
目录
- SparkSQL
- DataFrame的read和write
- SparkSQL做统计分析
- UDF函数
- 存储格式的转换
SparkSQL
认识SparkSQL
SparkSQL的进化之路
1.0以前:
Shark
1.1.x开始:
SparkSQL(只是测试性的) SQL
1.3.x:
SparkSQL(正式版本)+Dataframe
1.5.x:
SparkSQL 钨丝计划
1.6.x:
SparkSQL+DataFrame+DataSet(测试版本)
2.x.x:
SparkSQL+DataFrame+DataSet(正式版本)
SparkSQL:还有其他的优化
StructuredStreaming(DataSet)什么是SparkSQL?
spark SQL是spark的一个模块,主要用于进行结构化数据的处理。它提供的最核心的编程抽象就是DataFrame。
SparkSQL的作用
提供一个编程抽象(DataFrame) 并且作为分布式 SQL 查询引擎
DataFrame:它可以根据很多源进行构建,包括:结构化的数据文件,hive中的表,外部的关系型数据库,以及RDD
运行原理
将 Spark SQL 转化为 RDD, 然后提交到集群执行
特点
- 容易整合
- 统一的数据访问方式
- 兼容 Hive
- 标准的数据连接
spark-sql
spark-sql是一个Spark专属的SQL命令行交互工具,在使用spark-sql之前要把hive-site.xml 拷贝到Spark/Conf下,spark-sql和spark-shell用法一样,但是在引入外部依赖的时候,spark-sql需要用–jars和–driver-class-path同时引入依赖才不会报错
持久化
在spark-sql中的持久化Table命令是: cache table xxx,清除持久化 uncache table xxx
spark-SQL中的cache和uncache都是eager的,立即执行的
考点:RDD和SparkSQL的cache有什么区别?
- RDD中的cache是lazy的 spark-SQL中的cache是eager的
遗留问题
–files/–jars 传进去的东西清不掉
SparkSession
SparkSession是Spark 2.0引如的新概念。SparkSession为用户提供了统一的切入点,来让用户学习spark的各项功能。
在spark的早期版本中,SparkContext是spark的主要切入点,由于RDD是主要的API,我们通过sparkcontext来创建和操作RDD。对于每个其他的API,我们需要使用不同的context。例如,对于Streming,我们需要使用StreamingContext;对于sql,使用sqlContext;对于Hive,使用hiveContext。但是随着DataSet和DataFrame的API逐渐成为标准的API,就需要为他们建立接入点。所以在spark2.0中,引入SparkSession作为DataSet和DataFrame API的切入点,SparkSession封装了SparkConf、SparkContext和SQLContext。为了向后兼容,SQLContext和HiveContext也被保存下来。
SparkSession实质上是SQLContext和HiveContext的组合(未来可能还会加上StreamingContext),所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了sparkContext,所以计算实际上是由sparkContext完成的。
特点:
为用户提供一个统一的切入点使用Spark 各项功能
允许用户通过它调用 DataFrame 和 Dataset 相关 API 来编写程序
减少了用户需要了解的一些概念,可以很容易的与 Spark 进行交互
与 Spark 交互之时不需要显示的创建 SparkConf, SparkContext 以及 SQlContext,这些对象已经封闭在 SparkSession 中
DataFrame
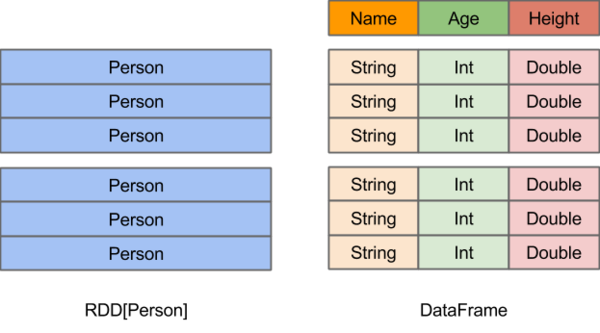
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。
DataFrame的read和write
json
数据的读取[DataFrameReader]
object rdd2df {
def main(args: Array[String]): Unit = {
val in = "tunan-spark-sql/data/people.json"
val spark = SparkSession
.builder()
.master("local[2]")
.appName(this.getClass.getSimpleName)
.config("spark.some.config.option", "some-value")
.getOrCreate()
// 读取json数据
val df: DataFrame = spark.read.format("json").load(in)
// 使用$"" 导入隐式转换
import spark.implicits._
// 可以使用UDF
df.select($"name",$"age").show(2,false)
// 不可以使用UDF 适合大部分场景
df.select("name","age").show()
// 不推介,写着复杂
df.select(df("name"),df("age")).show(2)
}
}select方法用于选择要输出的列,推介使用 $”col” 和 “col” 的方法
- 使用select可以选取打印的列,空值为null
- show()默认打印20条数据,可以指定条数
- truncate默认为true,截取长度,可以设置为false
select方法有三种不同的写法,fliter也有
df.select(df("name"),df("age")).filter('name === "Andy").show() //推介使用
df.select(df("name"),df("age")).filter(df("name") === "Andy").show()
df.select(df("name"),df("age")).filter("name = 'Andy'").show()printSchema()方法可以查看数据的Schema信息
df.printSchema()
------------------------------------------------
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)数据的存储[DataFrameWriter]
val selectDf: DataFrame = df.select($"name", $"age")
// 写出json数据
selectDf.write.format("json").mode("overwrite").save(out)这里需要知道的一个概念是Save Modes
Save操作可以选择使用SaveMode,它指定目标如果存在,如何处理现有数据。重要的是要认识到,这些保存模式不利用任何锁定,也不是原子性的。此外,在执行覆盖时,在写入新数据之前将删除数据。
Scala/Java Any Language Meaning SaveMode.ErrorIfExists(default)"error" or "errorifexists"(default)在将DataFrame保存到数据源时,如果数据已经存在,则会抛出error。 SaveMode.Append"append"在将DataFrame保存到数据源时,如果数据/表已经存在,则DataFrame的内容将被append到现有数据中。 SaveMode.Overwrite"overwrite"overwrite模式意味着在将DataFrame保存到数据源时,如果数据/表已经存在,则现有数据将被DataFrame的内容覆盖。 SaveMode.Ignore"ignore"ignore模式意味着在将DataFrame保存到数据源时,如果数据已经存在,则save操作不保存DataFrame的内容,也不更改现有数据。这类似于SQL中的 CREATE TABLE IF NOT EXISTS。
text
数据的读取
object text2df {
def main(args: Array[String]): Unit = {
val in = "tunan-spark-sql/data/people.txt"
val out = "tunan-spark-sql/out"
val spark = SparkSession
.builder()
.master("local[2]")
.appName(this.getClass.getSimpleName)
.config("spark.some.config.option", "some-value")
.getOrCreate()
import spark.implicits._
//DataFrame不能直接split,且调用map返回的是一个Dataset
val df: DataFrame = spark.read.format("text").load(in)
val mapDF: Dataset[(String, String)] = df.map(row => {
val words = row.toString().split(",")
(words(0), words(1))
})
mapDF.show()
//DataFrame转换为RDD后,再toDF,返回的是一个DataFrame
val mapRDD2DF: DataFrame = df.rdd.map(row => {
val words = row.toString().split(",")
(words(0), words(1))
}).toDF()
mapRDD2DF.show()
//使用textFile方法读取文本文件直接返回的是一个Dataset
val ds: Dataset[String] = spark.read.textFile(in)
val mapDs: Dataset[(String, String)] = ds.map(row => {
val words = row.split(",")
(words(0), words(1))
})
mapDs.show()
}
}文本数据读进来的一行在一个字段里面,所以要使用map算子,在map中split
- 直接read.format()读进来的是DataFrame,map中不能直接split
- DataFrame通过.rdd的方式转换成RDD,map中也不能直接split
- 通过read.textFile()的方式读进来的是Dataset,map中可以split
数据的存储
val df: DataFrame = spark.read.format("text").load(in)
val mapDF = df.map(row => {
val words = row.toString().split(",")
// 拼接成一列
words(0) +","+words(1)
})
mapDF.write.format("text").mode("overwrite").save(out)文本数据写出去的时候
- 不支持int类型,如果存在int类型,会报错,解决办法是toString,转换成字符串
- 只能作为一列输出,如果是多列,会报错,解决办法是拼接起来,组成一列
文本数据压缩输出,只要是Spark支持的压缩的格式,都可以指定
mapDF.write
.format("text")
// 添加压缩操作
.option("compression","gzip")
.mode("overwrite")
.save(out)
csv
数据的读取
object csv2df {
def main(args: Array[String]): Unit = {
val in = "tunan-spark-sql/data/people.csv"
val out = "tunan-spark-sql/out"
val spark = SparkSession
.builder()
.master("local[2]")
.appName(this.getClass.getSimpleName)
.config("spark.some.config.option", "some-value")
.getOrCreate()
val df: DataFrame = spark.read
.format("csv")
.option("header", "true")
.option("sep", ";")
.option("interSchema","true")
.load(in)
df.show()
}
}csv读取数据注意使用几个参数
- 指定表头:
option("header", "true") - 指定分隔符:
option("sep", ";") - 类型自动推测:
option("interSchema","true")
- 指定表头:
jdbc
在操作jdbc之前要导入两个依赖,一个是mysql-jdbc,用来连接mysql,一个是config,用来解决硬编码的问题
依赖:
<dependency> |
application.conf文件
db.default.driver="com.mysql.jdbc.Driver" |
数据的读取
object mysql2df {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[2]")
.appName(this.getClass.getSimpleName)
.config("spark.some.config.option", "some-value")
.getOrCreate()
//获取配置文件中的值,db.default开头
val conf = ConfigFactory.load()
val driver = conf.getString("db.default.driver")
val url = conf.getString("db.default.url")
val user = conf.getString("db.default.user")
val password = conf.getString("db.default.password")
val source = conf.getString("db.default.source")
val target = conf.getString("db.default.target")
val db = conf.getString("db.default.db")
//读取数据库的内容
val df: DataFrame = spark.read
.format("jdbc")
.option("url", url)
.option("dbtable", s"$db.$source") //库名.源表
.option("user", user)
.option("password", password)
.option("driver", driver)
.load()
//使用DataFrame创建临时表提供spark.sql查询
df.createOrReplaceTempView("phone_type_dist")
//spark.sql写SQL返回一个DataFrame
val sqlDF: DataFrame = spark.sql("select * from phone_type_dist where phoneSystemType = 'IOS'")
}
}- 使用df.createOrReplaceTempView()方法创建一个DataFrame数据生成的临时表,提供spark.sql()使用SQL操作数据,返回的也是一个DataFrame
数据的存储
//接着上面返回的sqlDF: DataFrame
sqlDF.write
.format("jdbc")
.option("url", url)
.option("dbtable", s"$db.$target") //库名.目标表
.option("user", user)
.option("password", password)
.option("driver",driver)
.save()
SparkSQL做统计分析
数据
需求:求每个国家的每个域名的访问流量排名前2
SQL实现
object GroupTopN {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[2]")
.appName(this.getClass.getSimpleName)
.config("spark.some.config.option", "some-value")
.getOrCreate()
//读取数据
val ds = spark.read.textFile(in)
import spark.implicits._
//为生成需要的表格做准备
val df: DataFrame = ds.map(row => {
val words = row.split(",")
(words(3), words(12), words(15).toLong)
}).toDF("country", "domain", "traffic")
df.createOrReplaceTempView("access")
// 每个国家的域名流量前2
val topNSQL="""select
| *
|from (
| select
| t.*,row_number() over(partition by country order by sum_traffic desc) r
| from
| (
| select country,domain,sum(traffic) as sum_traffic from access group by country,domain
| ) t
| ) rt
|where rt.r <=2 """.stripMargin
spark.sql(topNSQL).show()
}
}如果只要求traffic的降序,可以使用API直接写出来
分组,求和,别名,降序
//traffic降序排序
import org.apache.spark.sql.functions._
df.groupBy("country","domain").agg(sum("traffic").as("sum_traffic")).sort($"sum_traffic".desc).show()注意看源码中案例仿写
结果展示
+----------------+-----------------+-----------+---+
| country| domain|sum_traffic| r|
+----------------+-----------------+-----------+---+
| 中国| www.bilibili.com| 24265886| 1|
| 中国|www.ruozedata.com| 4187637| 2|
| 利比亚| www.bilibili.com| 22816| 1|
| 利比亚| ruoze.ke.qq.com| 15970| 2|
| 加纳| www.bilibili.com| 138659| 1|
| 加纳|www.ruozedata.com| 17988| 2|
| 利比里亚| www.bilibili.com| 20593| 1|
| 利比里亚| ruoze.ke.qq.com| 7466| 2|
+----------------+-----------------+-----------+---+
UDF函数
数据
大狗 小破车,渣团,热刺,我纯
桶子 利物浦
二娃 南大王,西班牙人需求:求出每个人的爱好的个数
SQLs实现
object LoveLength {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[2]")
.appName(this.getClass.getSimpleName)
.config("spark.some.config.option", "some-value")
.getOrCreate()
//读取文本内容
val ds: Dataset[String] = spark.read.textFile(in)
//文本转换成DF
import spark.implicits._
val df: DataFrame = ds.map(row => {
val words = row.split("\t")
(words(0), words(1))
}).toDF("name", "love")
//创建UDF
spark.udf.register("length", (love: String) => {
love.split(",").length
})
//DF创建临时表
df.createOrReplaceTempView("udf_love")
//在sql中使用UDF函数
spark.sql("select name,love,length(love) as love_length from udf_love").show()
}
}上面是使用SQL的解决方案,还可以使用API的方法
//自定义的udf需要返回值
val loveLengthUDF: UserDefinedFunction = spark.udf.register("length", (love: String) => {
love.split(",").length
})
//df.select中传入UDF函数
df.select($"name",$"love",loveLengthUDF($"love")).show()结果展示
+----+---------------------+----------------+
|大狗|小破车,渣团,热刺,我纯 | 4|
|桶子| 利物浦 | 1|
|二娃| 南大王,西班牙人 | 2|
+----+---------------------+----------------+
存储格式的转换
Spark读text文件进行清洗,清洗完以后直接以我们想要的列式存储格式输出,如果按以前的方式要经过很多复杂的步骤
用Spark的时候只需要在df.write.format("orc").mode().save()中指定格式即可,如orc,现在就很方便了,想转成什么格式,只要format支持就ok
object text2orc { |
20200416更新: df.write.format(“…”).option(“compression”,”…”) ==> 存储格式+压缩格式