
原文:https://blog.cloudera.com/orcfile-in-hdp-2-better-compression-better-performance/
即将发布的Hive 0.12将在存储层带来一些新的重大改进,包括更高的压缩和更好的查询性能。
高压缩
ORCFile是在Hive 0.11中引入的,提供了很好的压缩,通过一些技术来实现,包括运行长度编码、字符串字典编码和位图编码。
这种对效率的关注导致了一些令人印象深刻的压缩比。这张图片显示了TPC-DS数据集在不同编码下的规模为500。该数据集包含随机生成的数据,包括字符串、浮点数和整数数据。

我们已经看到,有些客户的集群已经从存储的角度扩展到了ORCFile,这是一种释放空间的方法,同时与现有的作业100%兼容。
存储在ORCFile中的数据可以通过HCatalog读取或写入,因此任何Pig或Map/Reduce进程都可以无缝地运行。Hive 12 建立在这些令人印象深刻的压缩比上,并在Hive和执行层提供深度集成来加速查询,从处理更大的数据集和更低的延迟的角度来看都是如此。
谓词下推
SQL查询通常会有一些WHERE条件,可以用来方便地排除需要考虑的行。在旧版本的Hive中,在稍后通过SQL处理消除之前,将行从存储层中读取出来。有很多浪费的开销,Hive 12通过允许将谓词下推并在存储层本身进行计算来优化这一点。它是由环境控制的hive.optimize.ppd=true.
这需要读者具有足够的智慧来理解谓词。幸运的是,ORC已经进行了相应的改进,允许将谓词推入其中,并利用其内联索引提供性能优势。
例如,如果你有一个SQL查询:
SELECT COUNT(*) FROM CUSTOMER WHERE CUSTOMER.state = ‘CA’; |
ORCFile只返回与WHERE谓词实际匹配的行,而跳过驻留在任何其他状态的客户。从表中读取的列越多,要避免的数据封送处理就越多,速度也就越快。
ORCFile内联索引
在进入下一节之前,我们需要花一点时间讨论ORCFile如何将行分解为行组,并在这些行组中应用列式压缩和索引。
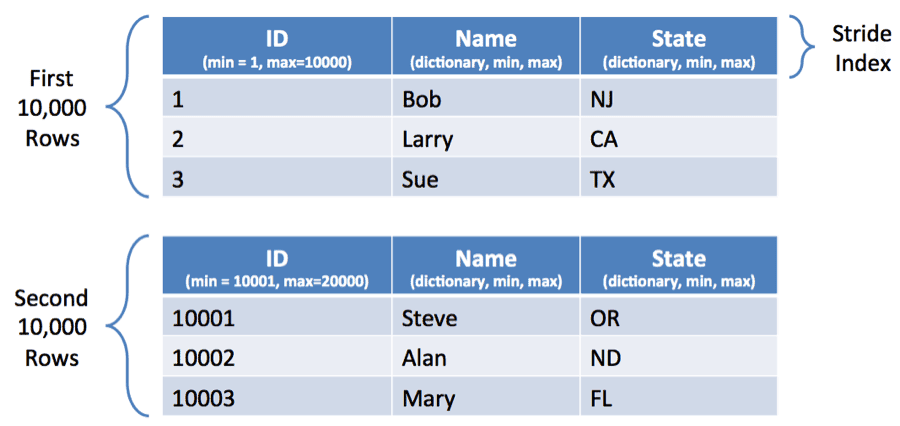
ORC的谓词下推将参考内联索引,以尝试确定何时可以一次性跳过整个块。有时,您的数据集自然会促进这一点。例如,如果您的数据是一个时间序列,并且时间戳是单调递增的,那么当您在这个时间戳上加上where条件时,ORC将能够跳过许多行组。
在其他情况下,可能需要对数据进行排序。如果对一列进行排序,相关记录将被限制在磁盘上的一个区域,其他部分将很快被跳过。
对于数字类型和字符串类型,跳过可以工作。在这两个实例中,都是通过在内联索引中记录一个最小值和一个最大值并确定查找值是否落在这个范围之外来完成的。
排序可以导致非常好的加速。这里有一个权衡,您需要提前决定对哪些列排序。决策过程在某种程度上类似于决定在传统SQL系统中索引哪些列。最好的回报是您拥有一个经常使用的列,并且在非常特定的条件下访问它,并且在很多查询中使用它。请记住,您可以在创建表时设置hive.enforce.sorting=true并使用SORT BY关键字强制Hive对列进行排序。
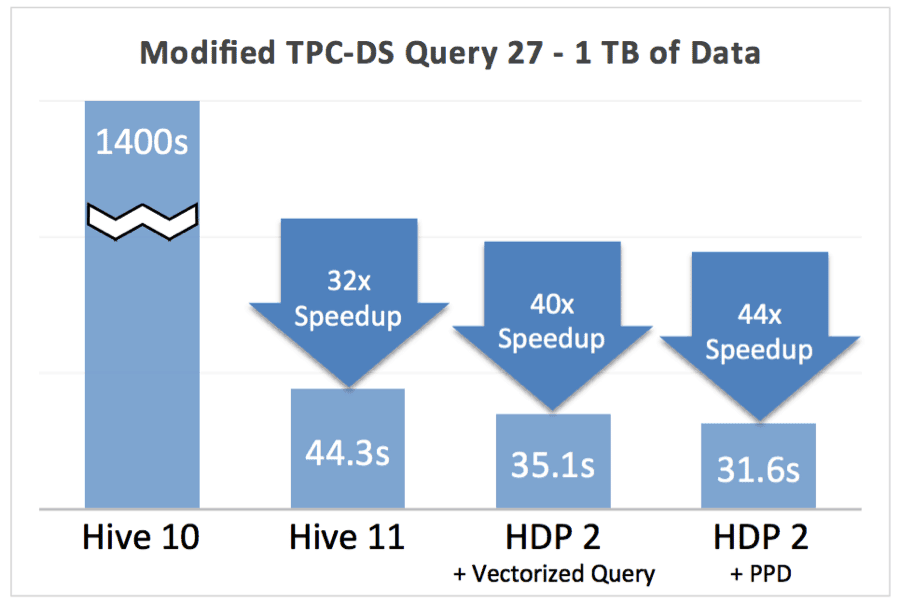
ORCFile是我们的一个重要的刺激举措,以提高Hive性能100倍。为了显示影响,我们使用修改后的数据模式运行修改后的TPC-DS查询27。查询27在一个大型事实表上执行星型模式连接,访问4个独立的维度表。在修改后的模式中,销售的状态被反规范化为事实表,结果表按状态排序。通过这种方式,当查询扫描事实表时,它可以跳过整个行块,因为查询根据状态进行筛选。这导致了一些增量加速,正如您可以从下面的图表中看到的。
这个功能给你最好的性价比时:
在具有中等到较大基数的列上,您经常以一种精确的方式过滤大型事实表。
您可以选择大量的列,或者宽列。您保存的数据封送处理越多,您的加速就越大。
使用ORCFile
使用ORCFile或将现有数据转换为ORCFile非常简单。要使用它,只需添加存储为orc到您的create table语句的结尾,如下所示:
CREATE TABLE mytable ( |
若要将现有数据转换为ORCFile,请创建一个与源表具有相同模式并存储为orc的表,然后可以使用如下查询:
INSERT INTO TABLE orctable SELECT * FROM oldtable; |
Hive将处理所有细节的ORCFile转换,你可以自由删除旧表,以释放大量的空间。
创建ORC表时,可以使用许多表属性进一步优化ORC的工作方式。
| Key | Default | Notes |
|---|---|---|
orc.compress |
ZLIB |
压缩除使用列式压缩外,还可以使用NONE, ZLIB, SNAPPY |
orc.compress.size |
262,144 (= 256 KiB) |
每个压缩块中的字节数 |
| orc.stripe.size | 268,435,456 (= 256 MiB) |
每条数据中的字节数 |
orc.row.index.stride |
10,000 |
索引项之间的行数 (必须 >= 1,000) |
orc.create.index |
true |
是否创建内联索引 |
例如,假设您想使用snappy压缩而不是zlib压缩。方法如下:
CREATE TABLE mytable ( |