
有状态转化
依赖之前的批次数据或者中间结果来计算当前批次的数据,不断的把当前的计算和历史时间切片的RDD进行累计。
Spark Streaming中状态管理函数包括updateStateByKey和mapWithState,都是用来统计全局key的状态的变化的。它们以DStream中的数据进行按key做reduce操作,然后对各个批次的数据进行累加,在有新的数据信息进入或更新时。能够让用户保持想要的不论任何状状。
updateStateByKey
概念
updateStateByKey会统计全局的key的状态,不管又没有数据输入,它会在每一个批次间隔返回之前的key的状态。updateStateByKey会对已存在的key进行state的状态更新,同时还会对每个新出现的key执行相同的更新函数操作。如果通过更新函数对state更新后返回来为none(),此时刻key对应的state状态会被删除(state可以是任意类型的数据的结构)。
适用场景
updateStateByKey可以用来统计历史数据,每次输出所有的key值。例如统计不同时间段用户平均消费金额,消费次数,消费总额,网站的不同时间段的访问量等指标
使用实例
首先会以DStream中的数据进行按key做reduce操作,然后再对各个批次的数据进行累加 。
updateStateBykey要求必须要设置checkpoint点。
updateStateByKey 方法中 updateFunc就要传入的参数。
Seq[V]表示当前key对应的所有值,Option[S]是当前key的历史状态,返回的是新的封装的数据。
代码
object UpdateStateV2 { |
mapWithState
概念
mapWithState也会统计全局的key的状态,但是如果没有数据输入,便不会返回之前的key的状态,只会返回batch中存在的key值统计,类似于增量的感觉。
适用场景
mapWithState可以用于一些实时性较高,延迟较少的一些场景,例如你在某宝上下单买了个东西,付款之后返回你账户里的余额信息。
使用实例
如果有初始化的值得需要,可以使用initialState(RDD)来初始化key的值
还可以指定timeout函数,该函数的作用是,如果一个key超过timeout设定的时间没有更新值,那么这个key将会失效。这个控制需要在func中实现,必须使用state.isTimingOut()来判断失效的key值。如果在失效时间之后,这个key又有新的值了,则会重新计算。如果没有使用isTimingOut,则会报错。
checkpoint 不是必须的
代码
object MapWithState { |
updateStateByKey和mapWithState的区别
updateStateByKey可以在指定的批次间隔内返回之前的全部历史数据,包括新增的,改变的和没有改变的。由于updateStateByKey在使用的时候一定要做checkpoint,当数据量过大的时候,checkpoint会占据庞大的数据量,会影响性能,效率不高。
mapWithState只返回变化后的key的值,这样做的好处是,我们可以只是关心那些已经发生的变化的key,对于没有数据输入,则不会返回那些没有变化的key的数据。这样的话,即使数据量很大,checkpoint也不会像updateStateByKey那样,占用太多的存储,效率比较高(再生产环境中建议使用这个)。
SparkStreaming之mapWithState
与updateStateByKey方法相比,使用mapWithState方法能够得到6倍的低延迟的同时维护的key状态的数量要多10倍,这一性能的提升和扩展性可以从基准测试结果得到验证,所有的结果全部在实践间隔为1秒的batch和相同大小的集群中生成。
下图比较的是mapWithState方法和updateStateByKey方法处理1秒的batch所消耗的平均时间。在本例子中,我们为同样数量的的key(0.25-1百万)保存状态,然后以统一的速率(30个更新/s)对其进行更新。可以看到mapWithState方法比updateStateByKey方法快了8倍,从而允许更低的端到端的延迟。
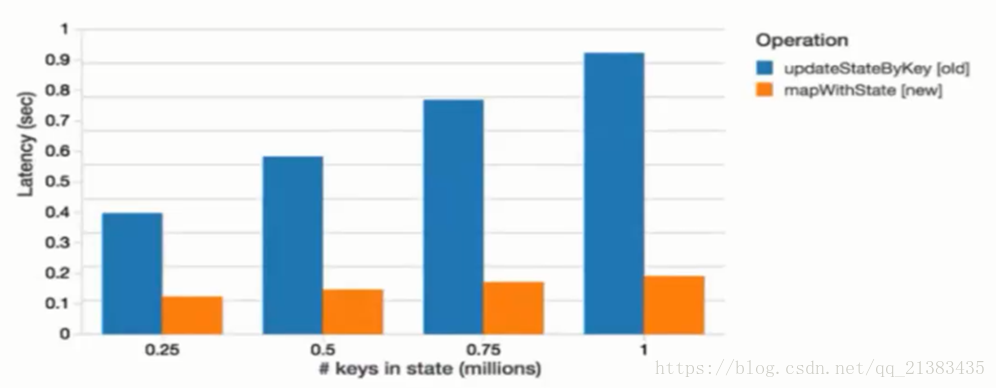
2020-11-06更新 以下仅仅提供参考 来源于http://sharkdtu.com/posts/spark-streaming-state.html
使用Redis管理状态
通过前面的分析,我们不使用Spark自身的缓存机制来存储状态,而是使用Redis来存储状态。来一批新数据,先去redis上读取它们的上一个状态,然后更新写回Redis,逻辑非常简单,如下图所示。
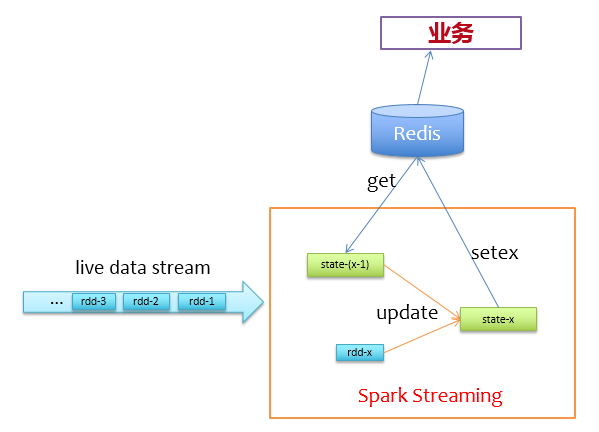
在实际实现过程中,为了避免对同一个key有多次get/set请求,所以在更新状态前,使用groupByKey对相同key的记录做个归并,对于前面描述的问题,我们可以先这样做:
val liveDStream = ... // (userId, clickId) |
为了减少访问Redis的次数,我们使用pipeline的方式批量访问,即在一个分区内,一个一个批次的get/set,以提高Redis的访问性能,那么我们的更新逻辑就可以做到mapPartitions里面,如下代码所示。
val updateAndflush = ( |
上述代码没有加容错等操作,仅描述实现逻辑,可以看到,函数mappingFunc会对每个分区的数据处理,实际计算时,会累计到batchSize才去访问Redis并更新,以降低访问Redis的频率。这样就不再需要cache和checkpoint了,程序挂了,快速拉起来即可,不需要从checkpoint处恢复状态,同时可以节省相当大的计算资源。
测试及优化选项
经过上述改造后,实际测试中,我们的batch时间为一分钟,每个batch约200W条记录,使用资源列表如下:
- driver-memory: 4g
- num-executors: 10
- executor-memory: 4g
- executor-cores: 3
每个executor上启一个receiver,则总共启用10个receiver收数据,一个receiver占用一个core,则总共剩下102=20个core可供计算用,通过调整如下参数,可控制每个batch的分区数为 10(601000)/10000=60(10个receiver,每个receiver上(601000)/10000个分区)。
spark.streaming.blockInterval=10000 |
为了避免在某个瞬间数据量暴增导致程序处理不过来,我们可以对receiver进行反压限速,只需调整如下两个参数即可,其中第一个参数是开启反压机制,即使数据源的数据出现瞬间暴增,每个receiver在收数据时都不会超过第二个参数的配置值,第二个参数控制单个receiver每秒接收数据的最大条数,通过下面的配置,一分钟内最多收 10605000=300W(10个receiver,每个receiver一分钟最多收60*5000)条。
spark.streaming.backpressure.enabled=truespark.streaming.receiver.maxRate=5000 |
如果程序因为机器故障挂掉,我们应该迅速把拉重新拉起来,为了保险起见,我们应该加上如下参数让Driver失败重试4次,并在相应的任务调度平台上配置失败重试。
spark.yarn.maxAppAttempts=4 |
此外,为了防止少数任务太慢影响整个计算的速度,可以开启推测,并增加任务的失败容忍次数,这样在少数几个任务非常慢的情况下,会在其他机器上尝试拉起新任务做同样的事,哪个先做完,就干掉另外那个。但是开启推测有个条件,每个任务必须是幂等的,否则就会存在单条数据被计算多次。
spark.speculation=truespark.task.maxFailures=8 |
经过上述配置优化后,基本可以保证程序7*24小时稳定运行,实际测试显示每个batch的计算时间可以稳定在30秒以内,没有上升趋势。