
系统架构图:
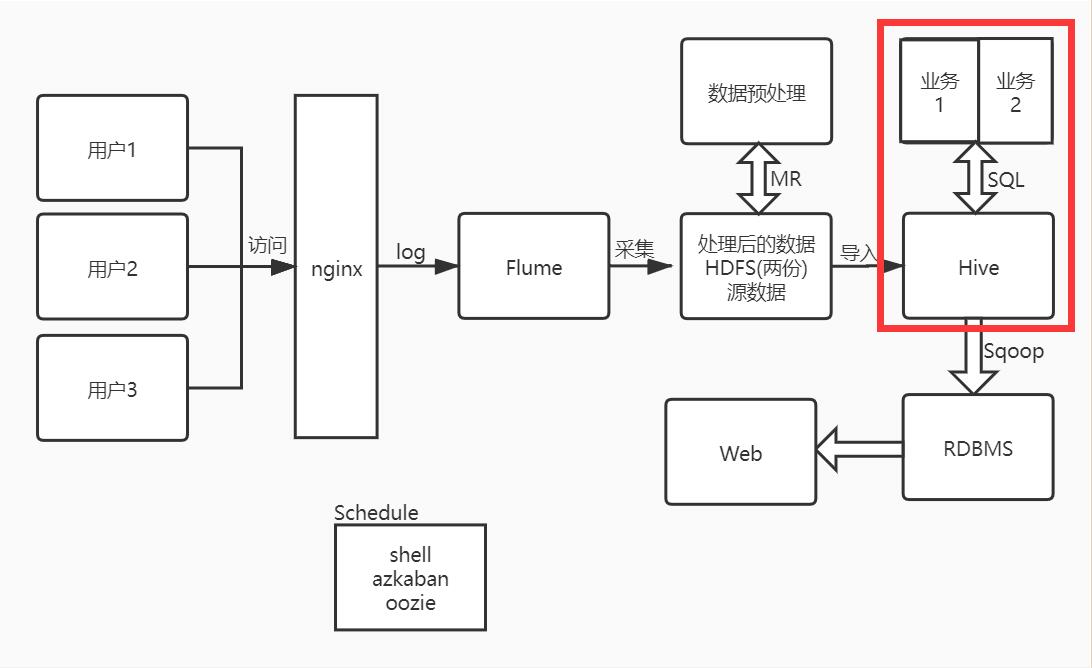
目标
- 数据仓库为什么要分层
- 数据仓库如何分层
- 使用脚本将数据执行分层
- 数据分析案例
- 使用crontab调度脚本(临时)
数据仓库为什么要分层
分层的主要原因是在管理数据的时候,能对数据有一个更加清晰的掌控,详细来讲,主要有下面几个原因:
清晰数据结构,每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。数据血缘追踪,简单来说,我们最终给业务呈现的是一个能直接使用业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。减少重复开发,规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。把复杂问题简单化,将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。屏蔽原始数据的异常屏蔽业务的影响,不必改一次业务就需要重新接入数据
数据仓库如何分层
数据仓库的分层标准: 不为分层而分层
标准的分层
- ODS:
数据原始层: 直接加载原始数据,不做任何处理(不做ETL) - DWD:
数据明细层,对ODS层进行清洗(ETL) - DWS:
数据服务层,基于DWD做统计分析 - ADS:
数据应用层,为各种统计报表提供数据
我们的分层
- ODS(operate data store):
数据原始层,最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的ETL之后,装入本层 - DWS(data warehouse server):
数据明细层,从ODS层中获得的数据按照主题建立各种数据模型。在这里,我们需要了解四个概念:维(dimension)、事实(Fact)、指标(Index)和粒度( Granularity)。 - ADS:
数据应用层,该层主要是提供数据产品和数据分析使用的数据。 比如我们经常说的报表数据,或者说那种大宽表,一般就放在这里。
使用脚本将数据执行分层
现在我们知道了数据需要在Hive中分成ODS层、DWS层和ADS层,每一层的建表标准是ods_、dws_、ads_
建库
create database if not exists offline_dw;
建ODS层外部分区表
create external table ods_access(
`year` String,
`month` String,
`day` String,
country String,
province String,
city String,
area String,
proxyIp String,
responseTime BigInt,
referer String,
`method` String,
http String,
`domain` String,
`path` String,
httpCode String,
requestSize BigInt,
responseSize bigInt,
cache String,
userId BigInt
)
partitioned by(d String)
row format delimited
fields terminated by "\t"
location "/item/offline-dw/ods/access/";写脚本(etl.sh)
- 使用MR通过ETL把源数据写入ODS临时目录
- 把ODS临时目录中
part*开头的数据移动到ODS分区目录下,并指定分区 - 接着Hive执行命令新建分区
! /bin/bash
if [ $# -eq 1 ];then
time=$1
else
time=`date --date "1 days ago" +%Y%m%d`
fi
MR做ETL 注意输入和输出(带时间)
hadoop jar /home/hadoop/lib/hadoop-client-1.0.0.jar com.tunan.item.ETLDriver -libjars $LIBJARS /item/offline-dw/raw/access/$time /item/offline-dw/ods_tmp/access/$time
删除分区目录(d=时间)
hdfs dfs -rm -r -f /item/offline-dw/ods/access/d=$time
创建分区目录(d=时间)
hdfs dfs -mkdir -p /item/offline-dw/ods/access/d=$time
ods_tmp移动数据到ods((时间目录下的part* d=时间))
hdfs dfs -mv /item/offline-dw/ods_tmp/access/$time/part* /item/offline-dw/ods/access/d=$time
删除ods_tmp(带时间)
hdfs dfs -rm -r -f /item/offline-dw/ods_tmp/access/$time
hive命令行刷新分区 (判断表是否存在,partition(d="$time"))
hive -e "alter table offline_dw.ods_access add if not exists partition(d=$time)"
数据分析案例(DWS/ADS层)
这层的数据可以作为DWS层,我们要什么数据就建什么表(分区)
统计国家流量
思路: 建分区表,字段分别是国家和流量,最后分组查询,插入表中
建表
create external table dws_country_traffic(
country String,
traffic BigInt
)
partitioned by(d String)
row format delimited
fields terminated by "\t";查询数据插入表中
insert overwrite table offline_dw.dws_country_traffic partition(d='$time')
select country,sum(responseSize) from offline_dw.ods_access where d = '$time'group by country;
统计域名流量
思路: 建分区表,字段分别是域名和流量,最后分组查询,插入表中
建表
create external table dws_domain_traffic(
domain String,
traffic BigInt
)
partitioned by(d String)
row format delimited
fields terminated by "\t";查询数据插入表中
insert overwrite table offline_dw.dws_domain_traffic partition(d='$time')
select domain,sum(responseSize) from offline_dw.ods_access where d='$time'group by domain;
写成脚本方便调度
! /bin/bash
if [ $# -eq 1 ];then
time=$1
else
time=`date --date '1 days ago' +%Y%m%d`
fi
hive -e "insert overwrite table offline_dw.dws_country_traffic partition(d='$time')
select country,sum(responseSize) from offline_dw.ods_access where d='$time' group by country;"
hive -e "insert overwrite table offline_dw.dws_domain_traffic partition(d='$time')
select domain,sum(responseSize) from offline_dw.ods_access where d='$time' group by domain;"
使用crontab调度脚本(临时)
每天凌晨一点执行etl.sh,每天凌晨两点执行stats.sh
crontab -e |