
目录
- 经典案例
- 多目录输出
- 计数器
- 持久化
- 广播变量
经典案例
/** |
多目录输出
实现多目录输出自定义类
import org.apache.hadoop.io.NullWritable
import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat
class MyMultipleTextOutputFormat extends MultipleTextOutputFormat[Any,Any] {
//生成最终生成的key的类型,这里不要,给Null
override def generateActualKey(key: Any, value: Any): Any = NullWritable.get()
//生成最终生成的value的类型,这里是String
override def generateActualValue(key: Any, value: Any): Any = {
value.asInstanceOf[String]
}
//生成文件名
override def generateFileNameForKeyValue(key: Any, value: Any, name: String): String = {
s"$key/$name"
}
}主类,使用
saveAsHadoopFile(path, keyClass, valueClass, fm.runtimeClass.asInstanceOf[Class[F]])方法保存数据,指定参数object MultipleDirectory {
def main(args: Array[String]): Unit = {
val out = "tunan-spark-core/out"
val sc = ContextUtils.getSparkContext(this.getClass.getSimpleName)
CheckHDFSOutPath.ifExistsDeletePath(sc.hadoopConfiguration,out)
//读取数组,转换成键值对的格式
val lines = sc.textFile("tunan-spark-core/ip/access-result/*")
val mapRDD: RDD[(String, String)] = lines.map(line => {
val words = line.split(",")
(words(12), line)
})
//多目录保存文件
mapRDD.saveAsHadoopFile(out,classOf[String],classOf[String],classOf[MyMultipleTextOutputFormat])
sc.stop()
}
}结果
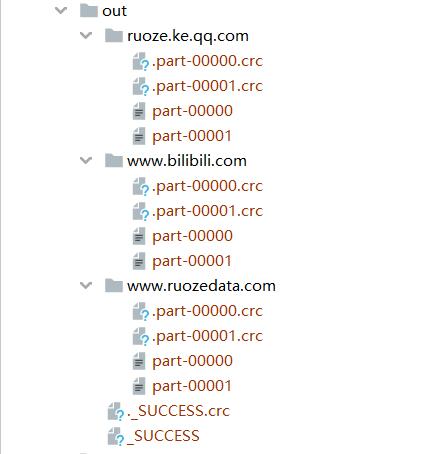
在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本。这些变量会被复制到每台机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。通常跨任务的读写变量是低效的,但是,Spark还是为两种常见的使用模式提供了两种有限的共享变量:广播变量(broadcast variable)和累加器(accumulator)
计数器
为什么要定义计数器?
在spark应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在被改变时不会再driver端进行全局汇总,即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
图解计数器
错误的图解
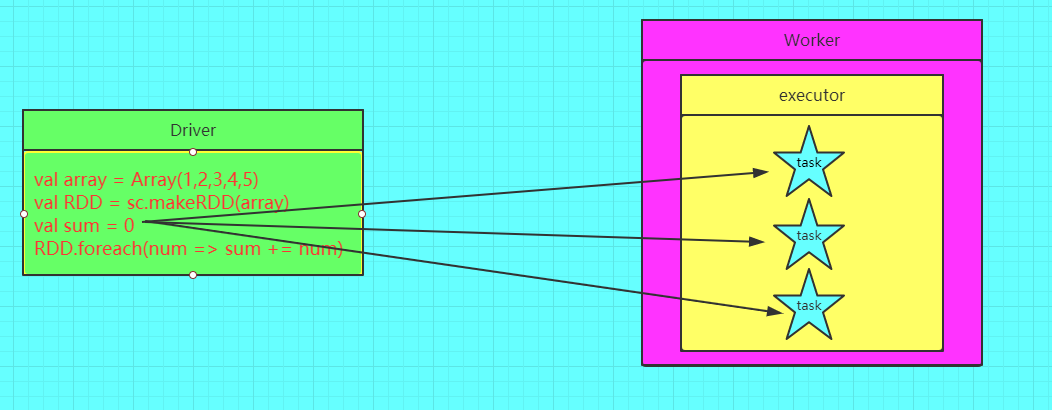
正确的图解
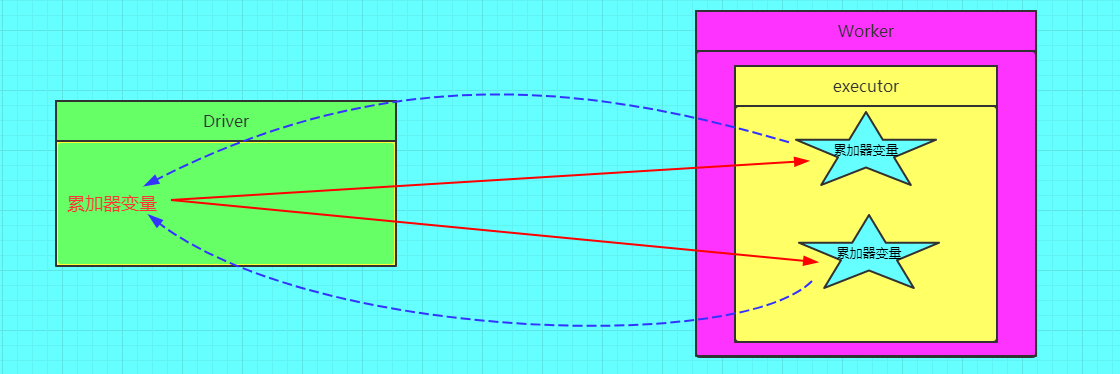
计数器种类很多,但是经常用的就是两种,longAccumulator和collectionAccumulator
需要注意的是计数器是lazy的,只有触发action才会进行计数,在不持久化的情况下重复触发action,计数器会重复累加
LongAccumulator
Accumulators 是只能通过associative和commutative操作“added”的变量,因此可以有效地并行支持。它们可用于实现计数器(如MapReduce)和Spark本身支持数字类型的累加器,程序员还可以添加对新类型的支持。
longAccumulator通过累加的方式计数
object MyLongAccumulator { |
使用longAccumulator做计数的时候要小心重复执行action导致的acc.value的变化
object MyLongAccumulatorV2{ |
由于重复执行了count(),累加器的数量成倍增长,解决这种错误累加也很简单,就是在count之前调用forRDD的cache方法(或persist),这样在count后数据集就会被缓存下来,reduce操作就会读取缓存的数据集,而无需从头开始计算。
object MyLongAccumulator { |
CollectionAccumulator
collectionAccumulator,集合计数器,计数器中保存的是集合元素,通过泛型指定。
/** |
注意事项:
计数器在Driver端定义赋初始值,计数器只能在Driver端读取最后的值,在Excutor端更新。
计数器不是一个调优的操作,因为如果不这样做,结果是错的
持久化
Spark中最重要的功能之一是跨操作在内存中持久化数据集。持久化一个RDD时,每个节点在内存中存储它计算的任何分区,并在该数据集(或从中派生的数据集)的其他操作中重构它们。这使得将来的操作要快得多(通常超过10倍)。缓存是迭代算法和快速交互使用的关键工具。
可以使用其上的persist()或cache()方法将RDD标记为持久的。第一次在操作中计算它时,它将保存在节点的内存中。Spark的缓存是容错的——如果一个RDD的任何分区丢失了,它将使用最初创建它的转换自动重新计算。
持久化的存储级别很多,常用的是MEMORY_ONLY、MEMORY_ONLY_SER、MEMORY_AND_DISK
| Storage Level | Meaning |
|---|---|
| MEMORY_ONLY | 将RDD作为不序列化的Java对象存储在JVM中。如果RDD不适合内存,那么一些分区将不会被缓存,而是在需要它们时动态地重新计算。这是默认级别。 |
| MEMORY_AND_DISK | 将RDD作为不序列化的Java对象存储在JVM中。如果RDD不适合内存,那么将不适合的分区存储在磁盘上,并在需要时从那里读取它们。 |
| MEMORY_ONLY_SER (Java and Scala) | 将RDD存储为序列化的Java对象(每个分区一个字节数组)。这通常比反序列化对象更节省空间,特别是在使用快速序列化器时,但读取时需要更多cpu。 |
如何选择它们?
Storage Level的选择是内存和CPU的权衡
- 内存多:MEMORY_ONLY (不进行序列化)
- CPU跟的上:MEMORY_ONLY_SER (进行了序列化,推介)
- 不建议写Disk
使用cache()和persist()进行持久化操作,它们都是lazy的,需要action才能触发,默认使用MEMORY_ONLY
forRDD.cache |
结果可以在Web UI的Storage中查看
如果需要清除缓存,使用unpersist(),清除缓存数据是立即执行的
forRDD.unpersist() |
怎么修改存储级别?
val forRDD = rdd.map(x => { |
StorageLevel是个object,需要的级别都可以从里面拿出来
考点:cache和persist有什么区别?
- cache调用的persist,persist调用的persist(storage level)
考点:序列化和非序列化有什么区别?
- 序列化将对象转换成字节数组了,节省空间,占CPU
Removing Data
Spark自动监视每个节点上的缓存使用情况,并以最近最少使用(LRU)的方式删除旧的数据分区。如果想要手动删除一个RDD,而不是等待它从缓存中消失,那么可以使用RDD.unpersist()方法。
伪代码以及画图表示出什么是LRU?
广播变量
为什么要将变量定义成广播变量?
如果我们要在分布式计算里面分发大对象,例如:字典,集合,黑白名单等,这个都会由Driver端进行分发,一般来讲,如果这个变量不是广播变量,那么每个task就会分发一份,这在task数目十分多的情况下Driver的带宽会成为系统的瓶颈,而且会大量消耗task服务器上的资源,如果将这个变量声明为广播变量,那么知识每个executor拥有一份,这个executor启动的task会共享这个变量,节省了通信的成本和服务器的资源。
广播变量图解
错误的,不使用广播变量
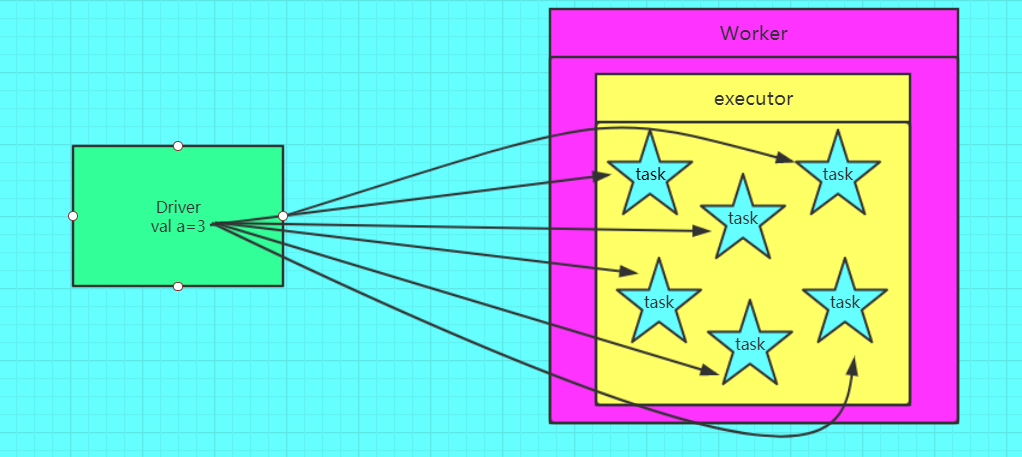
正确的,使用广播变量的情况

小表广播案例
使用广播变量的场景很多, 我们都知道spark 一种常见的优化方式就是小表广播, 使用 map join 来代替 reduce join, 我们通过把小的数据集广播到各个节点上,节省了一次特别 expensive 的 shuffle 操作。
比如driver 上有一张数据量很小的表, 其他节点上的task 都需要 lookup 这张表, 那么 driver 可以先把这张表 copy 到这些节点,这样 task 就可以在本地查表了。
Fact table 航线(起点机场, 终点机场, 航空公司, 起飞时间)
SEA,JFK,DL,7:00
SFO,LAX,AA,7:05
SFO,JFK,VX,7:05
JFK,LAX,DL,7:10
LAX,SEA,DL,7:10Dimension table 机场(简称, 全称, 城市, 所处城市简称)
JFK,John F. Kennedy International Airport,New York,NY
LAX,Los Angeles International Airport,Los Angeles,CA
SEA,Seattle-Tacoma International Airport,Seattle,WA
SFO,San Francisco International Airport,San Francisco,CADimension table 航空公司(简称,全称)
AA,American Airlines
DL,Delta Airlines
VX,Virgin America思路:将机场维度表和航空公司维度表进行广播,生成Map,航线事实表从广播变量中通过key拿到value(计算在每个executor上)
代码
object BroadcastApp {
def main(args: Array[String]): Unit = {
val sc: SparkContext = ContextUtils.getSparkContext(this.getClass.getSimpleName)
// Fact table 航线(起点机场, 终点机场, 航空公司, 起飞时间)
val flights = sc.textFile("tunan-spark-core/broadcast/flights.txt")
// Dimension table 机场(简称, 全称, 城市, 所处城市简称)
val airports: RDD[String] = sc.textFile("tunan-spark-core/broadcast/airports.txt")
// Dimension table 航空公司(简称,全称)
val airlines = sc.textFile("tunan-spark-core/broadcast/airlines.txt")
/**
* 最终统计结果:
* 出发城市 终点城市 航空公司名称 起飞时间
* Seattle New York Delta Airlines 7:00
* San Francisco Los Angeles American Airlines 7:05
* San Francisco New York Virgin America 7:05
* New York Los Angeles Delta Airlines 7:10
* Los Angeles Seattle Delta Airlines 7:10
*/
//广播Dimension Table airport,生成Map
val airportsBC = sc.broadcast(airports.map(x => {
val words = x.split(",")
(words(0), words(2))
}).collectAsMap())
//广播Dimension Table airlines,生成Map
val airlinesBC = sc.broadcast(airlines.map(x => {
val words = x.split(",")
(words(0), words(1))
}).collectAsMap())
//通过key获取value
flights.map(lines => {
val words = lines.split(",")
val a = airportsBC.value.get(words(0)).get
val b = airportsBC.value.get(words(1)).get
val c = airlinesBC.value.get(words(2)).get
a+" "+b+" "+c+" "+words(3)
}).foreach(println)
sc.stop()
}
}结果
New York Los Angeles Delta Airlines 7:10
Los Angeles Seattle Delta Airlines 7:10
Seattle New York Delta Airlines 7:00
San Francisco Los Angeles American Airlines 7:05
San Francisco New York Virgin America 7:05
为什么只能 broadcast 只读的变量
这就涉及一致性的问题,如果变量可以被更新,那么一旦变量被某个节点更新,其他节点要不要一块更新?如果多个节点同时在更新,更新顺序是什么?怎么做同步? 仔细想一下, 每个都很头疼, spark 目前就索性搞成了只读的。 因为分布式强一致性真的很蛋疼
注意事项
变量一旦被定义为一个广播变量,那么这个变量只能读,不能修改
能不能将一个RDD使用广播变量广播出去?因为RDD是不存储数据的。可以将RDD的结果广播出去。
广播变量只能在Driver端定义,不能在Executor端定义。
在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
如果executor端用到了Driver的变量,不使用广播变量在Executor有多少task就有多少Driver端的变量副本。
如果Executor端用到了Driver的变量,使用广播变量在每个Executor中只有一份Driver端的变量副本。