目录
- Spark术语
- Spark提交
- YARN上提交模式
- 宽依赖
- 窄依赖
术语
下表总结了关于集群概念的术语:
| Term | Meaning |
|---|---|
| Application | Spark上的应用程序。由一个driver program和集群上的executors组成。 |
| Application jar | 一个包含用户的Spark应用程序的jar包 |
| Driver program | 运行应用程序main()函数并创建SparkContext的进程 |
| Cluster manager | 用于获取集群资源的外部服务(例如,standalone manager、Mesos、YARN) |
| Deploy mode | 区别driver process在何处运行。在“cluster”模式下,框架启动集群内部的驱动程序。在“client”模式下,提交者启动集群外部的驱动程序。 |
| Worker node | 可以在集群中运行application的任何节点 |
| Executor | 在Worker node上被application启动的进程,它运行任务并将数据保存在内存或磁盘存储器中。每个application都有自己的Executor。 |
| Task | 将被发送给一个执行者的工作单元 |
| Job | 由多个任务组成的并行计算,这些任务在响应一个Spark操作时产生(如保存、收集) |
| Stage | 每个作业被分成更小的任务集,称为阶段,这些阶段相互依赖(类似于MapReduce中的map和reduce阶段) |
Spark提交
注意:在使用Spark提交之前,一定要在环境变量中配置HADOOP_CONF_DIR,否则hadoop的环境引不进来
export HADOOP_CONF_DIR=XXX |
Spark支持的部署模式:
./bin/spark-submit \ |
一些常用的选项是:
--class:您的应用程序的入口点(例如org.apache.spark.examples.SparkPi)--master:集群的主URL(例如spark://23.195.26.187:7077)--deploy-mode:将驱动程序部署在工作节点(cluster)上还是作为外部客户端(client)本地部署(默认值:client)--conf:键值格式的任意Spark配置属性。对于包含空格的值,将“ key = value”用引号引起来(如图所示)。application-jar:jar包的路径,包括您的应用程序和所有依赖项。URL必须在群集内部全局可见,例如,hdfs://路径或file://所有节点上都存在的路径。application-arguments:参数传递给您的主类的main方法(如果有)
其他常用的选项:
--num-executors:executors的数量--executor-memory:每个executor的内存数量--total-executor-cores 100:executor的总的core数--jars:指定需要依赖的jar包,多个jar包逗号分隔,application中直接引用--files:需要依赖的文件,在application中使用SparkFiles.get(“file”)取出,同时需要放在resources目录下
注意:local模式默认读写HDFS数据 读本地要加file://
提交模式
cliet模式
- Driver运行在Client
- AM职责就是去YARN上申请资源
- Driver会和请求到的container/executor进行通信
- Driver是不能退出的
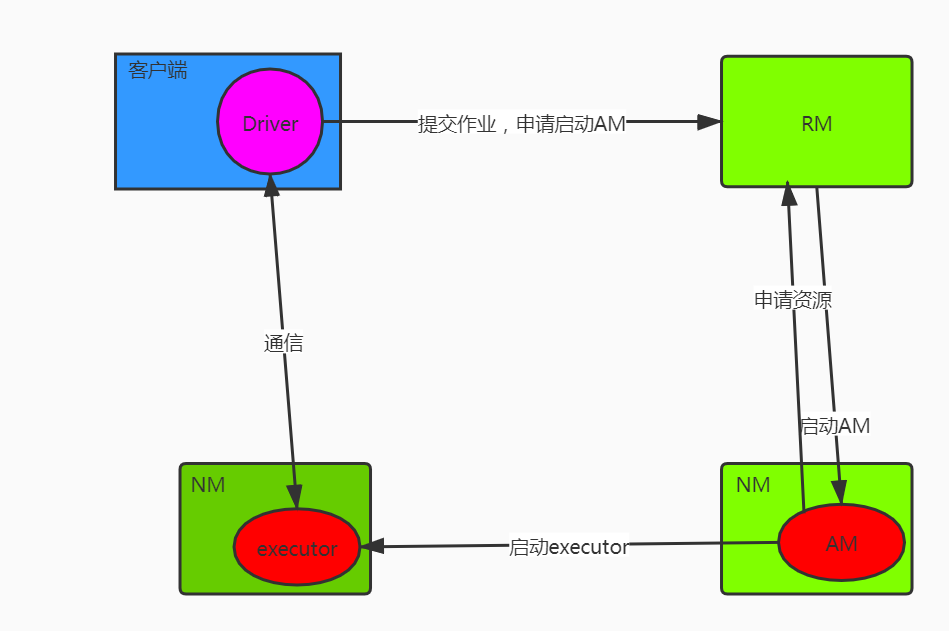
Client模式控制台能看到日志
cluster模式
Driver运行位置在AM
Client提交上去了 它退出对整个作业没影响
AM(申请资源)+Driver(调度DAG,分发任务)
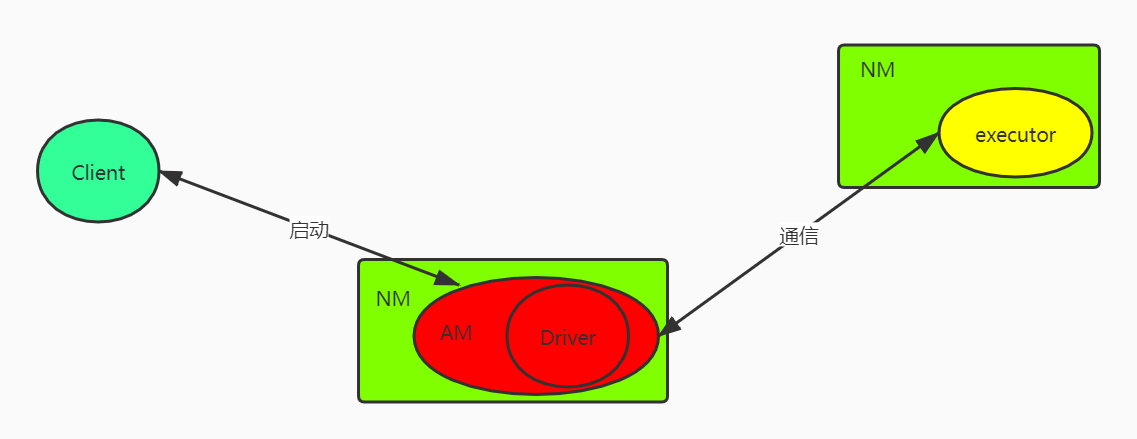
控制台不能看到日志,不支持Spark-shell(Spark-SQL) ,交互性操作的都不能
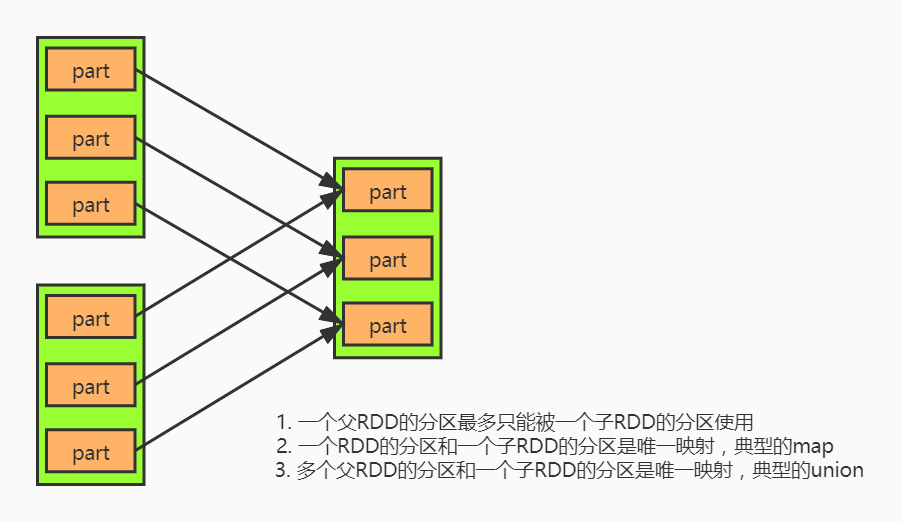
窄依赖
- 一个父RDD的分区至多被一个子RDD的某个分区使用一次
- 一个父RDD的分区和一个子RDD的分区是唯一映射 典型的map
- 多个父RDD的分区和一个子RDD的分区是唯一映射 典型的union
在窄依赖中有个特殊的join是不经过shuffle 的
这个特殊的join的存在有三个条件:
- RDD1的分区数 = RDD2的分区数
- RDD1的分区数 = Join的分区数
- RDD2的分区数 = Join的分区数
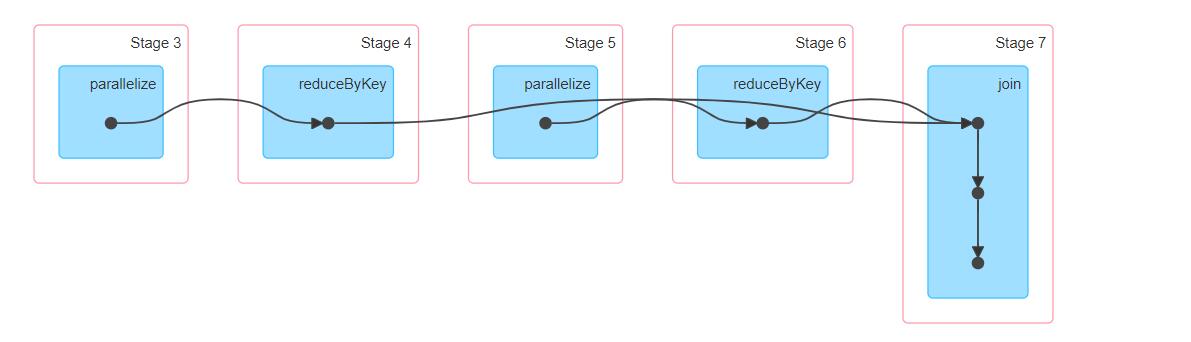
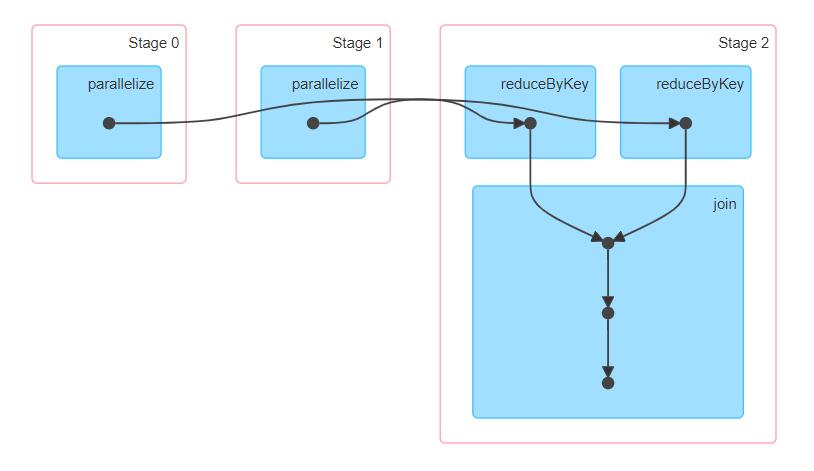
我们看一个案例:
/** |
再看Application的DAG图,从两个 reduceByKey 到 join 是一个 stage 中的,说明没有产生 shuffle
宽依赖
- 一个父RDD的分区会被子RDD的分区使用多次
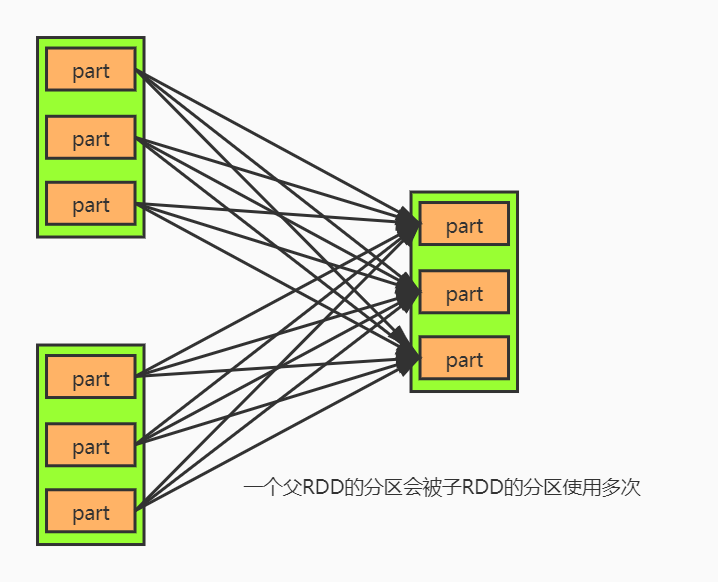
除了前面那种是三个条件满足的,其他的 join 都是宽依赖
我们使RDD1的分区数和RDD2的分区数相等,但是 join的分区数不相等
/** |
我们看DAG图,产生了stage,也就是经过了shuffle