
Table
抽象化: Region映射关系表
table region startkey endkey regionserver |
- 一个Table按照RowKey划分成多个Region
- 每个Region下面有多个列族,每个列族划分成一个Store
- 每个Store由一个MemStore和多个StoreFile组成
先来回顾一下整体的架构

再来看一下Table的划分过程

hbase:meta表
hbase:meta表存储了所有用户HRegion的位置信息,它的RowKey是:tableName,regionStartKey,regionId,replicaId等,它只有info列族,这个列族包含三个列,他们分别是:info:regioninfo列是RegionInfo的proto格式:regionId,tableName,startKey,endKey,offline,split,replicaId;info:server格式:HRegionServer对应的server:port;info:serverstartcode格式是HRegionServer的启动时间戳。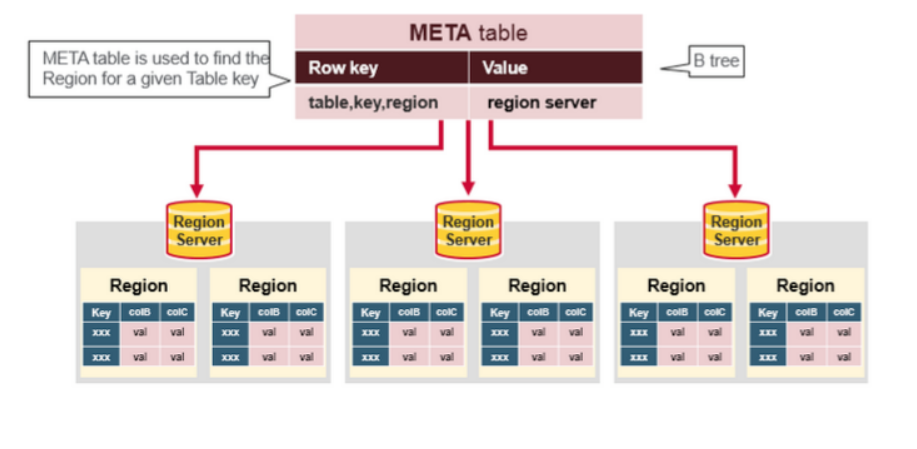
HBase数据模型
从使用角度来看,HBase包含了大量关系型数据库的基本概念—表、行、列,但在BigTable的论文中又称HBase为 “sparse, distributed, persistent multidimensional sorted map”,即HBase本质来看是一个Map。那HBase到底是一个什么样的数据库呢?
实际上,从逻辑视图来看,HBase中的数据是以表形式进行组织的,而且和关系型数据库中的表一样,HBase中的表也由行和列构成,因此HBase非常容易理解。但从物理视图来看,HBase是一个Map,由键值(KeyValue,KV)构成,不过与普通的Map不同,HBase是一个稀疏的、分布式的、多维排序的Map。
逻辑视图
在具体了解逻辑视图之前有必要先看看HBase中的基本概念。
table:表,一个表包含多行数据。row:行,一行数据包含一个唯一标识rowkey、多个column以及对应的值。在HBase中,一张表中所有row都按照rowkey的字典序由小到大排序。column:列,与关系型数据库中的列不同,HBase中的column由column family(列簇)以及qualif?ier(列名)两部分组成,两者中间使用”:”相连。比如contents:html,其中contents为列簇,html为列簇下具体的一列。column family在表创建的时候需要指定,用户不能随意增减。一个column family下可以设置任意多个qualif?ier,因此可以理解为HBase中的列可以动态增加,理论上甚至可以扩展到上百万列。timestamp:时间戳,每个cell在写入HBase的时候都会默认分配一个时间戳作为该cell的版本,当然,用户也可以在写入的时候自带时间戳。HBase支持多版本特性,即同一rowkey、column下可以有多个value存在,这些value使用timestamp作为版本号,版本越大,表示数据越新。cell:单元格,由五元组(row, column, timestamp, type, value)组成的结构,其中type表示Put/Delete这样的操作类型,timestamp代表这个cell的版本。这个结构在数据库中实际是以KV结构存储的,其中(row, column, timestamp, type)是K,value字段对应KV结构的V。

总体来看,HBase的逻辑视图是比较容易理解的,需要注意的是,HBase引入了列簇的概念,列簇下的列可以动态扩展;另外,HBase使用时间戳实现了数据的多版本支持。

物理视图
与大多数数据库系统不同,HBase中的数据是按照列簇存储的,即将数据按照列簇分别存储在不同的目录中。

hbase支持数据多版本特性,通过带不同的时间戳的多个的kv来实现。每次put,delete会产生一个新的cell,都拥有一个版本。表默认只存放1个版本,可以配置多版本。查询时默认是返回最新版本的数据,但是可以通过指定版本号来获取旧数据。
HBase的优点
与其他数据库相比,HBase在系统设计以及实际实践中有很多独特的优点。
- 容量巨大:HBase的单表可以支持千亿行、百万列的数据规模,数据容量可以达到TB甚至PB级别。传统的关系型数据库,如Oracle和MySQL等,如果单表记录条数超过亿行,读写性能都会急剧下降,在HBase中并不会出现这样的问题。
- 良好的可扩展性:HBase集群可以非常方便地实现集群容量扩展,主要包括数据存储节点扩展以及读写服务节点扩展。HBase底层数据存储依赖于HDFS系统,HDFS可以通过简单地增加DataNode实现扩展,HBase读写服务节点也一样,可以通过简单的增加RegionServer节点实现计算层的扩展。
- 稀疏性:HBase支持大量稀疏存储,即允许大量列值为空,并不占用任何存储空间。这与传统数据库不同,传统数据库对于空值的处理要占用一定的存储空间,这会造成一定程度的存储空间浪费。因此可以使用HBase存储多至上百万列的数据,即使表中存在大量的空值,也不需要任何额外空间。
- 高性能:HBase目前主要擅长于OLTP场景,数据写操作性能强劲,对于随机单点读以及小范围的扫描读,其性能也能够得到保证。对于大范围的扫描读可以使用MapReduce提供的API,以便实现更高效的并行扫描。
- 多版本:HBase支持多版本特性,即一个KV可以同时保留多个版本,用户可以根据需要选择最新版本或者某个历史版本。
- 支持过期:HBase支持TTL过期特性,用户只需要设置过期时间,超过TTL的数据就会被自动清理,不需要用户写程序手动删除。
- Hadoop原生支持:HBase是Hadoop生态中的核心成员之一,很多生态组件都可以与其直接对接。HBase数据存储依赖于HDFS,这样的架构可以带来很多好处,比如用户可以直接绕过HBase系统操作HDFS文件,高效地完成数据扫描或者数据导入工作;再比如可以利用HDFS提供的多级存储特性(Archival Storage Feature),根据业务的重要程度将HBase进行分级存储,重要的业务放到SSD,不重要的业务放到HDD。或者用户可以设置归档时间,进而将最近的数据放在SSD,将归档数据文件放在HDD。另外,HBase对MapReduce的支持也已经有了很多案例,后续还会针对Spark做更多的工作。
HBase的缺点
任何一个系统都不会完美,HBase也一样。HBase不能适用于所有应用场景,例如:
- HBase本身不支持很复杂的聚合运算(如Join、GroupBy等)。如果业务中需要使用聚合运算,可以在HBase之上架设Phoenix组件或者Spark组件,前者主要应用于小规模聚合的OLTP场景,后者应用于大规模聚合的OLAP场景。
- HBase本身并没有实现二级索引功能,所以不支持二级索引查找。好在针对HBase实现的第三方二级索引方案非常丰富,比如目前比较普遍的使用Phoenix提供的二级索引功能。
- HBase原生不支持全局跨行事务,只支持单行事务模型。同样,可以使用Phoenix提供的全局事务模型组件来弥补HBase的这个缺陷。
可以看到,HBase系统本身虽然不擅长某些工作领域,但是借助于Hadoop强大的生态圈,用户只需要在其上架设Phoenix组件、Spark组件或者其他第三方组件,就可以有效地协同工作。