改hadoop文件的时候,hadoop最好是stop状态,否则需要kill进程。
创建/home/hadoop/tmp目录
mkdir /home/hadoop/tmp
修改/home/hadoop/tmp的权限
chmod -R 777 /hadoop/hadoop/tmp
修改hadoop-env.sh文件
export HADOOP_PID_DIR=/home/hadoop/tmp
修改yarn-env.sh
export YARN_PID_DIR=/home/hadoop/tmp
hdfs dfs 常用命令
[-cat [-ignoreCrc] <src> ...] |
这些命令很点单,和linux的作用一样,这里不做演示。。。
回收站
回收站的作用是把hdfs上删除的文件保存一定的时间然后自动删除,Apache是默认关闭的,CDH默认是开启的。
Apache的参数是由core-default.xml文件控制的fs.trash.interval属性
| KEY | VALUE | DESC |
|---|---|---|
| fs.trash.interval | 0 | 检查点被删除的分钟数。如果为零,则禁用垃圾特性。单位秒 |
一般在生产环境下设置保存7天
[root@aliyun hadoop]# vim core-site.xml |
注意: 切记检查生产环境是否开启回收站,开了回收站,慎用 -skipTrash
安全模式
安全模式是hadoop的一种保护机制,安全模式下不能进行修改文件的操作,但是可以浏览目录结构、查看文件内容的。
如果NN的log显示Name node is in safe mode ,正常手动让其离开安全模式,这种操作很少做。
一般进入safemode情况有:
1. 启动或者重新启动hdfs时 |
2. HDFS维护升级时
3. 块文件损坏等。。。可以使用fsck检查一下HDFS的健康度,然后进行下一步操作
hdfs fsck / : 用这个命令可以检查整个文件系统的健康状况,但是要注意它不会主动恢复备份缺失的block,这个是由NameNode单独的线程异步处理的
fsck相关介绍:
hdfs fsck |
一般我们会查看 / 目录下的损坏文件,然后根据损坏文件的路径手动进行hdfs debug修复
hdfs fsck / -list-corruptfileblocks |
多节点的磁盘均衡
由于集群中的一些服务器如CPU、磁盘、网络的差异,副本存放并不会一直保持均衡,这就造成某一些服务器的磁盘占用率达到90%,而另外一些服务器的磁盘占用率只有60%或者80%。所以就有必要手动进行均衡操作,事实上hadoop的sbin目录下也有这个命令
-rwxr-xr-x 1 hadoop hadoop 1128 Jun 3 2019 start-balancer.sh #开始 |
那么集群中的磁盘占用率怎么才算正常?这个由参数threshold控制,默认threshold=10,即各个服务器保持所有服务器的磁盘占用空间的平均值上下浮动10%,可能不好理解,我们用上面的占用率90%、60%和80%算一下。
这三台的平均占用率是:
(90+60+80)/3=76% |
那么threshold参数就控制这三台其中的任意一台的磁盘占用率不得超过86%,不得低于66%。
那么怎么做呢?
在进行磁盘均衡之前,我们需要重新设置一下balancer的带宽限制,在hdfs-default.xml文件中的dfs.datanode.balance.bandwidthPerSec属性,默认是10M,生产环境下一般设置为30M
| KEY | VALUE | DESC |
|---|---|---|
| dfs.datanode.balance.bandwidthPerSec | 10m | 指定每个datanode可用于平衡目的的最大带宽(以每秒字节数为单位)。 |
在hadoop的hdfs-site.xml文件中覆盖一下
[root@aliyun hadoop]# vim hdfs-site.xml |
怎么做?
写个shell脚本,每天凌晨执行./start-balancer.sh调度一次,达到数据平衡,毛刺修正,调度执行完成自动关闭,不需要执行./stop-balancer.sh手段关闭,除非特殊情况。
单节点的磁盘均衡
在官网中的描述:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSDiskbalancer.html
在官网中的描述中有这么一句: dfs.disk.balancer.enabled must be set to true in hdfs-site.xml.
翻译过来就是: 必须在hdfs-site.xml中将dfs.disk.balancer.enabled设置为true。
这是因为默认情况下,群集上未启用磁盘平衡器
那么我们先去设置一下
[root@aliyun hadoop]# vim hdfs-site.xml |
场景:
假如我们现在有三个数据盘
/data01 90% |
现在磁盘用的差不多了,准备加入一个盘/data04 0%
我们这时候是不是要进行单节点服务器的磁盘均衡?
怎么做?
生成hadoop001.plan.json
hdfs diskbalancer -plan hadoop001 #hadoop001是datanode的主机名
执行
hdfs diskbalancer -execute hadoop001.plan.json #hadoop001是datanode的主机名
查询状态
hdfs diskbalancer -query ruozedata001 #hadoop001是datanode的主机名
什么时候手动或调度执行?
- 新盘加入
- 监控服务器的磁盘剩余空间小于阈值10%,发邮件预警 ,手动执行
怎么在DataNode中挂载磁盘?
由hdfs-default.xml文件的dfs.datanode.data.dir属性控制
| KEY | VALUE | DESC |
|---|---|---|
| dfs.datanode.data.dir | file://${hadoop.tmp.dir}/dfs/data | 确定DFS数据节点应该将其块存储在本地文件系统的何处。多个目录使用逗号分隔。 |
假如我们现在有/data01,/data02,/data03,/data04四个目录需要挂载在该DataNode节点中
修改hdfs-site.xml文件
[root@aliyun hadoop]# vim hdfs-site.xml |
为什么DN的生产上要挂载多个物理的磁盘目录,而不是做一个raid(磁盘阵列)
为了高效率写 高效率读
注意: 提前规划好2-3年存储量 ,避免后期加磁盘维护的工作量