
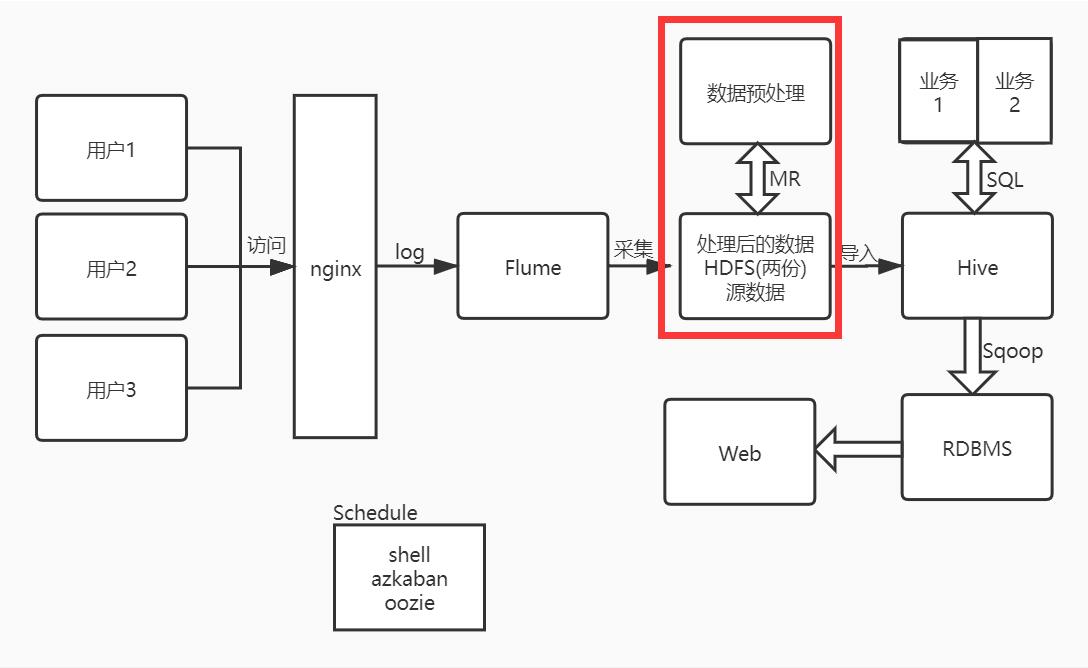
系统架构图:
目标
为什么要进行ETL
什么是ETL
ETL该怎么做
ETL在服务器上运行需要解决的问题
为什么要进行ETL
在上一步我们使用Flume采集数据到HDFS,从系统架构图来看现在要进行数据的ETL操作,ETL进程对数据进行规范化、验证、清洗,并最终装载进入数据仓库
什么是ETL
ETL 即 Extract Transform Load的首字母 ==> 抽取、转换、加载
ETL该怎么做
数据采集到HDFS上指定的目录下,通过MR写入数据,进行ETL操作,并写出到指定的目录下,ETL操作包括定义数据字段的序列化类,把时间解析出年月日,把URL解析为http、domain和path、对异常值进行处理(try/catch),使用计数器。
需要注意:
时间解析参考代码
//时间
String time = split[0];
SimpleDateFormat format = new SimpleDateFormat("[dd/MM/yyyy:HH:mm:ss +0800]");
Date date = format.parse(split[0]);
Calendar calendar = Calendar.getInstance();
calendar.setTime(date);
//year
String year =String.valueOf(calendar.get(Calendar.YEAR));
access.setYear(year);
//month
int month = calendar.get(Calendar.MONTH)+1;
access.setMont(month < 10 ? "0"+month:String.valueOf(month))
//day
int day = calendar.get(Calendar.DAY_OF_MONTH);
access.setDay(day < 10 ? "0"+day:String.valueOf(day));异常值是舍去还是保留,这跟try/catch如何操作有关系,参考代码
//要数据,设默认值为0
long responseSize = 0L;
try {
responseSize = Long.parseLong(split[9].trim());
access.setResponseSize(responseSize);
} catch (Exception e) {
access.setResponseSize(responseSize);
}
// 不要数据,产生异常直接返回
Long responseSize = Long.parseLong(split[9].trim());
access.setResponseSize(responseSize);计数器mapper中的参考代码
context.getCounter("ETL","SUCCEED").increment(1);
计数器Driver中的参考代码
//通过迭代器获取mapper中的计数器
CounterGroup group = job.getCounters().getGroup("ETL");
Iterator<Counter> iterator = group.iterator();
while(iterator.hasNext()){
Counter counter = iterator.next();
System.out.println(counter.getName() + "==>" + counter.getValue());
}注意: 这里可以通过jdbc将计数器结果根据批次写到mysql数据库中
ETL在服务器上运行需要解决的问题
在本地测试好代码后,上传Jar包到服务器上,跑HDFS上的数据
首先创建三个文件夹lib、data、script放ETL相关的文件,运行脚本的shell文件就在script目录下
由于我们把ETL打的瘦包,所以很多数据需要的依赖Jar包得不到,还有ip解析库的数据库也需要上传到本地文件下
思路是:
把ip解析库放到项目的resources目录下
把需要的依赖上传到lib目录下
在
~/.bashrc文件下导入LIBJARS路径用来指向lib目录下的依赖export LIBJARS=/home/hadoop/lib/LIBJARS
export LIBJARS=$LIBJARS/commons-lang3-3.4.jar,$LIBJARS/qqwry.dat,$LIBJARS/mysql-connector-java-5.1.27-bin.jar执行jar包命令写进脚本,执行脚本即可
time=20200217
hadoop jar hadoop-client-1.0.0.jar com.tunan.ip.ipParseDriver -libjars $LIBJARS /item/offline-dw/raw/access/$time /item/offline-dw/tmp/access/$time/-libjars用来指定外部依赖,$LIBJARS指向~/.bashrc文件中的路径/item/offline-dw/raw/access/$time是源数据,这个数据一般保存7天后即可删除/item/offline-dw/tmp/access/$time/是ETL后的数据$LIBJARS/qqwry.dat是ip解析库的路径还可以把ip解析库在服务器上的路径写死在代码中,就不用手动指定ip解析库的路径了