
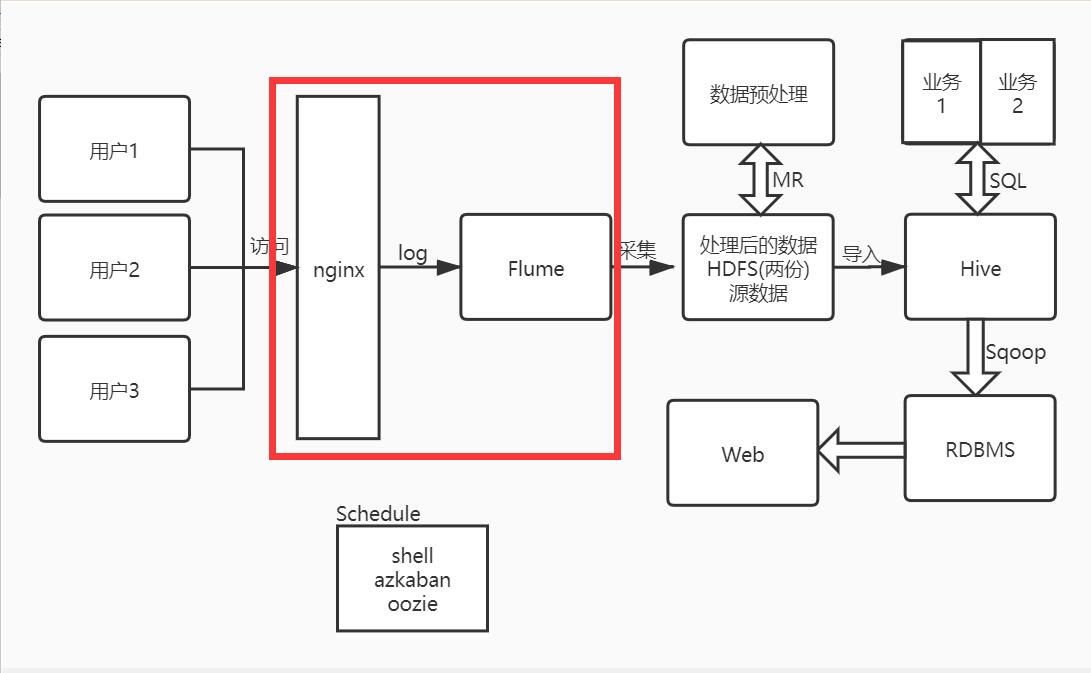
系统架构图:
目标
Flume是用来做什么的
为什么要使用Flume
Flume具体怎么用
java客户端上传消息到Flume写到HDFS
解决Flume采集数据时生成大量小文件的问题
为什么要使用Flume
在开源框架的选择中,因为Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. 所以我们选择了Flume作为数据的采集工具
Flume是用来做什么的
从系统架构图上来看,用户只要产生行为,那么日志就会在Nginx服务器中保存,所以我们现在要做的就是把数据从Nginx服务器中使用Flume采集到HDFS上
Flume具体怎么用
Flume
Flume就是一个针对日志数据进行采集和汇总的一个框架
Flume的进程叫做Agent,每个Agent中有Srouce、Channel、Sink
Flume从使用层面来讲就是写配置文件,其实就是配置我们的Agent,只要学会从官网查配置就行了
Agent
Source中的常用方式有 avro、exec、spooling、taildir、kafka
Channel中的常用方式有 memory、kafka、file
Sink中的常用方式有 hdfs、logger、avro、kafka
示例配置
它描述了一个单节点Flume部署。该配置允许用户生成事件,然后将它们记录到控制台。以后写配置只需要在这个配置文件的基础上做出选择性的修改即可
# Name the components on this agent |
有了这个配置文件,我们可以按如下方式启动Flume:
flume-ng agent \ |
输入端:
telnet localhost 44444 |
TAILDIR
taildir是Source端可以选择的一个类型,它可以同时支持目录和文件,并且支持offset,Flume挂了重启后可以接着上次消费的地方继续消费,下面提供一个配置taildir的文件
# Describe/configure the source |
其中taildir_position.json文件是用来记录文件读取offset的位置,方便下次继续从offset位置读取
注意taildir_position.json文件不能存在上级目录,不然会报错
java客户端上传消息到Flume写到HDFS
参考博客: https://blog.csdn.net/lbship/article/details/85336555
在java客户端编写代码生成logger数据
添加依赖
<dependency>
<groupId>org.apache.flume.flume-ng-clients</groupId>
<artifactId>flume-ng-log4jappender</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>org.apache.flume.flume-ng-clients</groupId>
<artifactId>flume-ng-log4jappender</artifactId>
<version>1.6.0</version>
</dependency>生产日志
private static Logger logger = Logger.getLogger(LoggerGenerator.class.getName());
public static void main(String[] args) throws InterruptedException {
int i = 0;
while(i<99){
Thread.sleep(500);
logger.info("now is : "+i);
i++;
}
}在log4j.properties文件中添加代码
log4j.rootCategory=info,console,flume //rootCategory需要指定flume
log4j.appender.flume=org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname=121.196.220.143
log4j.appender.flume.Port=41414
log4j.appender.flume.UnsafeMode=true在Hostname服务端接收log4j.properties文件中指定的端口即可,注意Source类型需要使用avro(序列化)
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414写出到HDFS,这里需要注意解决时间戳和乱码问题
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /flume/%y-%m-%d/%H%M/%S #时间需要根据实际情况修改
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.useLocalTimeStamp=true #解决时间戳问题
a1.sinks.k1.hdfs.fileType=DataStream #解决乱码使用
useLocalTimeStamp=true参数解决时间戳异常,使用fileType=DataStream解决文件内容乱码问题
解决Flume采集数据时生成大量小文件的问题
在使用Flume采集数据时,由于默认参数的影响会生产大量小文件,我们先看默认参数
hdfs.rollInterval 30 滚动当前文件之前要等待的秒数 |
我们看到默认生成文件有三个条件,每30秒、每1M、每10个events,这样的配置会生成大量的小文件,所以我们要对这三个文件进行修改
最终生成的文件必须综合时间、文件大小、event数量来决定,时间太长或者文件太大都不利于最终生成的文件。该时间还需要配合hdfs.path参数指定的生成文件时间。
注意sink.type如果是memory模式,注意文件的大小,防止内存不足,太大可以设置sink.type = file