
flume“Space for commit to queue couldn’t be acquired”异常产生分析
日志截图如下:
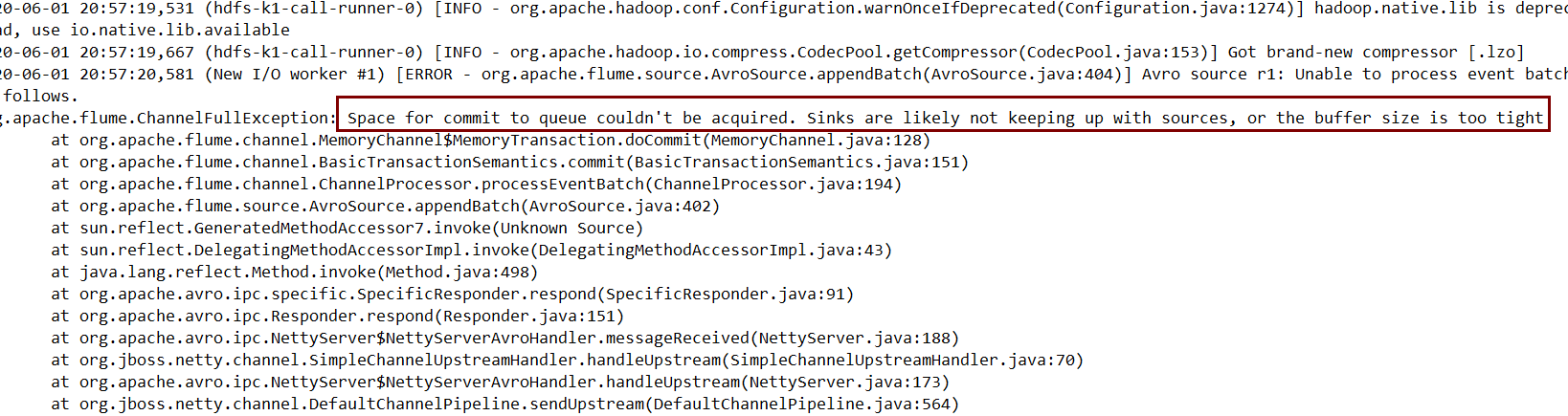
这里说的内容是:queue空间不足。sink好像没有紧跟source,或者是buffer大小太小。这里的queue代表什么?sink没有紧跟source的具体含义是什么?buffer又是什么?我分析源代码后,将结果在下面铺开向大家展示。
memory channel内部结构
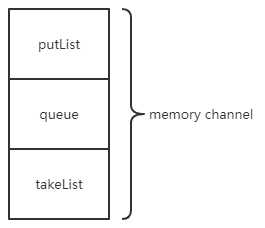
memory channel内部有三个队列,分别是图中的putList,queue,takeList。有两个参数来控制他们的大小,默认值都是100,分别是:
channel是如何被使用的
channel之上有一把锁,当source主动向channel放数据或者sink主动从channel取数据时,会抢锁,谁取到锁,谁就可以操作channel。
每次使用时会首先调用tx.begin()开始事务,也就是获取锁。然后调用tx.commit()提交数据或者调用tx.rollback()取消操作。
source往channel放数据
就是一个死循环,source一直试图获取channel锁,然后从kafka获取数据,放入channel中,那每次放入多少个数据呢?在KafkaSource.java中,代码是这样的:

含义就是:每次最多放batchUpperLimit或最多等待batchEndTime的时间,就结束向channel放数据。这两个参数的默认值分别是1000个和1s。分别由batchSize和batchDurationMillis设置。
当获取了足够的数据,首先放入putList中,然后就会调用tx.commit()将putList的全部数据放入queue中。
sink从channel取数据
也是一个死循环,sink一直试图获取channel锁,然后从channel取一批数据,放入sink和takeList(仅仅用于回滚,在调用rollback时takeList的数据会回滚道queue中)。每次取多少个event呢?这在HdfsSink中,代码如下:

batchSize的大小默认是100,由hdfs.batchSize控制,取够了,再调用tx.commit(),将putList的所有数据放入queue。
Space for commit to queue couldn’t be acquired异常如何发生的
经过上面的一系列介绍,已经知道了kafka source、memory channel、hdfs sink协同工作的过程。因为“source往putList放数据,然后提交到queue中”与“sink从channel中取数据到sink和takeList,然后再从putList取数据到queue中”这两部分是分开来,任他们自由抢锁,所以,当前者多次抢到锁,后者没有抢到锁,同时queue的大小又太小,撑不住多次往里放数据,就会导致触发这个异常。
解决这个问题最直接的办法就是增大queue的大小,增大capacity和transacCapacity之间的差距,queue能撑住多次往里面放数据即可。
失败后flume是如何处理的
flume会暂停source向channel放数据,等待几秒钟,这期间sink应该会消费channel中的数据,当source再次开始想channel放数据时channel就有足够的空间了。
flume调优避免内存不
增加 JVM 内存

增加capacity和transactionCapacity的容量

type - 组件类型名称必须是 memorycapacity 100 存储在 Channel 当中的最大 events 数 transactionCapacity 100 同时刻从Source 获取,或发送到 Sink 的最大 events 数 keep-alive 3 添加或删除一个 event 超时的秒数 如果每分钟开头量比较大,keep-alive需要调大