
目标
- 为什么是离线数据仓库
- 采集什么日志
- 技术实现流程
为什么是离线数据仓库
什么是数据仓库
将多个数据源的数据经过ETL之后,按照一定的主题继承,提供 决策支持 和 联机分析应用 的结构化数据环境
为什么要建数据仓库
摆脱多种不同数据源、异构数据库、不同数据格式等等带来的问题
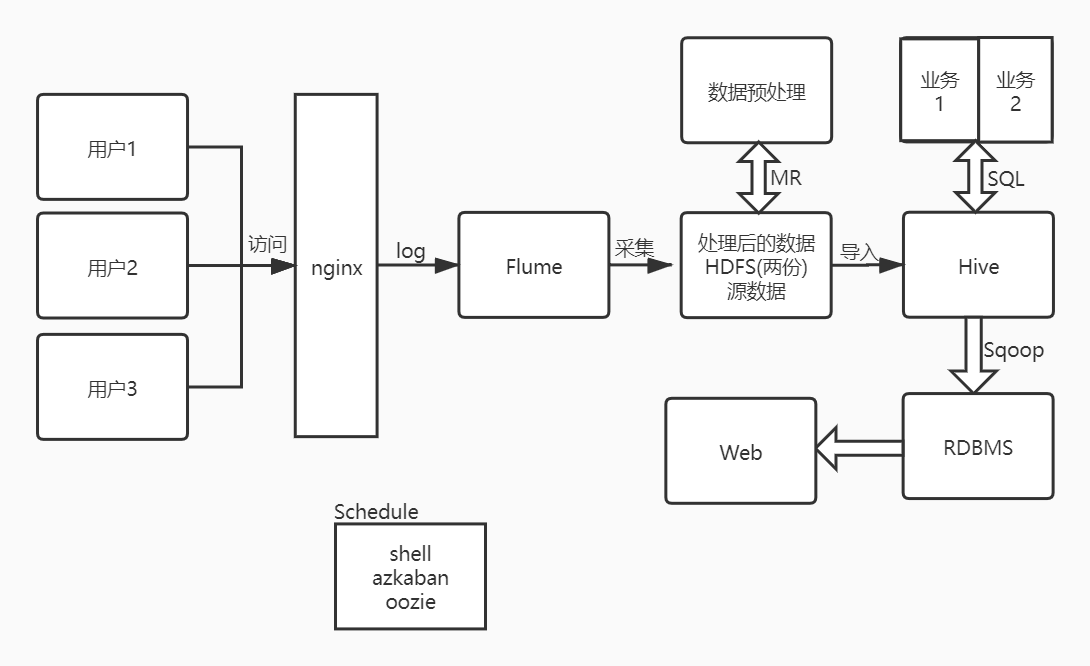
采集用户行为日志
既然要建数据仓库,那么第一步需要考虑的是我们的数据从哪里来?来的什么数据?这些数据是做什么的?
数据是从哪里来的?
数据通过采集团队从ngnix服务器(请求携带的数据经过nginx服务器)、埋点日志(用户行为过程及结果的记录)和SDK(软件开发工具包)通过flume采集产生的数据到HDFS上
来的是什么数据?
采集到的是用户的行为数据,包括日志和业务数据,只要是用户访问、搜索、点击、收藏都会产生数据通过flume采集到了HDFS上
数据可以用来做什么的?
数据运用在数据仓库中会进行一系列的ETL、调度、建模,最终用来可视化分析。
技术实现流程
数据采集
从输入==>到输出
可以使用的工具:
- SDK
- Flume(推介)
- Sqoop
- DataX
数据预处理
数据预处理也就是对数据进行ETL/清洗操作
- 格式处理:时间、IP、URL
- 数据拆分:1 col ==> n cols (URL、UA)
- 数据补充:1 col ==> n cols
数据入库
数据清洗后的数据导入到你HIVE中的库/表中(大宽表/N多列)
- 分析的维度:day or hour
- 表:分区外部表
数据分析
根据不同业务的执行SQL并且通过SQOOP存到RDBMS/NoSQL的表中
数据展示
- WEB ==> RDBMS
- Echarts
- d3
- HUE
- Zeppelin
项目架构
集群规划
评估你这个业务线需要多少资源,数据量的计算: 一条数据的大小==>*用户数*每个人一天产生的数据量==>*副本数*天数(365)==>*每年30%的上升空间
每个节点磁盘多少?内存多少?物理核多少?通过计算得出需要的节点数
core:32/64 决定了应用程序的快慢
memory:256/512 决定了应用程序的生死
disk:10T*数量
作业
对数据进行ETL操作时,N个业务:至少是3*N个SQL(3层),并且尽可能把一些麻烦的/繁琐的/join等SQL操作提前进行