
在工作中经常要使用UDF来处理表中的数据,我们定义了一个UDF函数,但是一直出现无法序列化的问题。
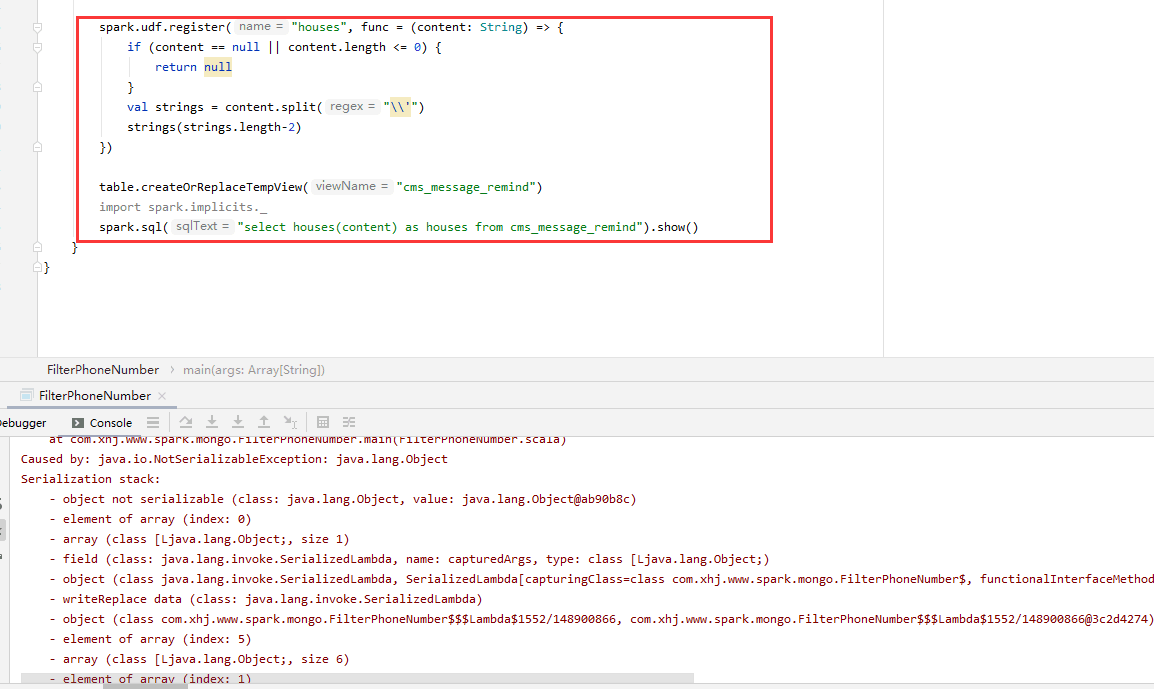
排查多次无果后,对着原来写过的UDF和老叶给的提示,最终发现是因为return关键字的原因,原本使用return关键字退出程序,但是在Spark SQL中却引起了无法序列化的问题,由于Scala语言的特性,return关键字可以省略。
去掉return关键字后,无法序列化的问题被解决。这里面的原理有时间再深入研究。
在工作中经常要使用UDF来处理表中的数据,我们定义了一个UDF函数,但是一直出现无法序列化的问题。
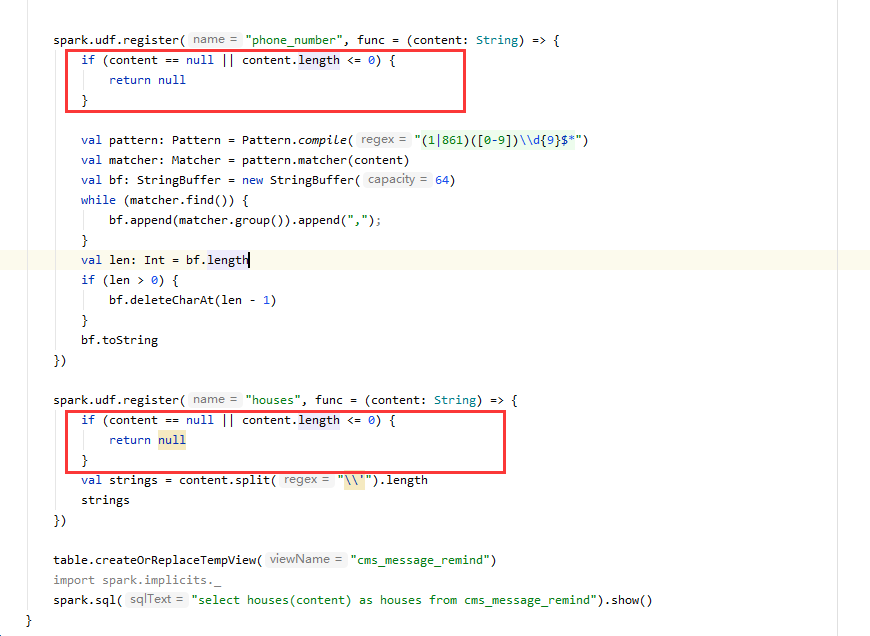
排查多次无果后,对着原来写过的UDF和老叶给的提示,最终发现是因为return关键字的原因,原本使用return关键字退出程序,但是在Spark SQL中却引起了无法序列化的问题,由于Scala语言的特性,return关键字可以省略。
去掉return关键字后,无法序列化的问题被解决。这里面的原理有时间再深入研究。