
目录
- 什么是压缩
- 压缩的好处与坏处
- 常见的压缩格式
- 优缺点比较
- 如何选择压缩格式
- MR配置文件压缩格式
- Hive配置文件压缩格式
什么是压缩
压缩就是通过某种技术(算法)把原始文件变小,相应的解压就是把压缩后的文件变成原始文件。嘿嘿是不是又可以变大又可以变小。
压缩的好处与坏处
好处
- 减少存储磁盘空间
- 降低IO(网络的IO和磁盘的IO)
- 加快数据在磁盘和网络中的传输速度,从而提高系统的处理速度
坏处
- 由于使用数据时,需要先将数据解压,加重CPU负荷
常见的压缩格式
| 格式 | 可分割 | 平均压缩速度 | 文本文件压缩效率 | Hadoop压缩编解码器 | 纯Java实现 | 原生 | 备注 |
|---|---|---|---|---|---|---|---|
| gzip | 否 | 快 | 高 | org.apache.hadoop.io.compress.GzipCodec | 是 | 是 | |
| lzo | 是(取决于所使用的库) | 非常快 | 中等 | com.hadoop.compression.lzo.LzoCodec | 是 | 是 | 需要在每个节点上安装LZO |
| bzip2 | 是 | 慢 | 非常高 | org.apache.hadoop.io.compress.Bzip2Codec | 是 | 是 | 为可分割版本使用纯Java |
| zlib | 否 | 慢 | 中等 | org.apache.hadoop.io.compress.DefaultCodec | 是 | 是 | Hadoop 的默认压缩编解码器 |
| Snappy | 否 | 非常快 | 低 | org.apache.hadoop.io.compress.SnappyCodec | 否 | 是 | Snappy 有纯Java的移植版,但是在Spark/Hadoop中不能用 |
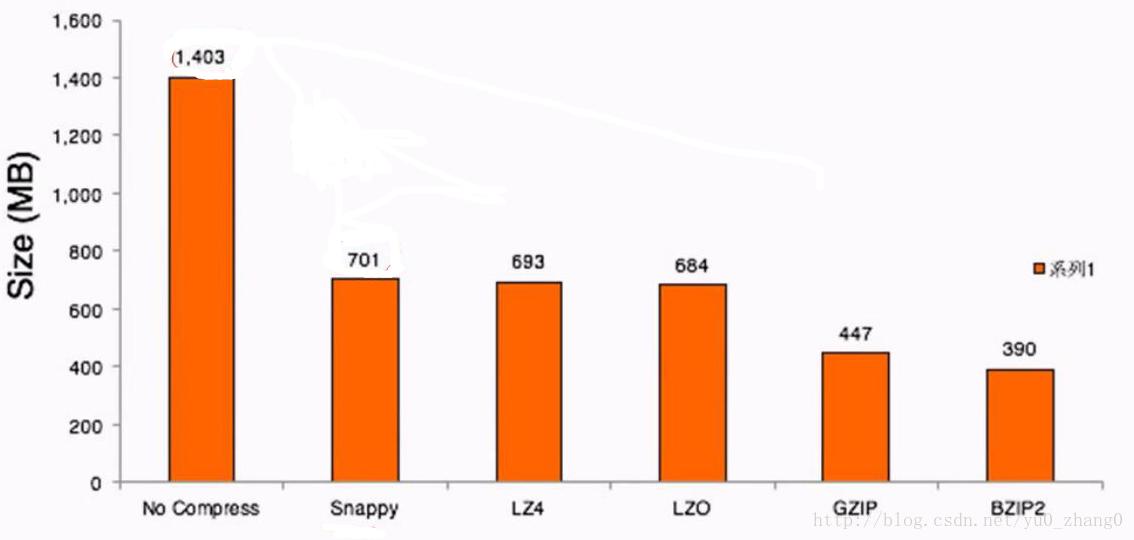
一个简单的案例对于集中压缩方式之间的压缩大小和压缩时间进行一个感观性的认识
测试环境: |
压缩比
压缩时间比
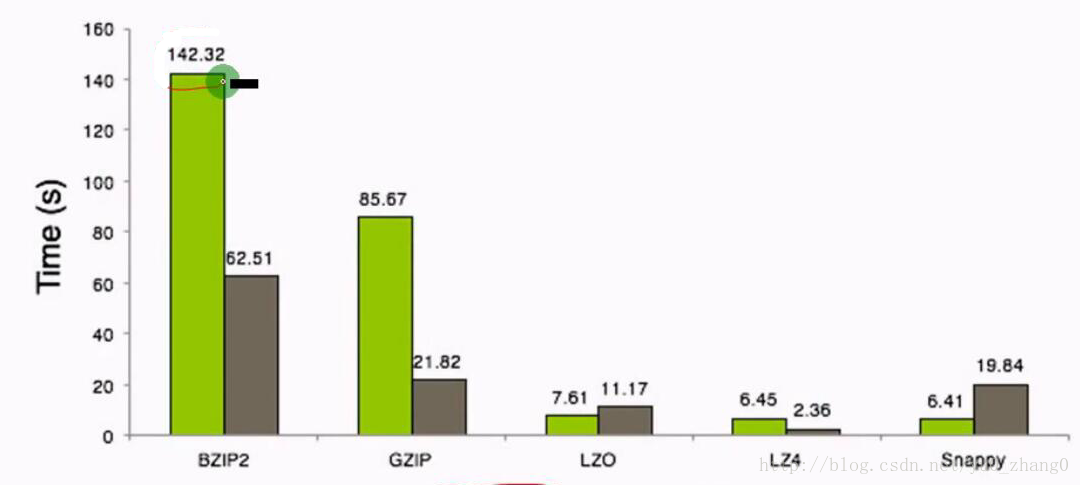
可以看出,压缩比越高,压缩时间越长
优缺点比较
| 压缩格式 | 优点 | 缺点 | |
|---|---|---|---|
| gzip | 压缩比在四种压缩方式中较高;hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;有hadoop native库;大部分linux系统都自带gzip命令,使用方便 | 不支持split | |
| lzo | 压缩/解压速度也比较快,合理的压缩率;支持split,是hadoop中最流行的压缩格式;支持hadoop native库;需要在linux系统下自行安装lzop命令,使用方便 | 压缩率比gzip要低;hadoop本身不支持,需要安装;lzo虽然支持split,但需要对lzo文件建索引,否则hadoop也是会把lzo文件看成一个普通文件(为了支持split需要建索引,需要指定inputformat为lzo格式) | |
| snappy | 压缩速度快;支持hadoop native库 | 不支持split;压缩比低;hadoop本身不支持,需要安装;linux系统下没有对应的命令 | |
| bzip2 | 支持split;具有很高的压缩率,比gzip压缩率都高;hadoop本身支持,但不支持native;在linux系统下自带bzip2命令,使用方便 | 压缩/解压速度慢;不支持native |
如何选择压缩格式
从两方面考虑:Storage + Compute;
- Storage :基于HDFS考虑,减少了存储文件所占空间,提升了数据传输速率;如gzip、bzip2。
- Compute:基于YARN上的计算(MapReduce/Hive/Spark/….)速度的提升;如lzo、lz4、snappy。
不同的场景选择不同的压缩方式,肯定没有一个一劳永逸的方法,如果选择高压缩比,那么对于cpu的性能要求要高,同时压缩、解压时间耗费也多;选择压缩比低的,对于磁盘io、网络io的时间要多,空间占据要多;对于支持分割的,可以实现并行处理。
- IO密集型:使用压缩
- 运算密集型:慎用压缩
压缩在MapReduce中的应用场景
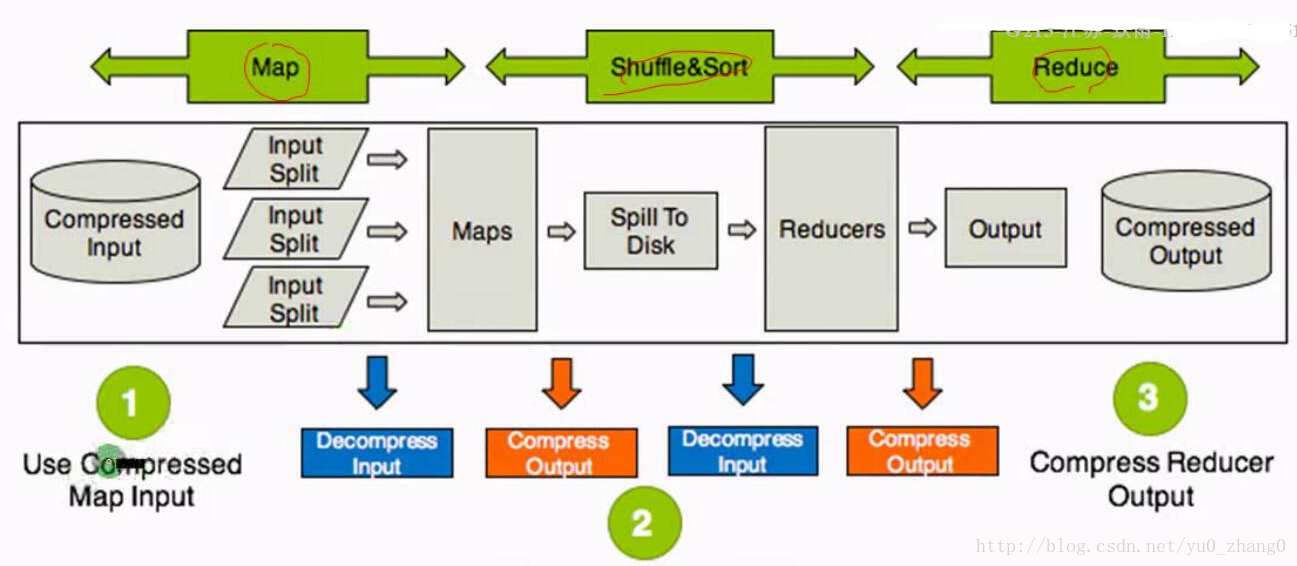
压缩在hadoop中的应用场景总结在三方面:输入,中间,输出。
整体思路:hdfs ==> map ==> shuffle ==> reduce
- Use Compressd Map Input: 从HDFS中读取文件进行Mapreuce作业,如果数据很大,可以使用压缩并且选择支持分片的压缩方式(Bzip2,LZO),可以实现并行处理,提高效率,减少磁盘读取时间,同时选择合适的存储格式例如Sequence Files,RC,ORC等;
- Compress Intermediate Data: Map输出作为Reducer的输入,需要经过shuffle这一过程,需要把数据读取到一个环形缓冲区,然后读取到本地磁盘,所以选择压缩可以减少了存储文件所占空间,提升了数据传输速率,建议使用压缩速度快的压缩方式,例如Snappy和LZO.
- Compress Reducer Output: 进行归档处理或者链式Mapreduce的工作(该作业的输出作为下个作业的输入),压缩可以减少了存储文件所占空间,提升了数据传输速率,如果作为归档处理,可以采用高的压缩比(Gzip,Bzip2),如果作为下个作业的输入,考虑是否要分片进行选择。
MR配置文件压缩格式
hadoop自带不支持split的gzip和支持split的bzip2,我们还手动安装了lzo的压缩方式
修改
core-site.xml文件<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec,
org.apache.hadoop.io.compress.Lz4Codec,
org.apache.hadoop.io.compress.SnappyCodec,
</value>
</property>修改
mapred-site.xml文件#开启支持压缩
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
#压缩方式/最终输出的压缩方式
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.BZip2Codec</value>
</property>
#中间压缩(可选,Snappy需要手动安装)
<property>
<name>mapred.map.output.compression.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>中间压缩:中间压缩就是处理作业map任务和reduce任务之间的数据,对于中间压缩,最好选择一个节省CPU耗时的压缩方式(快)
最终压缩:可以选择高压缩比,减少了存储文件所占空间,提升了数据传输速率
mapred-site.xml中设置验证,跑个wc看最终输出文件的后缀
更换压缩方式只需要修改中间输出或者最终输出的压缩类即可
Hive配置文件压缩格式
配置压缩功能
hive配置文件压缩格式只需要配置两个参数
//开启压缩功能
SET hive.exec.compress.output=true;
//设置最终以bz2格式存储
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.BZip2Code;注意:不建议再配置文件中设置
使用压缩
#创建表:
create table page_views(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
#加载数据:
load data local inpath "/home/hadoop/data/page_views.dat" overwrite into table page_views;
#配置压缩格式
hive:
SET hive.exec.compress.output=true;
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.BZip2Codec;
#创建压缩表
create table page_views_bzip2 ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" as select * from page_views;