
目标
- 整理 mr on yarn流程
- 整理 文件格式有哪些 优缺点
- 整理 压缩格式有哪些 优缺点
- spilt–>map task关系
- wordcount的剖解图
- shuffle的理解
mr on yarn流程
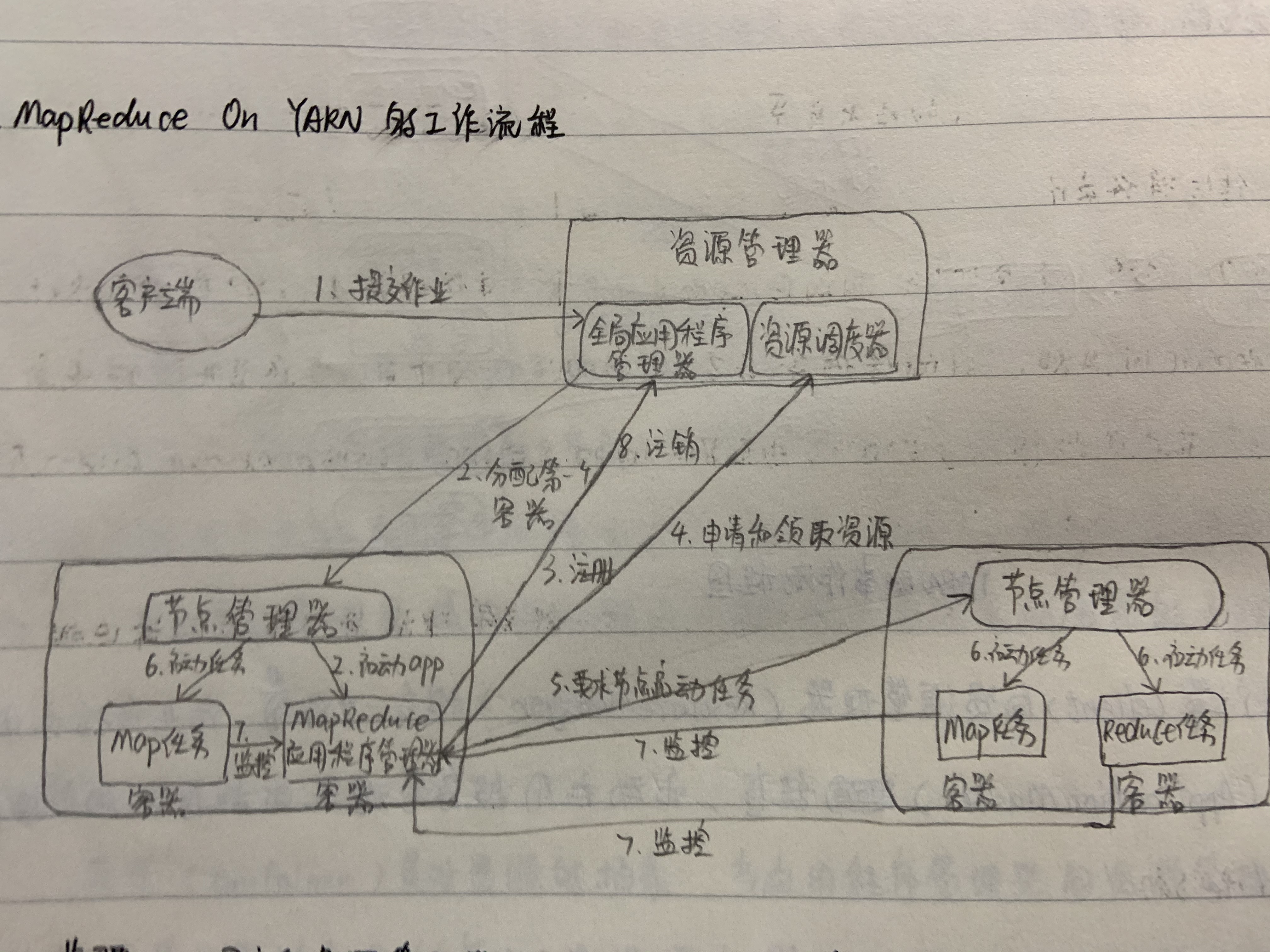
mr on yarn的工作流程简略分为两步:
- 启动应用程序管理器,申请资源。
- 运行任务,直到任务运行完成。
mr on yarn的工作流程详细分为八步:
- 用户向资源管理器(ResourceManager)提交作业,作业包括MapReduce应用程序管理器,启动MapReduce应用程序管理器的程序和用户自己编写的MapReduce程序。用于提交的所有作业都由ApplicationManager(全局应用程序管理器)管理。
- 资源管理器为该应用程序分配一个容器(Container),并与对应的节点管理器(NodeManager)通信,要求它在这个容器中启动MapReduce应用程序管理器。
- MapReduce应用程序管理器首先向资源管理器注册,这样用户可以直接通过资源管理器查看应用程序的运行状态,然后它将为各个任务申请资源,并监控他们的运行状态,直到运行结束,即重复步骤4-7。
- MapReduce应用程序管理器采用轮询的方式通过RPC协议向资源管理器申请和领取资源。
- MapReduce应用程序管理器申请到资源后,便与对应的节点管理器通信,要求启动任务。
- 节点管理器为任务设置好运行环境,包括环境变量、Jar包、二进制程序等,然后将任务启动命令写到另外一个脚本中,并通过该脚本启动任务。
- 各个任务通过RPC协议向MapReduce应用程序管理器汇报自己的状态和进度,MapReduce应用程序随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可以随时通过RPC协议向MapReduce应用程序管理器查询应用程序当前的运行状态。
- 应用程序运行完成后,MapReduce应用程序管理器向资源管理器注销并关闭自己。
文件格式有哪些 优缺点
Hadoop中的文件格式大致上分为面向行和面向列两类:
面向行:同一行的数据存储在一起,即连续存储。SequenceFile,MapFile,Avro Datafile。采用这种方式,如果只需要访问行的一小部分数据,亦需要将整行读入内存,推迟序列化一定程度上可以缓解这个问题,但是从磁盘读取整行数据的开销却无法避免。面向行的存储适合于整行数据需要同时处理的情况。
面向列:整个文件被切割为若干列数据,每一列数据一起存储。Parquet , RCFile,ORCFile。面向列的格式使得读取数据时,可以跳过不需要的列,适合于只处于行的一小部分字段的情况。但是这种格式的读写需要更多的内存空间,因为需要缓存行在内存中(为了获取多行中的某一列)。同时不适合流式写入,因为一旦写入失败,当前文件无法恢复,而面向行的数据在写入失败时可以重新同步到最后一个同步点,所以Flume采用的是面向行的存储格式。


下面介绍几种相关的文件格式,它们在Hadoop体系上被广泛使用:
SequenceFile
SequenceFile是Hadoop API 提供的一种二进制文件,它将数据以的形式序列化到文件中。这种二进制文件内部使用Hadoop 的标准的Writable 接口实现序列化和反序列化。它与Hadoop API中的MapFile 是互相兼容的。Hive 中的SequenceFile 继承自Hadoop API 的SequenceFile,不过它的key为空,使用value 存放实际的值, 这样是为了避免MR 在运行map 阶段的排序过程。如果你用Java API 编写SequenceFile,并让Hive 读取的话,请确保使用value字段存放数据,否则你需要自定义读取这种SequenceFile 的InputFormat class 和OutputFormat class。
SequenceFile的文件结构如下:

根据是否压缩,以及采用记录压缩还是块压缩,存储格式有所不同:
不压缩:
按照记录长度、Key长度、Value程度、Key值、Value值依次存储。长度是指字节数。采用指定的Serialization进行序列化。
Record压缩:
只有value被压缩,压缩的codec保存在Header中。
Block压缩:
多条记录被压缩在一起,可以利用记录之间的相似性,更节省空间。Block前后都加入了同步标识。Block的最小值由io.seqfile.compress.blocksize属性设置。

Avro
Avro是一种用于支持数据密集型的二进制文件格式。它的文件格式更为紧凑,若要读取大量数据时,Avro能够提供更好的序列化和反序列化性能。并 且Avro数据文件天生是带Schema定义的,所以它不需要开发者在API 级别实现自己的Writable对象。最近多个Hadoop 子项目都支持Avro 数据格式,如Pig 、Hive、Flume、Sqoop和Hcatalog。
RCFile
RCFile是Hive推出的一种专门面向列的数据格式。 它遵循“先按列划分,再垂直划分”的设计理念。当查询过程中,针对它并不关心的列时,它会在IO上跳过这些列。需要说明的是,RCFile在map阶段从 远端拷贝仍然是拷贝整个数据块,并且拷贝到本地目录后RCFile并不是真正直接跳过不需要的列,并跳到需要读取的列, 而是通过扫描每一个row group的头部定义来实现的,但是在整个HDFS Block 级别的头部并没有定义每个列从哪个row group起始到哪个row group结束。所以在读取所有列的情况下,RCFile的性能反而没有SequenceFile高。
Hive的Record Columnar File,这种类型的文件先将数据按行划分成Row Group,在Row Group内部,再将数据按列划分存储。其结构如下:

相比较于单纯地面向行和面向列:


ORC
ORC(Optimized Record Columnar File)提供了一种比RCFile更加高效的文件格式。其内部将数据划分为默认大小为250M的Stripe。每个Stripe包括索引、数据和Footer。索引存储每一列的最大最小值,以及列中每一行的位置。

在Hive中,如下命令用于使用ORCFile:
CREATE TABLE ... STORED AS ORC |
Parquet
一种通用的面向列的存储格式,基于Google的Dremel。特别擅长处理深度嵌套的数据。

对于嵌套结构,Parquet将其转换为平面的列存储,嵌套结构通过Repeat Level和Definition Level来表示(R和D),在读取数据重构整条记录的时候,使用元数据重构记录的结构。下面是R和D的一个例子:
AddressBook { |

文件存储大小比较与分析
我们选取一个TPC-H标准测试来说明不同的文件格式在存储上的开销。因为此数据是公开的,所以读者如果对此结果感兴趣,也可以对照后面的实验自行 做一遍。Orders 表文本格式的原始大小为1.62G。 我们将其装载进Hadoop 并使用Hive 将其转化成以上几种格式,在同一种LZO 压缩模式下测试形成的文件的大小

不同格式文件大小对比
从上述实验结果可以看到,SequenceFile无论在压缩和非压缩的情况下都比原始纯文本TextFile大,其中非压缩模式下大11%, 压缩模式下大6.4%。这跟SequenceFile的文件格式的定义有关: SequenceFile在文件头中定义了其元数据,元数据的大小会根据压缩模式的不同略有不同。一般情况下,压缩都是选取block 级别进行的,每一个block都包含key的长度和value的长度,另外每4K字节会有一个sync-marker的标记。对于TextFile文件格 式来说不同列之间只需要用一个行间隔符来切分,所以TextFile文件格式比SequenceFile文件格式要小。但是TextFile 文件格式不定义列的长度,所以它必须逐个字符判断每个字符是不是分隔符和行结束符。因此TextFile 的反序列化开销会比其他二进制的文件格式高几十倍以上。
RCFile文件格式同样也会保存每个列的每个字段的长度。但是它是连续储存在头部元数据块中,它储存实际数据值也是连续的。另外RCFile 会每隔一定块大小重写一次头部的元数据块(称为row group,由hive.io.rcfile.record.buffer.size控制,其默认大小为4M),这种做法对于新出现的列是必须的,但是如 果是重复的列则不需要。RCFile 本来应该会比SequenceFile 文件大,但是RCFile 在定义头部时对于字段长度使用了Run Length Encoding进行压缩,所以RCFile 比SequenceFile又小一些。Run length Encoding针对固定长度的数据格式有非常高的压缩效率,比如Integer、Double和Long等占固定长度的数据类型。在此提一个特例—— Hive 0.8引入的TimeStamp 时间类型,如果其格式不包括毫秒,可表示为”YYYY-MM-DD HH:MM:SS”,那么就是固定长度占8个字节。如果带毫秒,则表示为”YYYY-MM-DD HH:MM:SS.fffffffff”,后面毫秒的部分则是可变的。
Avro文件格式也按group进行划分。但是它会在头部定义整个数据的模式(Schema), 而不像RCFile那样每隔一个row group就定义列的类型,并且重复多次。另外,Avro在使用部分类型的时候会使用更小的数据类型,比如Short或者Byte类型,所以Avro的数 据块比RCFile 的文件格式块更小。
压缩格式有哪些 优缺点
压缩的好处和坏处
好处
- 减少存储磁盘空间
- 降低IO(网络的IO和磁盘的IO)
- 加快数据在磁盘和网络中的传输速度,从而提高系统的处理速度
坏处
- 由于使用数据时,需要先将数据解压,加重CPU负荷
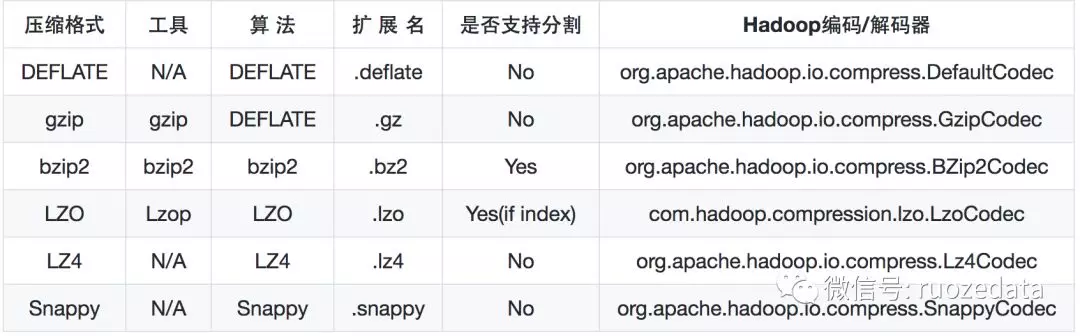
压缩格式
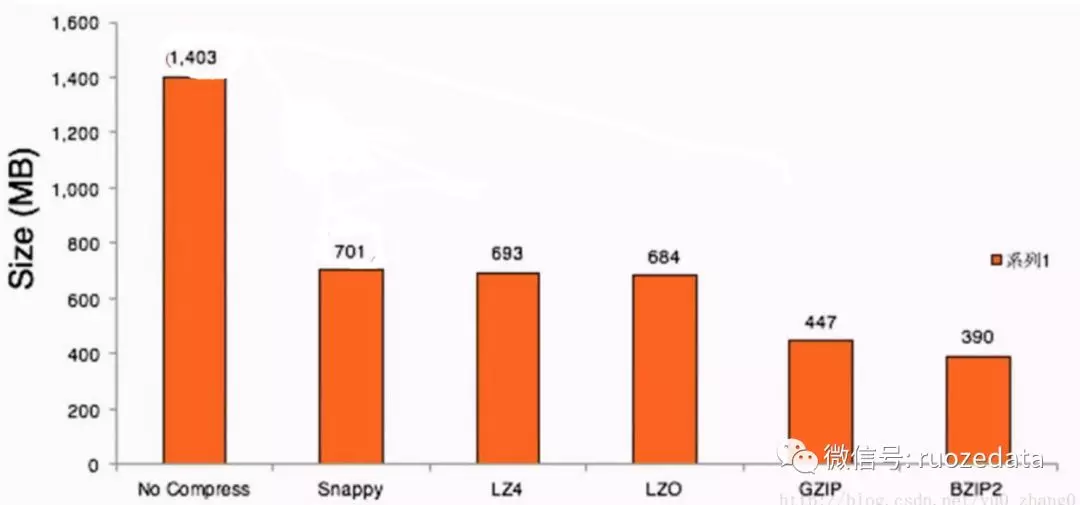
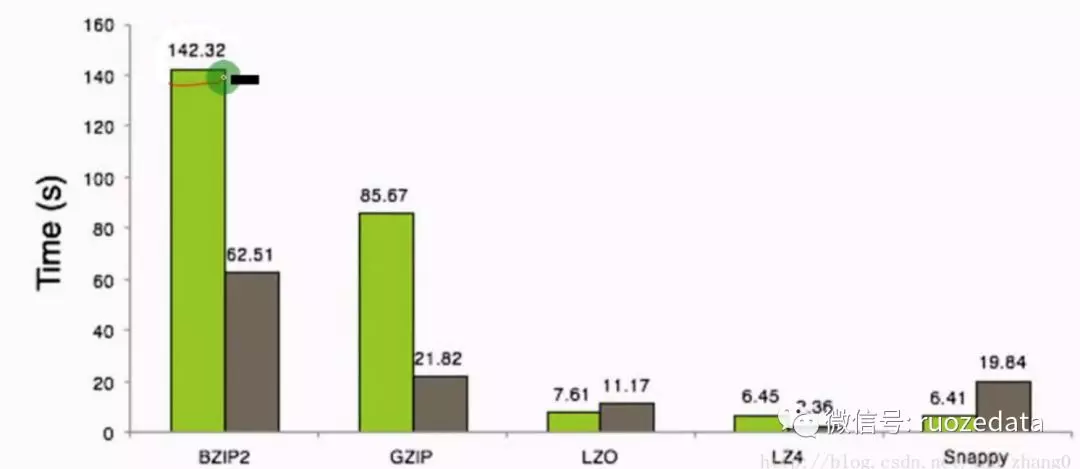
可以看出,压缩空间比值越高,压缩时间越长,压缩比:Snappy>LZ4>LZO>GZIP>BZIP2
| 压缩格式 | 优点 | 缺点 | |
|---|---|---|---|
| gzip | 压缩比在四种压缩方式中较高;hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;有hadoop native库;大部分linux系统都自带gzip命令,使用方便 | 不支持split | |
| lzo | 压缩/解压速度也比较快,合理的压缩率;支持split,是hadoop中最流行的压缩格式;支持hadoop native库;需要在linux系统下自行安装lzop命令,使用方便 | 压缩率比gzip要低;hadoop本身不支持,需要安装;lzo虽然支持split,但需要对lzo文件建索引,否则hadoop也是会把lzo文件看成一个普通文件(为了支持split需要建索引,需要指定inputformat为lzo格式) | |
| snappy | 压缩速度快;支持hadoop native库 | 不支持split;压缩比低;hadoop本身不支持,需要安装;linux系统下没有对应的命令d. bzip2 | |
| bzip2 | 支持split;具有很高的压缩率,比gzip压缩率都高;hadoop本身支持,但不支持native;在linux系统下自带bzip2命令,使用方便 | 压缩/解压速度慢;不支持native |
总结
不同的场景选择不同的压缩方式,肯定没有一个一劳永逸的方法,如果选择高压缩比,那么对于cpu的性能要求要高,同时压缩、解压时间耗费也多;选择压缩比低的,对于磁盘io、网络io的时间要多,空间占据要多;对于支持分割的,可以实现并行处理。
应用场景
一般在HDFS 、Hive、HBase中会使用;
当然一般较多的是结合Spark 来一起使用。
Spilt–>Map Task关系
Reduce Task默认是1个,Map Task默认是2个,但是实际运行场景下,Map Task的个数和切片的个数保持一致,而切片的个数又与文件数和文件大小相关联。切片默认大小决定文件被分成多少个切片,执行多少个Map Task。
| KEY | VALUE | DESC |
|---|---|---|
| mapreduce.job.maps | 2 | The default number of map tasks per job. |
| mapreduce.job.reduces | 1 | The default number of reduce tasks per job. |
shuffle的理解
俩字: 洗牌
shuffle阶段又可以分为Map端的shuff和reduce端的shuffle

map端的shuffle
- map端会处理出入数据并产生中间结果,这个中间结果会写到本地磁盘,而不是HDFS。每个map的输出会先写到内存缓冲区中,当写入的数据达到设定的阈值时,系统将会启动一个线程将缓冲区的数据写到磁盘,这个过程叫做spill(溢写)。
- 在spill之前,会先进行两次排序,首先根据数据所属的partition进行排序,然后每个partition中的数据再按key来排序,partition的目的是将记录划分到不同的reduce上,以期望能达到负载均衡,以后的reduce就会根据partition来读取自己对应的数据。接着运行combiner(如果设置了的话),combiner的本质也是一个reduce,其目的是对将要写入到磁盘的文件先进行一次处理,这样,写入到磁盘的数据量就会减少。最后将数据写到本地磁盘产生spill文件(spill文件保存在{mapred.local.dir}指定的目录中,map任务结束后就会被删除)。
- 最后,每个map任务可能产生多个spill文件,在每个map任务完成前,会通过多路归并算法将这些spill文件合并成一个文件。至此,map的shuffle过程就结束了。
reduce端的shuffle
- reduce端的shuffle主要包括三个阶段,copy、sort(merge)和reduce
- 首先将map端产生的输出文件拷贝到reduce端,但每个reduce如何知道自己应该处理哪些数据呢?因为map端进行partition的时候,实际上就相当于指定了每个reduce要处理的数据(partition就对应了reduce),所以reduce在拷贝的数据的时候只需拷贝与自己对应的partition中的数据即可。每个reduce会处理一个或多个partiton,但需要先将自己对应的partition中的数据从每个map的输出结果中拷贝出来。
- 接下来就是sort阶段,也称为merge阶段,因为这个阶段的主要工作是执行了归并排序。从map端拷贝到reduce端的数据都是有序的,所以很适合归并排序。最终在reduce端生产一个较大的文件作为reduce的输入。
- 最后就是reduce阶段了,在这个过程中产生最终的输出结果,并将其写到HDFS上。
WordCount的剖解图

Map任务处理
- 读取HDFS中的文件,每一行解析成一个<K,V>值。每个键值对调用一次map函数。
- 重写map()方法,接收1产生的<K,V>值进行处理,转为新的<K,V>输出。
- 对2输出的<K,V>值进行分区,默认一盒分区。
- 对不同分区中的数据进行排序(按照K)、分组。分组指的是相同Key的Value放到一个集合中。
- (可选)对分组后的数据进行合并。
Reduce任务处理
- 多个Map任务的输出,按照不同的分区,通过网络copy到不同的Reduce节点上。
- 对多个map的输出进行合并、排序。重写reduce()方法,接收的是分组后的数据,实现自己的业务逻辑,处理后产生新的<K,V>值输出
- 对reduce输出的<K,V>写到HDFS中。
整理来自:https://ruozedata.github.io/2018/04/18/、https://www.jianshu.com/p/43630456a18a