
Kafka中的每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序号,用于partition唯一标识一条消息。
Offset记录着下一条将要发送给Consumer的消息的序号。
Offset从语义上来看拥有两种:Current Offset和Committed Offset。
Current Offset
Current Offset保存在Consumer客户端中,它表示Consumer希望收到的下一条消息的序号。它仅仅在pull()方法中使用。例如,Consumer第一次调用pull()方法后收到了20条消息,那么Current Offset就被设置为20。这样Consumer下一次调用pull()方法时,Kafka就知道应该从序号为21的消息开始读取。这样就能够保证每次Consumer pull消息时,都能够收到不重复的消息。
Committed Offset
Committed Offset保存在Broker上,它表示Consumer已经确认消费过的消息的序号。主要通过commitSync和commitAsync API来操作。举个例子,Consumer通过pull() 方法收到20条消息后,此时Current Offset就是20,经过一系列的逻辑处理后,并没有调用consumer.commitAsync()或consumer.commitSync()来提交Committed Offset,那么此时Committed Offset依旧是0。
Committed Offset主要用于Consumer Rebalance。在Consumer Rebalance的过程中,一个partition被分配给了一个Consumer,那么这个Consumer该从什么位置开始消费消息呢?答案就是Committed Offset。另外,如果一个Consumer消费了5条消息(pull并且成功commitSync)之后宕机了,重新启动之后它仍然能够从第6条消息开始消费,因为Committed Offset已经被Kafka记录为5。
总结一下,Current Offset是针对Consumer的pull过程的,它可以保证每次pull都返回不重复的消息;而Committed Offset是用于Consumer Rebalance过程的,它能够保证新的Consumer能够从正确的位置开始消费一个partition,从而避免重复消费。
Offset存储模型
由于一个partition只能固定的交给一个消费者组中的一个消费者消费,因此Kafka保存offset时并不直接为每个消费者保存,而是以groupid-topic-partition -> offset的方式保存。如图所示:
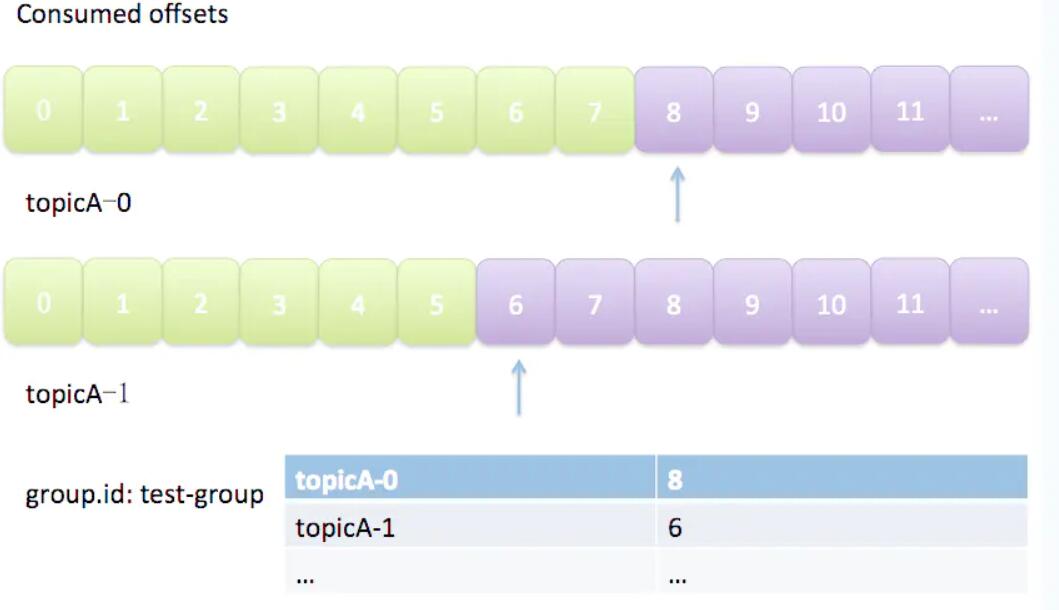
Kafka在保存Offset的时候,实际上是将Consumer Group和partition对应的offset以消息的方式保存在__consumers_offsets这个topic中。
下图展示了__consumers_offsets中保存的offset消息的格式:
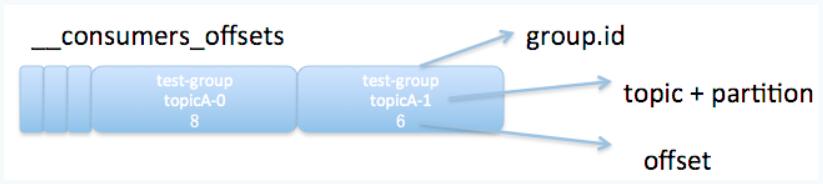

如图所示,一条offset消息的格式为groupid-topic-partition -> offset。因此consumer pull消息时,已知groupid和topic,又通过Coordinator分配partition的方式获得了对应的partition,自然能够通过Coordinator查找__consumers_offsets的方式获得最新的offset了。
Kafka Offset 的几种管理方式
Spark Checkpoint:在 Spark Streaming 执行Checkpoint 操作时,将 Kafka Offset 一并保存到 HDFS 中。这种方式的问题在于:当 Spark Streaming 应用升级或更新时,以及当Spark 本身更新时,Checkpoint 可能无法恢复。因而,不推荐采用这种方式。HBASE、Redis 等外部 NOSQL 数据库:这一方式可以支持大吞吐量的 Offset 更新,但它最大的问题在于:用户需要自行编写 HBASE 或 Redis 的读写程序,并且需要维护一个额外的组件。ZOOKEEPER:老版本的位移offset是提交到zookeeper中的,目录结构是 :/consumers/<group.id>/offsets/ <topic>/<partitionId> ,但是由于 ZOOKEEPER 的写入能力并不会随着 ZOOKEEPER 节点数量的增加而扩大,因而,当存在频繁的 Offset 更新时,ZOOKEEPER 集群本身可能成为瓶颈。因而,不推荐采用这种方式。KAFKA 自身的一个特殊 Topic(__consumer_offsets)中:这种方式支持大吞吐量的Offset 更新,又不需要手动编写 Offset 管理程序或者维护一套额外的集群,但是Kafka不支持事物,不能保证输出的幂等性(Exactly once)。
Redis实现Offset幂等性消费
使用场景
Spark Streaming实时消费kafka数据的时候,程序停止或者Kafka节点挂掉会导致数据丢失,Spark Streaming也没有设置CheckPoint(节点挂了,数据容易丢失),所以每次出现问题的时候,重启程序,而程序的消费方式是Direct,所以在程序down掉的这段时间Kafka上的数据是消费不到的,虽然可以设置offset为smallest,但是会导致重复消费,重新overwrite hive上的数据,但是不允许重复消费的场景就不能这样做。
原理阐述
在Spark Streaming中消费 Kafka 数据的时候,有两种方式分别是 :
基于 Receiver-based 的 createStream 方法。receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming启动的job会去处理那些数据。然而,在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中。所以,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。本文对此方式不研究,有兴趣的可以自己实现,个人不喜欢这个方式。
Direct Approach (No Receivers) 方式的 createDirectStream 方法,但是第二种使用方式中 kafka 的 offset 是保存在 checkpoint 中的,如果程序重启的话,会丢失一部分数据,我使用的是这种方式。KafkaUtils.createDirectStream。本文将用代码说明如何将 kafka 中的 offset 保存到 Redis 中,以及如何从 Redis 中读取已存在的 offset。参数auto.offset.reset为latest的时候程序才会读取redis的offset。
代码实现
OffsetsManager trait
trait OffsetsManager { |
RedisOffsetsManager object
object RedisOffsetsManager extends OffsetsManager { |
这里offsets保存在Redis,如果是MySQL同理,只需要实现obtainOffsets和storeOffsets方法
object MySQLOffsetsManager extends OffsetsManager { |
OffsetsRedis
object OffsetsRedis { |
exactly once方案
准确的说也不是严格的方案,要根据实际的业务场景来配合。
现在的方案是保存rdd的最后一个offset,我们可以考虑在处理完一个消息之后就更新offset,保存offset和业务处理做成一个事务,当出现Exception的时候,都进行回退,或者将出现问题的offset和消息发送到另一个kafka或者保存到数据库,另行处理错误的消息。代码demo如下
stream.foreachRDD(rdd => { |
注意:pipeline不能在Redis集群中使用,但是适用于主从架构
20200701更新: 在消费的时候使用事物保证精准一次消费语义效率太低,解决办法是类似于HBase的upsert语法,有则更新,没有则追加。使用try catch套住。
语义
数据流系统的语义通常根据系统可以处理每个记录的次数来捕获。在所有可能的操作条件下(除了故障等),系统可以提供三种类型的保证。
- At most once: 每个记录要么处理一次,要么根本不处理。
- At least once: 每个记录将被处理一次或多次。这比最多一次强,因为它确保不会丢失任何数据。但是可能有重复的。
- Exactly once: 每条记录将被精确处理一次——没有数据会丢失,也没有数据会被多次处理。这显然是三者中最有力的保证。
auto.offset.reset参数
Kafka 默认是定期帮你自动提交位移的(enable.auto.commit=true)。有时候,我们需要采用自己来管理位移提交,这时候需要设置 enable.auto.commit=false。
earliest: 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
latest: 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
none: topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
默认建议用earliest。设置该参数后 kafka出错后重启,找到未消费的offset可以继续消费。
而latest 这个设置容易丢失消息,假如kafka出现问题,还有数据往topic中写,这个时候重启kafka,这个设置会从最新的offset开始消费,中间出问题的哪些就不管了。