
目录
- SS+Kafka提交服务器
- 窗口函数
- SS调优
SS+Kafka提交服务器
由于Spark自身没有spark-streaming-kafka的依赖,所以Spark Streaming+Kafka的Application跑在服务器上需要添加spark-streaming-kafka的依赖,共有三种添加依赖的方式
- 直接在IDEA中打胖包,但是服务器上有的东西需要标识为privated,不然依赖重复了,这种方式不推介
- 提交Application的时候使用–packages参数,格式为:
groupId:artifactId:version,这种方式需要在有网络的情况下才能使用 - 使用–jars 传入依赖,推介,这里有个技巧,可以将需要的 jar 包放在固定目录下,需要传入依赖的时候只需要使用 $(echo /home/hadoop/lib/*.jar | tr ‘ ‘ ‘,’)即可以将目录下的 jar 包全都拼接上去
简单的WC案例
object wc_ss_kafka { |
作业提交
spark-submit \ |
查看结果
窗口函数
前面有介绍窗口函数,现在我们来看一下如何使用
在工作中常常有这样的需求:
- 每隔5秒钟统计前10秒钟的数据
- 每隔1分钟统计前05分钟的数据
这类每隔多少统计前多少时间的操作就时窗口操作
我们以一个例子来说明窗口操作。 对之前的单词计数的示例进行扩展,每10秒钟对过去30秒的数据进行wordcount。为此,我们必须在最近30秒的DStream数据中对键值对应用reduceByKey操作。这是通过使用reduceByKeyAndWindow操作完成的。
// 每隔10秒统计前30秒的数据 |
一些常见的窗口操作如下表所示。所有这些操作都用到了上述两个参数:windowLength和slideInterval。
window(windowLength, slideInterval)基于源DStream产生的窗口化的批数据计算一个新的DStream
countByWindow(windowLength, slideInterval)返回流中元素的一个滑动窗口数
reduceByWindow(func, windowLength, slideInterval)返回一个单元素流。利用函数func聚集滑动时间间隔的流的元素创建这个单元素流。函数必须是相关联的以使计算能够正确的并行计算。
reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])应用到一个(K,V)对组成的DStream上,返回一个由(K,V)对组成的新的DStream。每一个key的值均由给定的reduce函数聚集起来。注意:在默认情况下,这个算子利用了Spark默认的并发任务数去分组。你可以用numTasks参数设置不同的任务数
reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])上述
reduceByKeyAndWindow()的更高效的版本,其中使用前一窗口的reduce计算结果递增地计算每个窗口的reduce值。这是通过对进入滑动窗口的新数据进行reduce操作,以及“逆减(inverse reducing)”离开窗口的旧数据来完成的。一个例子是当窗口滑动时对键对应的值进行“一加一减”操作。但是,它仅适用于“可逆减函数(invertible reduce functions)”,即具有相应“反减”功能的减函数(作为参数invFunc)。 像reduceByKeyAndWindow一样,通过可选参数可以配置reduce任务的数量。 请注意,使用此操作必须启用检查点。countByValueAndWindow(windowLength, slideInterval, [numTasks])应用到一个(K,V)对组成的DStream上,返回一个由(K,V)对组成的新的DStream。每个key的值都是它们在滑动窗口中出现的频率。
SS调优
通过spark-shell运行Spark Streaming + Kafka程序,查看Web UI界面
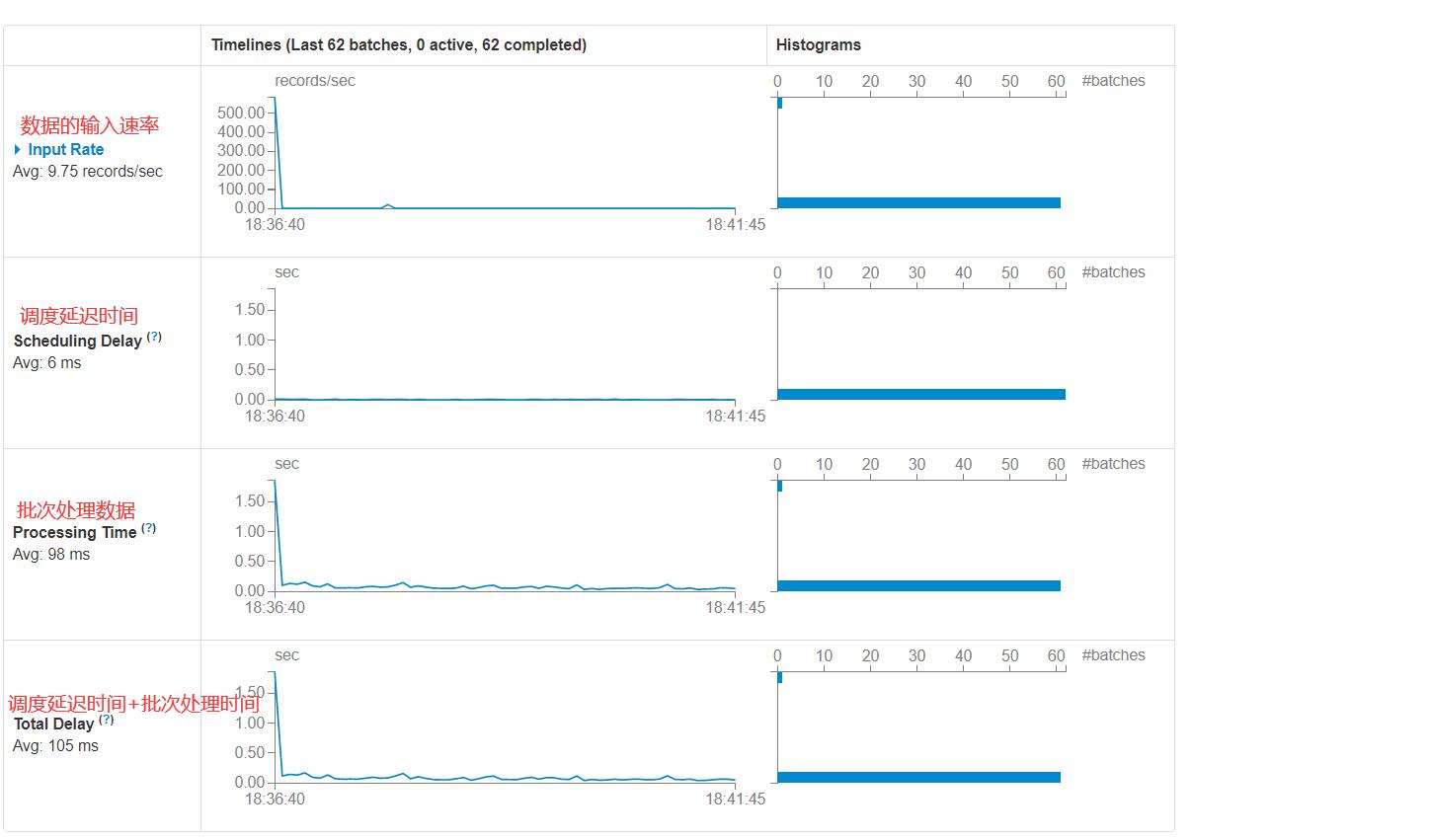
我们需要作业的性能最高,那么需要一个最佳时间
- 在下一个批次启动作业之前一定要运行完前一个批次数据的处理
- batch time: 根据需求来定的
影响任务运行时长的要素:
- 数据规模(增加kafka分区数==>增加Spark分区==>增加task)
- batch time
- 业务复杂度
kafka限速
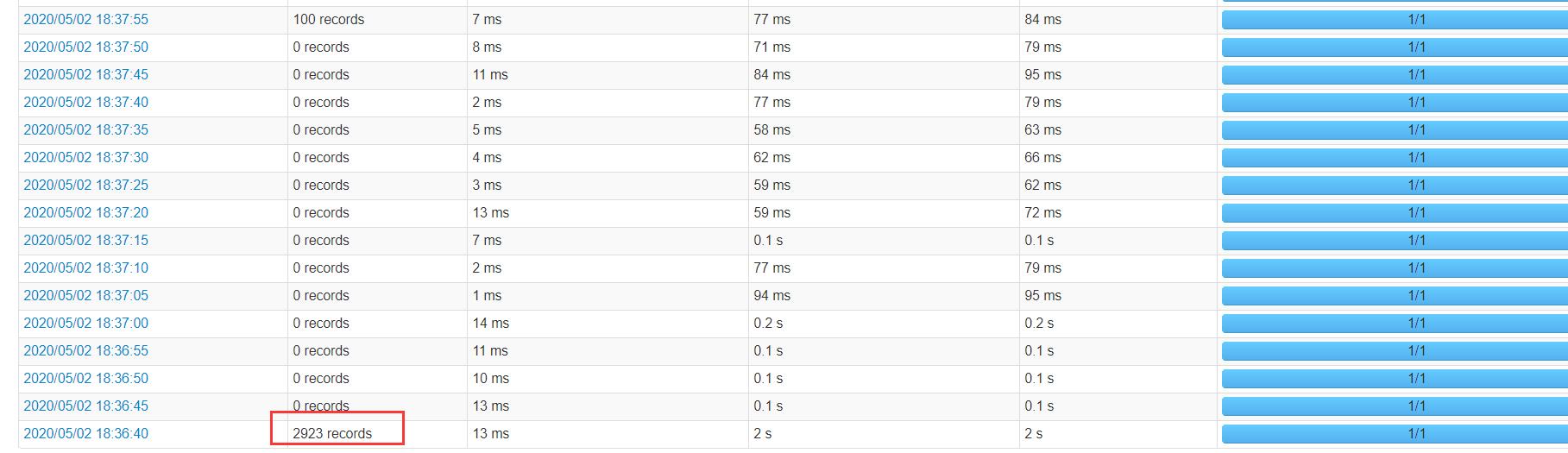
我们看到在设置auto.offset.reset = earliest后,即从头消费,如果累积的数据量特别大,那么在第一次消费的就会撑爆Kafka,必须限制每秒多少条数据
| Property Name | Default | Meaning |
|---|---|---|
spark.streaming.kafka.maxRatePerPartition |
not set | 每个Kafka分区读取数据的最大速率 |
在设置maxRatePerPartition的值时,数据量=设置的值*分区数*读取时间,加入设置的值为10,分区为3,读取时间为10s,那么每次出来的数据量: 10*3*10=300
优点
- 如果有很多数据量没有处理,并且从头开始,为了防止过载
- 高峰期限速,防止Kafka处理能力不够挂掉
缺点
- 是个固定值 ==> 背压(backpressure 1.5版本引入)
背压(backpressure ),在Spark1.5引入,它可以在运行时根据前一个批次数据的运行情况动态调整后续批次读入的数据量
打开参数:spark.streaming.backpressure.enabled
上限参数:spark.streaming.kafka.maxRatePerPartition
初始参数:spark.streaming.backpressure.initialRate
| Property Name | Default | Meaning |
|---|---|---|
spark.streaming.backpressure.enabled |
false | 使Spark流能够根据当前的批调度延迟和处理时间来控制接收速率,从而使系统接收的速度只取决于系统能够处理的速度。 |
spark.streaming.kafka.maxRatePerPartition |
not set | 每个Kafka分区读取数据的最大速率 |
spark.streaming.backpressure.initialRate |
not set | 启用背压机制时每个接收器接收第一批数据的初始最大接收速率 |
到此,Kafka数据量过载的问题完全解决
最后引入一个关于StreamingContext关闭时的参数
| Property Name | Default | Meaning |
|---|---|---|
spark.streaming.stopGracefullyOnShutdown |
false | 如果是“true”,Spark会在JVM关闭时优雅地关闭“StreamingContext”,而不是立即关闭。 |
其他调优可参考官网或者博客