
原文:https://databricks.com/blog/2015/07/15/introducing-window-functions-in-spark-sql.html
在这篇博客文章中,我们将介绍Apache Spark 1.4中添加的新窗口函数特性。窗口函数允许Spark SQL的用户计算结果,比如给定行的秩或输入行的范围内的移动平均值。它们显著提高了Spark的SQL和DataFrame api的表达能力。本博客将首先介绍窗口函数的概念,然后讨论如何与Spark SQL和Spark的DataFrame API一起使用它们。
什么是窗口函数?
在1.4之前,Spark SQL支持两种函数,可用于计算单个返回值。内置函数或udf(如substr或round)将单个行中的值作为输入,并为每个输入行生成单个返回值。聚合函数(如SUM或MAX)对一组行进行操作,并为每个组计算单个返回值。
虽然这两种方法在实践中都非常有用,但是仍然有大量的操作不能单独使用这些类型的函数来表示。具体来说,无法同时对一组行进行操作,同时仍然为每个输入行返回一个值。这种限制使得执行各种数据处理任务(如计算移动平均值、计算累计和或访问当前行之前的行值)变得非常困难。幸运的是,对于Spark SQL的用户来说,窗口函数填补了这一空白。
在其核心,一个窗口函数根据一组行(称为Frame)为表的每个输入行计算一个返回值。每个输入行都可以有一个与之关联的唯一frame。窗口函数的这种特性使它们比其他函数更强大,并允许用户以简洁的方式表达各种数据处理任务,而这些任务如果没有窗口函数是很难(如果不是不可能)表达的。现在,让我们看两个例子。
假设我们有一个如下所示的productRevenue表。
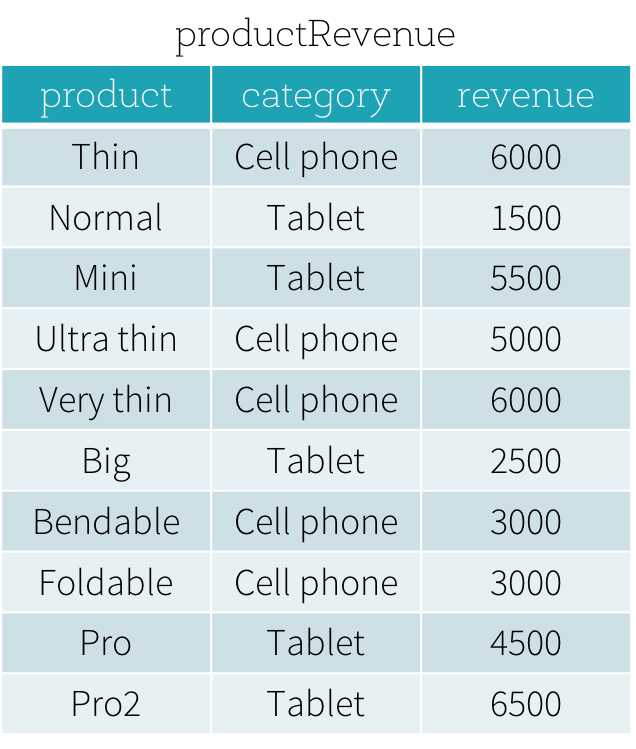
我们想回答两个问题:
每一类中最畅销和第二畅销的产品是什么(分组top n)?
每种产品的收入和同类产品中最畅销的产品的收入有什么不同(最大值 - 当前值)?
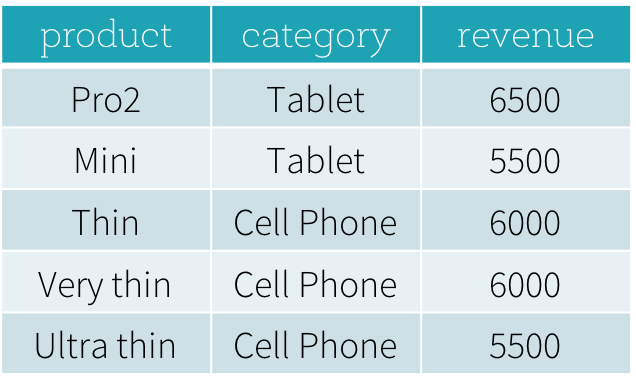
回答第一个问题“在每个类别中,最畅销和第二畅销的产品是什么?”,我们需要根据产品的收入对其进行分类,并根据排名选择最畅销和第二畅销的产品。下面是通过使用窗口函数dense_rank来回答这个问题的SQL查询(我们将在下一节中解释使用窗口函数的语法)。
SELECT |
这个查询的结果如下所示。如果不使用窗口函数,就很难用SQL表达查询,即使可以表达SQL查询,底层引擎也很难有效地评估查询。
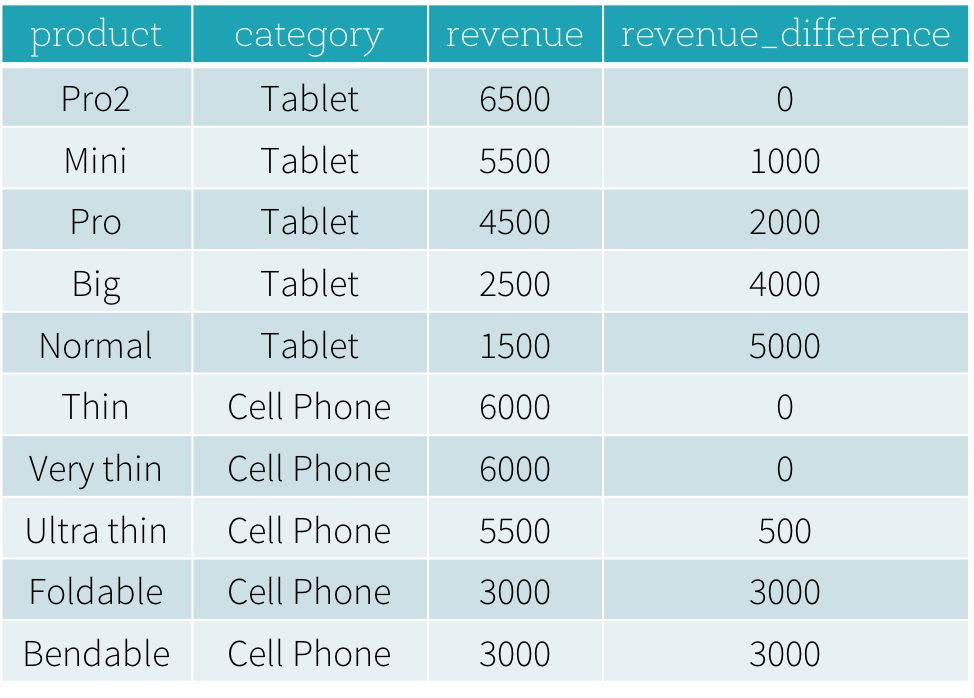
对于第二个问题,“每种产品的收入与同类产品中最畅销的产品的收入有什么不同?”,要计算一个产品的收入差异,我们需要找到每个产品在相同类别下的最高收入价值。下面是一个用于回答这个问题的Python DataFrame程序(python代码不重要,看思路)。
import sys |
这个程序的结果如下所示。在不使用窗口函数的情况下,用户必须找到所有类别的所有最高收入值,然后将这个派生的数据集与原始的productRevenue表连接起来,以计算收入差异。
使用窗口函数
Spark SQL支持三种窗口函数:排序函数、分析函数和聚合函数。可用的排序函数和分析函数总结如下表所示。对于聚合函数,用户可以使用任何现有的聚合函数作为窗口函数。
| SQL | DataFrame API | |
|---|---|---|
| Ranking functions | rank | rank |
| dense_rank | denseRank | |
| percent_rank | percentRank | |
| ntile | ntile | |
| row_number | rowNumber | |
| Analytic functions | cume_dist | cumeDist |
| first_value | firstValue | |
| last_value | lastValue | |
| lag | lag | |
| lead | lead |
要使用窗口函数,用户需要标记一个函数被任意一方用作窗口函数
- 在SQL中支持的函数后添加OVER子句,例如
avg(revenue) OVER (...); - 调用DataFrame API中支持的函数上的over方法,例如
rank().over(...)
一旦一个函数被标记为一个窗口函数,下一个关键步骤就是定义与这个函数相关的窗口规范。窗口规范定义在与给定输入行关联的frame中包含哪些行。一个窗口规范包括三个部分:
分区规范:控制哪些行将与给定行位于同一分区中。此外,在订购和计算frame之前,用户可能希望确保将category列具有相同值的所有行收集到相同的机器上。如果没有给出分区规范,那么所有数据必须收集到一台机器上。
排序规范:控制分区中的行排序的方式,确定给定行在其分区中的位置。
Frame规范:根据当前输入行的相对位置,声明当前输入行的frame中包含哪些行。例如,“当前行之前的三行到当前行”描述了一个frame,其中包括当前输入行和出现在当前行之前的三行。
在SQL中, PARTITION BY 和 ORDER BY 关键字分别用于为分区规范指定分区表达式和为排序规范指定排序表达式。SQL语法如下所示。
OVER (PARTITION BY ... ORDER BY ...) |
在DataFrame API中,我们提供了实用程序函数来定义窗口规范。以Python为例,用户可以按如下方式指定分区表达式和排序表达式。
from pyspark.sql.window import Window |
除了排序和分区之外,用户还需要定义frame的开始边界、frame的结束边界和frame的类型,这是frame规范的三个组成部分。
边界有UNBOUNDED PRECEDING, UNBOUNDED FOLLOWING, CURRENT ROW, PRECEDING,和<value> FOLLOWING五种类型。 <value> FOLLOWING. UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING分别表示分区的第一行和最后一行。对于其他三种类型的边界,它们指定当前输入行的位置偏移量,并根据框架的类型定义它们的特定含义。有两种类型的frame,ROW frame 和RANGE frame.
ROW frame
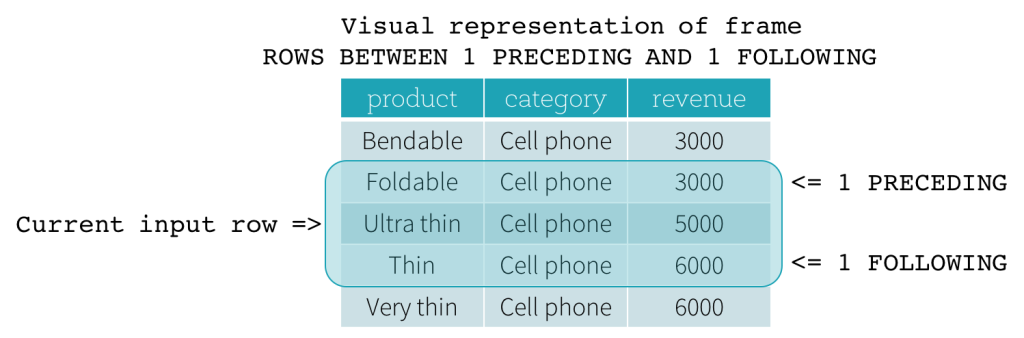
ROW frame是基于当前输入行位置的物理偏移量,也就是说CURRENT ROW, <value> PRECEDING, or <value> FOLLOWING指定物理偏移.如果使用CURRENT ROW作为边界,它表示当前输入行。 PRECEDING and FOLLOWING分别描述当前输入行之前和之后出现的行数。
下图演示了一个行frame, 1 PRECEDING作为开始边界, 1 FOLLOWING 作为结束边界(在SQL中表现为ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
RANGE frame
RANGE frames基于当前输入行位置的逻辑偏移量,语法与ROW frame类似。逻辑偏移量是当前输入行的排序表达式的值与frame的边界行相同表达式的值之间的差。由于这个定义,当使用RANGE frame时,只允许一个排序表达式。此外,对于RANGE frame,对于边界计算而言,具有与当前输入行相同的排序表达式值的所有行都被认为是相同的行。
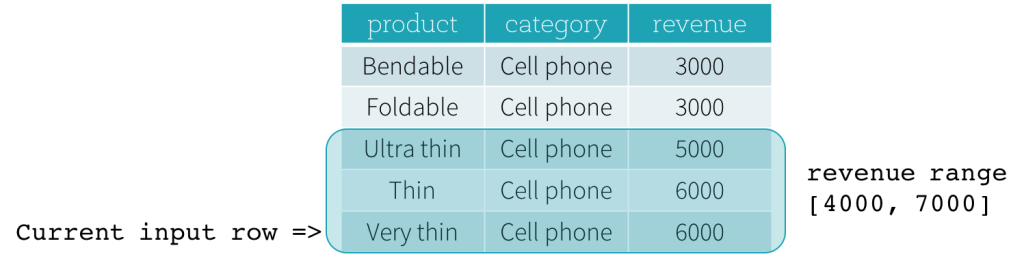
现在,让我们看一个例子。在本例中,排序表达式是revenue;开始边界是 2000 PRECEDING;结束边界是1000 FOLLOWING,(这个frame被在SQL中被定义为RANGE BETWEEN 2000 PRECEDING AND 1000 FOLLOWING),下面的五幅图说明了如何使用当前输入行的更新来更新frame。基本上,对于每一个当前的输入行,基于收入值,我们计算收入范围[current revenue value - 2000, current revenue value + 1000]。收入值在此范围内的所有行都位于当前输入行的frame中。
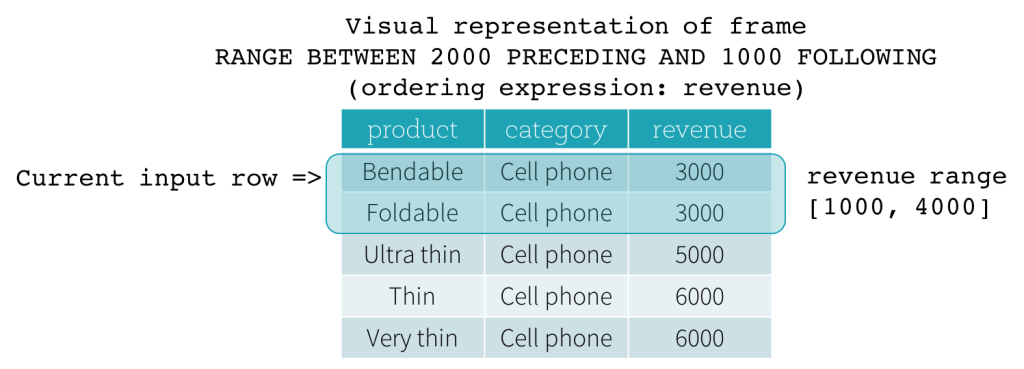
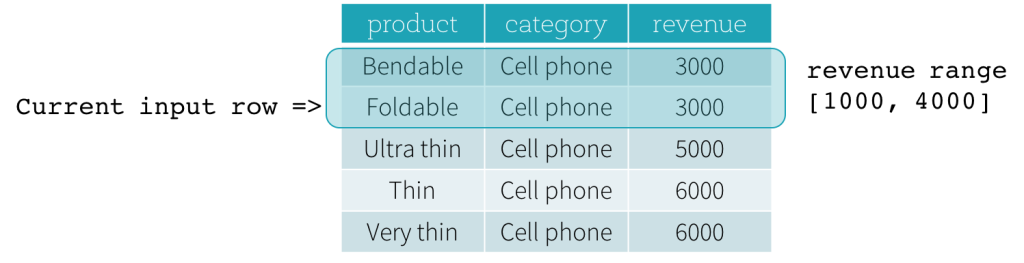
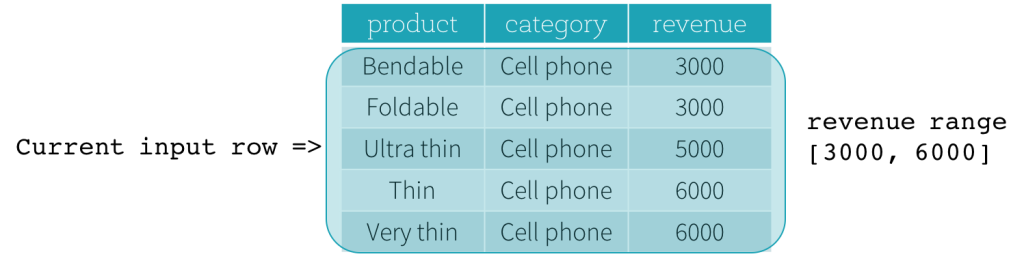
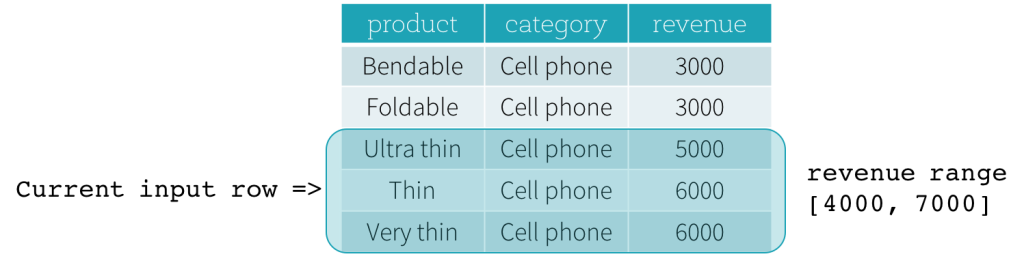
总之,要定义窗口规范,用户可以在SQL中使用以下语法。
OVER (PARTITION BY ... ORDER BY ... frame_type BETWEEN start AND end) |
在这里,frame_type可以是行(对于ROW frame)或范围(对于 RANGE frame);
都可以使用 UNBOUNDED PRECEDING, CURRENT ROW, <value> PRECEDING, and <value> FOLLOWING其中的任意一个作为开始; UNBOUNDED FOLLOWING, CURRENT ROW, <value> PRECEDING, and<value> FOLLOWING其中的任意一个作为结束.
在Python DataFrame API中,用户可以定义如下的窗口规范。
from pyspark.sql.window import Window |