
目录
- Hadoop 框架计算特性
- 优化常用手段
- 排序选择
- 怎样做笛卡尔积
- 怎样写 in/exists 语句
- 设置合理的 maptask 数量
- 小文件合并
- 设置合理的 reduceTask 的数量
- 合理利用分桶:Bucketing 和 Sampling
- 合理利用分区:Partition
- Join 优化
- Group By 优化
- 合理利用文件存储格式
- 本地模式执行 MapReduce
- 并行化处理
- 设置压缩存储
Hadoop 框架计算特性
数据量大不是问题,数据倾斜是个问题
jobs 数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次 汇总,产生十几个 jobs,耗时很长。原因是 map reduce 作业初始化的时间是比较长的
sum,count,max,min 等 UDAF,不怕数据倾斜问题,hadoop 在 map 端的汇总合并优化,使 数据倾斜不成问题
count(distinct userid),在数据量大的情况下,效率较低,如果是多 count(distinct userid,month)效率更低,因为 count(distinct)是按 group by 字段分组,按 distinct 字段排序, 一般这种分布方式是很倾斜的,比如 PV 数据,淘宝一天 30 亿的 pv,如果按性别分组,分 配 2 个 reduce,每个 reduce 期望处理 15 亿数据,但现实必定是男少女多
优化常用手段
好的模型设计事半功倍
解决数据倾斜问题
减少 job 数
设置合理的 MapReduce 的 task 数,能有效提升性能。(比如,10w+级别的计算,用 160个 reduce,那是相当的浪费,1 个足够)
了解数据分布,自己动手解决数据倾斜问题是个不错的选择。这是通用的算法优化,但 算法优化有时不能适应特定业务背景,开发人员了解业务,了解数据,可以通过业务逻辑精确有效的解决数据倾斜问题
数据量较大的情况下,慎用 count(distinct),group by 容易产生倾斜问题
对小文件进行合并,是行之有效的提高调度效率的方法,假如所有的作业设置合理的文件数,对云梯的整体调度效率也会产生积极的正向影响
优化时把握整体,单个作业最优不如整体最优
排序选择
cluster by:对同一字段分桶并排序,不能和 sort by 连用
distribute by + sort by:分桶,保证同一字段值只存在一个结果文件当中,结合 sort by 保证 每个 reduceTask 结果有序
sort by:单机排序,单个 reduce 结果有序
order by:全局排序,缺陷是只能使用一个 reduce
一定要区分这四种排序的使用方式和适用场景
怎样做笛卡尔积
当 Hive 设定为严格模式(hive.mapred.mode=strict)时,不允许在 HQL 语句中出现笛卡尔积, 这实际说明了 Hive 对笛卡尔积支持较弱。因为找不到 Join key,Hive 只能使用 1 个 reducer 来完成笛卡尔积。
当然也可以使用 limit 的办法来减少某个表参与 join 的数据量,但对于需要笛卡尔积语义的 需求来说,经常是一个大表和一个小表的 Join 操作,结果仍然很大(以至于无法用单机处 理),这时 MapJoin才是最好的解决办法。MapJoin,顾名思义,会在 Map 端完成 Join 操作。 这需要将 Join 操作的一个或多个表完全读入内存。
PS:MapJoin 在子查询中可能出现未知 BUG。在大表和小表做笛卡尔积时,规避笛卡尔积的 方法是,给 Join 添加一个 Join key,原理很简单:将小表扩充一列 join key,并将小表的条目复制数倍,join key 各不相同;将大表扩充一列 join key 为随机数。
精髓就在于复制几倍,最后就有几个 reduce 来做,而且大表的数据是前面小表扩张 key 值 范围里面随机出来的,所以复制了几倍 n,就相当于这个随机范围就有多大 n,那么相应的, 大表的数据就被随机的分为了 n 份。并且最后处理所用的 reduce 数量也是 n,而且也不会出现数据倾斜。
怎样写 in/exists 语句
虽然经过测验,hive1.2.1 也支持 in/exists 操作,但还是推荐使用 hive 的一个高效替代方案:left semi join
比如说:
select a.id, a.name from a where a.id in (select b.id from b); |
应该转换成:
select a.id, a.name from a left semi join b on a.id = b.id; |
设置合理的 maptask 数量
Map 数过大
Map 阶段输出文件太小,产生大量小文件
初始化和创建 Map 的开销很大
Map 数太小
文件处理或查询并发度小,Job 执行时间过长
大量作业时,容易堵塞集群
在 MapReduce 的编程案例中,我们得知,一个MR Job的 MapTask 数量是由输入分片 InputSplit 决定的。而输入分片是由 FileInputFormat.getSplit()决定的。一个输入分片对应一个 MapTask, 而输入分片是由三个参数决定的:

输入分片大小的计算是这么计算出来的:
long splitSize = Math.max(minSize, Math.min(maxSize, blockSize))
默认情况下,输入分片大小和 HDFS 集群默认数据块大小一致,也就是默认一个数据块,启 用一个 MapTask 进行处理,这样做的好处是避免了服务器节点之间的数据传输,提高 job 处理效率
两种经典的控制 MapTask 的个数方案:减少 MapTask 数或者增加 MapTask 数
- 减少 MapTask 数是通过合并小文件来实现,这一点主要是针对数据源
- 增加 MapTask 数可以通过控制上一个 job 的 reduceTask 个数
因为 Hive 语句最终要转换为一系列的 MapReduce Job 的,而每一个 MapReduce Job 是由一 系列的 MapTask 和 ReduceTask 组成的,默认情况下, MapReduce 中一个 MapTask 或者一个 ReduceTask 就会启动一个 JVM 进程,一个 Task 执行完毕后, JVM 进程就退出。这样如果任 务花费时间很短,又要多次启动 JVM 的情况下,JVM 的启动时间会变成一个比较大的消耗, 这个时候,就可以通过重用 JVM 来解决:
set mapred.job.reuse.jvm.num.tasks=5 |
小文件合并
文件数目过多,会给 HDFS 带来压力,并且会影响处理效率,可以通过合并 Map 和 Reduce 的 结果文件来消除这样的影响:
set hive.merge.mapfiles = true ##在 map only 的任务结束时合并小文件 |
设置合理的 reduceTask 的数量
Hadoop MapReduce 程序中,reducer 个数的设定极大影响执行效率,这使得 Hive 怎样决定 reducer 个数成为一个关键问题。遗憾的是 Hive 的估计机制很弱,不指定 reducer 个数的情 况下,Hive 会猜测确定一个 reducer 个数,基于以下两个设定:
hive.exec.reducers.bytes.per.reducer(默认为 256000000) |
计算 reducer 数的公式很简单: N=min(参数 2,总输入数据量/参数 1) 通常情况下,有必要手动指定 reducer 个数。考虑到 map 阶段的输出数据量通常会比输入有大幅减少,因此即使不设定 reducer 个数,重设参数 2 还是必要的。
依据 Hadoop 的经验,可以将参数 2 设定为 0.95*(集群中 datanode 个数)。
合并 MapReduce 操作
Multi-group by 是 Hive 的一个非常好的特性,它使得 Hive 中利用中间结果变得非常方便。 例如:
FROM (SELECT a.status, b.school, b.gender FROM status_updates a JOIN profiles b ON (a.userid = |
上述查询语句使用了 multi-group by 特性连续 group by 了 2 次数据,使用不同的 group by key。 这一特性可以减少一次 MapReduce 操作
合理利用分桶:Bucketing 和 Sampling
Bucket 是指将数据以指定列的值为 key 进行 hash,hash 到指定数目的桶中。这样就可以支 持高效采样了。如下例就是以 userid 这一列为 bucket 的依据,共设置 32 个 buckets
CREATE TABLE page_view(viewTime INT, userid BIGINT, |
通常情况下,Sampling 在全体数据上进行采样,这样效率自然就低,它要去访问所有数据。 而如果一个表已经对某一列制作了 bucket,就可以采样所有桶中指定序号的某个桶,这就 减少了访问量。
如下例所示就是采样了 page_view 中 32 个桶中的第三个桶的全部数据:
SELECT * FROM page_view TABLESAMPLE(BUCKET 3 OUT OF 32); |
如下例所示就是采样了 page_view 中 32 个桶中的第三个桶的一半数据:
SELECT * FROM page_view TABLESAMPLE(BUCKET 3 OUT OF 64); |
合理利用分区:Partition
Partition 就是分区。分区通过在创建表时启用 partitioned by 实现,用来 partition 的维度并不 是实际数据的某一列,具体分区的标志是由插入内容时给定的。当要查询某一分区的内容时 可以采用 where 语句,形似 where tablename.partition_column = a 来实现。
创建含分区的表
CREATE TABLE page_view(viewTime INT, userid BIGINT, |
载入内容,并指定分区标志
load data local inpath '/home/hadoop/pv_2008-06-08_us.txt' into table page_view |
查询指定标志的分区内容
SELECT page_views.* FROM page_views |
Join 优化
总体原则:
优先过滤后再进行 Join 操作,最大限度的减少参与 join 的数据量
小表 join 大表,最好启动 mapjoin
Join on 的条件相同的话,最好放入同一个 job,并且 join 表的排列顺序从小到大
在使用写有 Join 操作的查询语句时有一条原则:应该将条目少的表/子查询放在 Join 操作 符的左边。原因是在 Join 操作的 Reduce 阶段,位于 Join 操作符左边的表的内容会被加 载进内存,将条目少的表放在左边,可以有效减少发生 OOM 错误的几率。对于一条语句 中有多个 Join 的情况,如果 Join 的条件相同,比如查询
INSERT OVERWRITE TABLE pv_users |
如果 Join 的 key 相同,不管有多少个表,都会则会合并为一个 Map-Reduce 任务,而不 是”n”个,在做 OUTER JOIN 的时候也是一样
如果 join 的条件不相同,比如:
INSERT OVERWRITE TABLE pv_users |
Map-Reduce 的任务数目和 Join 操作的数目是对应的,上述查询和以下查询是等价的
--先 page_view 表和 user 表做链接 |
在编写 Join 查询语句时,如果确定是由于 join 出现的数据倾斜,那么请做如下设置:
set hive.skewjoin.key=100000; // 这个是 join 的键对应的记录条数超过这个值则会进行 分拆,值根据具体数据量设置 |
Group By 优化
1. Map 端部分聚合
并不是所有的聚合操作都需要在 Reduce 端完成,很多聚合操作都可以先在 Map 端进 行部分聚合,最后在Reduce 端得出最终结果。
MapReduce 的 combiner 组件参数包括:
set hive.map.aggr = true 是否在 Map 端进行聚合,默认为 True |
2. 使用 Group By 有数据倾斜的时候进行负载均衡
set hive.groupby.skewindata = true |
当 sql 语句使用 groupby 时数据出现倾斜时,如果该变量设置为 true,那么 Hive 会自动进行 负载均衡。策略就是把 MR 任务拆分成两个:第一个先做预汇总,第二个再做最终汇总
在 MR 的第一个阶段中,Map 的输出结果集合会缓存到 maptaks 中,每个 Reduce 做部分聚 合操作,并输出结果,这样处理的结果是相同 Group By Key 有可能被分发到不同的 Reduce 中, 从而达到负载均衡的目的;第二个阶段 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成 最终的聚合操作。
合理利用文件存储格式
创建表时,尽量使用 orc、parquet 这些列式存储格式,因为列式存储的表,每一列的数据在 物理上是存储在一起的,Hive 查询时会只遍历需要列数据,大大减少处理的数据量。
本地模式执行 MapReduce
Hive 在集群上查询时,默认是在集群上 N 台机器上运行, 需要多个机器进行协调运行,这 个方式很好地解决了大数据量的查询问题。但是当 Hive 查询处理的数据量比较小时,其实 没有必要启动分布式模式去执行,因为以分布式方式执行就涉及到跨网络传输、多节点协调 等,并且消耗资源。这个时间可以只使用本地模式来执行 mapreduce job,只在一台机器上 执行,速度会很快。启动本地模式涉及到三个参数:

set hive.exec.mode.local.auto=true 是打开 hive 自动判断是否启动本地模式的开关,但是只 是打开这个参数并不能保证启动本地模式,要当 map 任务数不超过 |
并行化处理
一个 hive sql 语句可能会转为多个 mapreduce Job,每一个 job 就是一个 stage,这些 job 顺序 执行,这个在 cli 的运行日志中也可以看到。但是有时候这些任务之间并不是是相互依赖的, 如果集群资源允许的话,可以让多个并不相互依赖 stage 并发执行,这样就节约了时间,提 高了执行速度,但是如果集群资源匮乏时,启用并行化反倒是会导致各个 job 相互抢占资源 而导致整体执行性能的下降。启用并行化:
set hive.exec.parallel=true; |
设置压缩存储
1. 压缩的原因
Hive 最终是转为 MapReduce 程序来执行的,而 MapReduce 的性能瓶颈在于网络 IO 和 磁盘 IO,要解决性能瓶颈,最主要的是减少数据量,对数据进行压缩是个好的方式。压缩 虽然是减少了数据量,但是压缩过程要消耗 CPU 的,但是在 Hadoop 中, 往往性能瓶颈不 在于 CPU,CPU 压力并不大,所以压缩充分利用了比较空闲的 CPU
2. 常用压缩方法对比
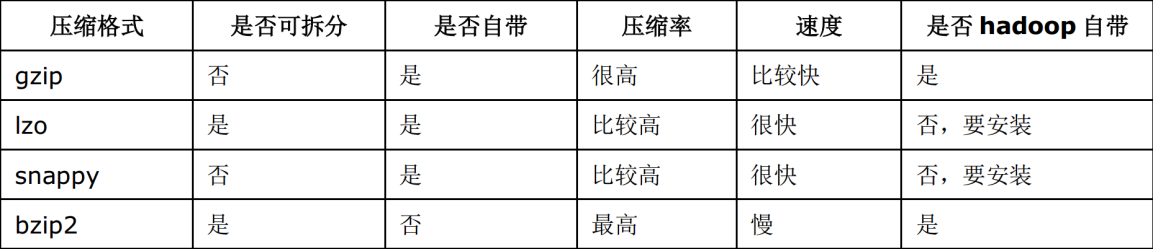
各个压缩方式所对应的 Class 类:

3. 压缩方式的选择
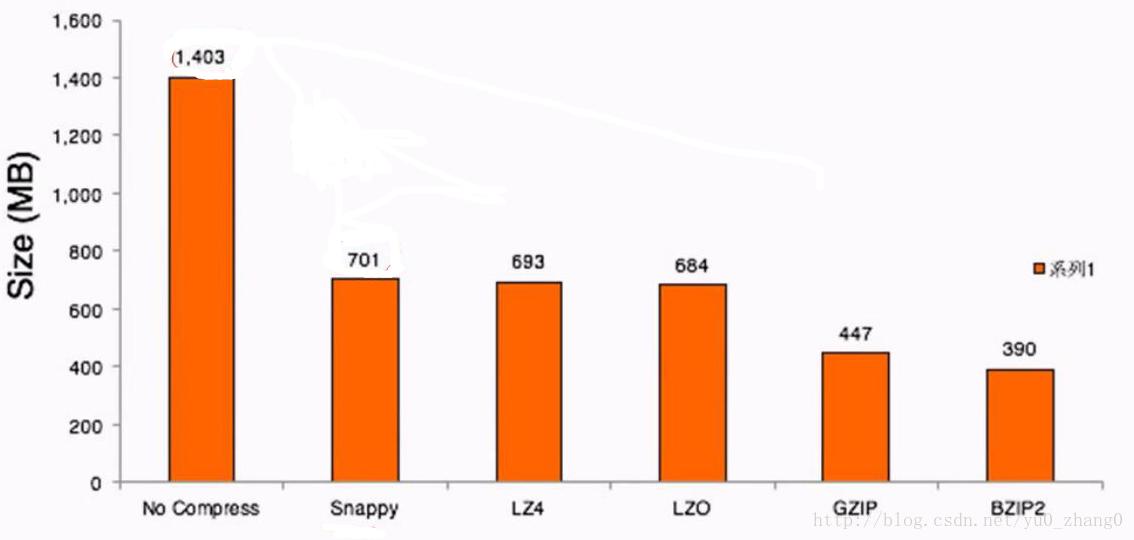
压缩比率
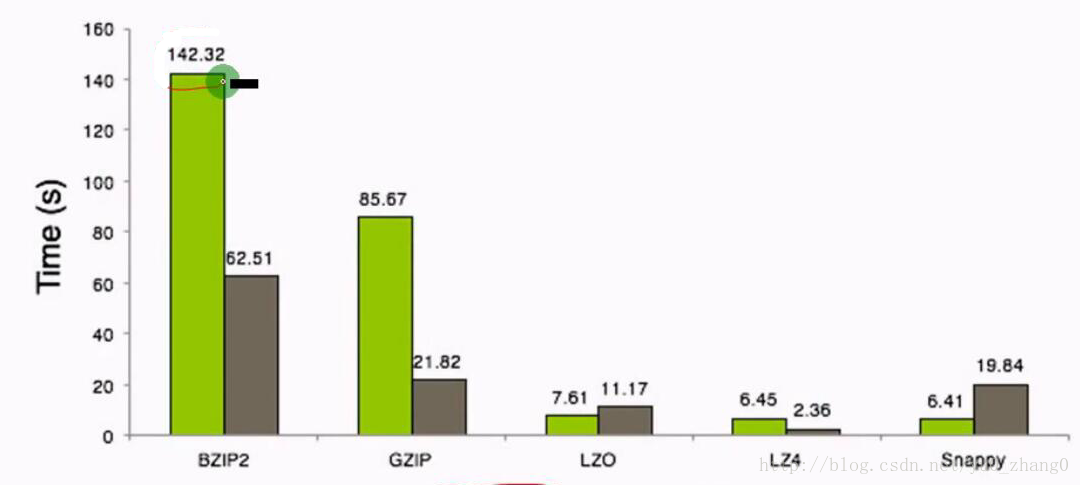
压缩解压缩速度
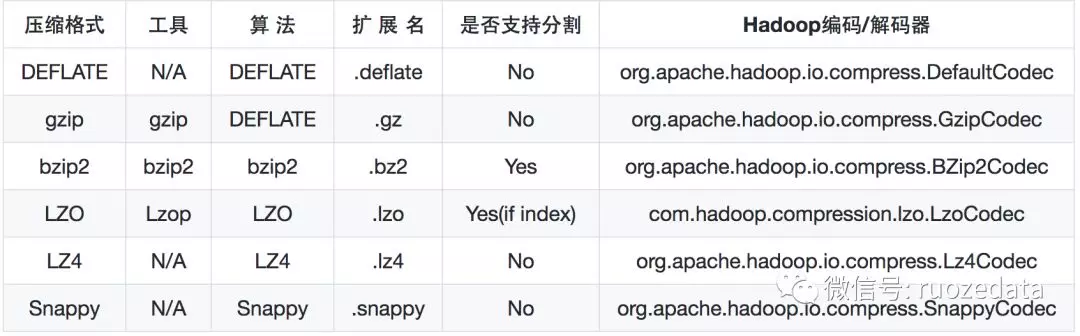
是否支持 Split
4. 压缩使用
Job 输出文件按照 block 以 GZip 的方式进行压缩:
set mapreduce.output.fileoutputformat.compress=true // 默认值是 false |
Map 输出结果也以 Gzip 进行压缩:
set mapred.map.output.compress=true |
对 Hive 输出结果和中间都进行压缩:
set hive.exec.compress.output=true // 默认值是 false,不压缩 |