
这篇文章接着从jdbc的角度解读外部数据源和自定义外部Text数据源
我想以简单的形式在Spark中读取Hbase数据,但是Spark并不支持读取Hbase数据后简单使用。思考能否自己实现这个读取的过程?
Hbase的读写API,结果数据往往需要处理后使用。我们是否可以将Hbase结果数据通过转化,直接转化为DataFrame的形式,方便我们使用。
总体思路可以分为几个步骤。
- 继承RelationProvider实现createRelation
- 继承BaseRelation和TableScan实现StructType和buildScan,分别用来获取Schema和RDD[Row]
- buildScan中需要思考如何去读取HBase的数据,如何把HBase的转成RDD[Row]
- 其他还有如何获取外面传进来的数据,以及怎么保存这些数据信息
准备工作
我们准备了一份稀疏数据,注意该案例目前只考虑到一个列族并且不考虑行键和时间戳
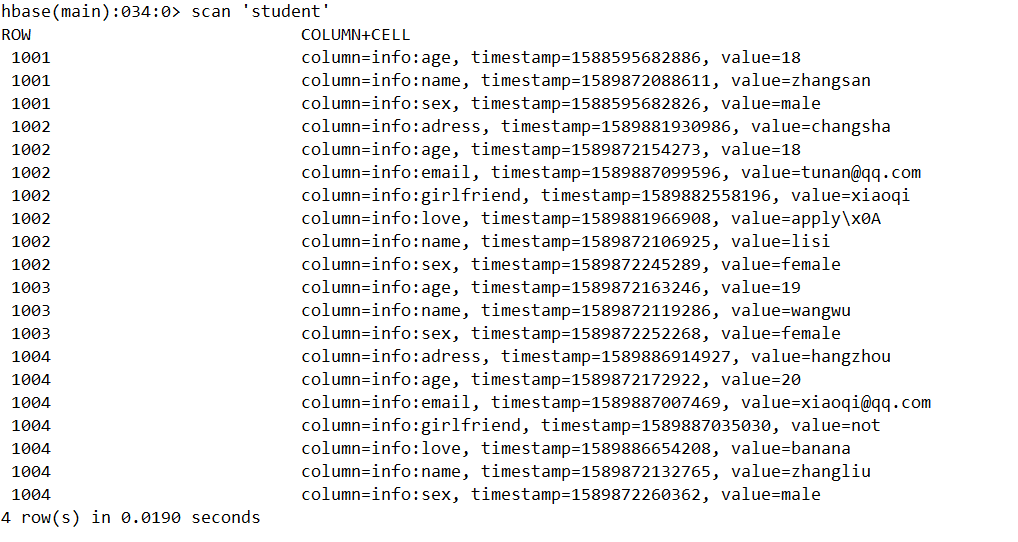
我们期望在经过Spark处理得到这么一份数据

如何自定义外部数据源的思以及源码我的其他博客已经介绍过了,我们无法就是干两件事,实现每个数据的StructType,实现StructType对应的RDD[Row]
自定义外部数据源
老套路,创建DefaultSource实现RelationProvider
class DefaultSource extends RelationProvider{
// 创建Relation
override def createRelation(sqlContext: SQLContext, parameters: Map[String, String]): BaseRelation = {
// 做一些检查性的工作,然后调用HbaseRelation
HbaseRelation(sqlContext,parameters)
}
}在创建HbaseRelation之前需要实现两个辅助类
/**
* 存储外部传入的Schema字段名和字段类型
* @param fieldName 字段名
* @param fieldType 字段类型
*/
case class SparkSchema(fieldName:String,fieldType:String)object HBaseDataSourceUtils {
/**
* 读取输入的字段类型做转换
* @param sparkTableScheme 外部传入的Schema
* @return
*/
def extractSparkFields(sparkTableScheme:String):Array[SparkSchema] = {
// 除去左右括号以及按逗号切分
val columns = sparkTableScheme.trim.drop(1).dropRight(1).split(",")
// 拿到切分后的每一对Schema
val sparkSchemas: Array[SparkSchema] = columns.map(x => {
val words = x.split(" ")
// 使用SparkSchema封装,这里拿什么封装无所谓,tuple都行
SparkSchema(words(0), words(1))
})
// 因为是map,所以返回的一个数组
sparkSchemas
}
}创建HbaseRelation继承BashRelation和TableScan实现StructType和buildScan
case class HbaseRelation(@transient sqlContext: SQLContext, @transient parameters: Map[String, String]) extends BaseRelation with TableScan {
// 拿到外部传入的hbase表名
private val hbaseTable: String = parameters.getOrElse("hbase.table.name", sys.error("hbase.table.name is required..."))
// 拿到外部传入的Schema
private val sparkTableSchema: String = parameters.getOrElse("spark.table.schema", sys.error("spark.table.schema is required..."))
// 拿到外部传入的zookeeper地址
private val zookeeperHostAndPort: String = parameters.getOrElse("spark.zookeeper.host.port", sys.error("spark.zookeeper.host.port is required..."))
// TODO 注意 这里可能还需要拿到传入的列族,以实现获取不同列族的数据
// 将传入的Schema信息传入extractSparkFields进行解析,返回一个SparkSchema数组
private val sparkFields: Array[SparkSchema] = HBaseDataSourceUtils.extractSparkFields(sparkTableSchema)
override def schema: StructType = {
// 拿到每一个SparkSchema
val rows: Array[StructField] = sparkFields.map(field => {
// 拿到SparkSchema中的fieldType做模式匹配,封装成我们需要的StructField
val structField = field.fieldType.toLowerCase match {
case "int" => StructField(field.fieldName, IntegerType)
case "string" => StructField(field.fieldName, StringType)
}
// 返回StructField
structField
})
// 使用的map,返回的一个structField数组,直接放入StructType对象中,即拿到最终的StructType
new StructType(rows)
}
/**
* 把HBase中的数据转成RDD[Row]
* 1)怎么样去读取HBase的数据
* 2)怎么样把HBase的转成RDD[Row]
*/
override def buildScan(): RDD[Row] = {
// 创建hbase配置文件
val hbaseConf = HBaseConfiguration.create()
// 设置zookeeper的地址
hbaseConf.set("hbase.zookeeper.quorum", zookeeperHostAndPort)
// 设置hbase的表名
hbaseConf.set(TableInputFormat.INPUT_TABLE, hbaseTable)
// 通过newAPIHadoopRDD拿到对应hbase表中的所有数据
val hbaseRDD: RDD[(ImmutableBytesWritable, Result)] = sqlContext.sparkContext.newAPIHadoopRDD(hbaseConf,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result])
// 拿到我们需要的Result
hbaseRDD.map(_._2).map(result => {
// 创建一个列表,类型且是Any的,方便后面转换成RDD[Row]
val buffer = new ArrayBuffer[Any]()
// 变量每一行数据
sparkFields.foreach(field => {
// 判断对应列族下的列有没有数据
if (result.containsColumn(Bytes.toBytes("info"), Bytes.toBytes(field.fieldName))) {
// 如果有,则拿到对应的数据,并且通过模式匹配,转换成对应的类型
field.fieldType match {
case "string" =>
val tmp: Array[Byte] = result.getValue(Bytes.toBytes("info"), Bytes.toBytes(field.fieldName))
// 加入buffer
buffer += new String(tmp)
case "int" =>
val tmp = result.getValue(Bytes.toBytes("info"), Bytes.toBytes(field.fieldName))
// 加入buffer
buffer += Integer.valueOf(new String(tmp))
}
} else {
// 如果没有数据,则对应字段直接存一个空
buffer += new String("")
}
})
// 得到最终的RDD[Row]
Row.fromSeq(buffer)
})
}
}SparkHBaseSourceApp类获取数据
object SparkHBaseSourceApp {
// 主类
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[2]")
.appName(this.getClass.getSimpleName)
.getOrCreate()
val df = spark.read.format("com.tunan.spark.sql.extds.hbase")
.option("hbase.table.name", "student")
.option("spark.table.schema", "(adress string,age int,email string,girlfriend string ,love string,name string,sex string)")
.option("spark.zookeeper.host.port", "hadoop:2181")
.option("spark.select.cf","info")
.load()
df.printSchema()
// df.show()
df.createOrReplaceTempView("student")
spark.sql("select * from student where age > 18").show(false)
}
}查看结果
