
ES 索引分片和副本设置
你可以通过修改配置来自定义索引行为,详细配置参照 {ref}/index-modules.html[索引模块]
Elasticsearch 提供了优化好的默认配置。 除非你理解这些配置的作用并且知道为什么要去修改,否则不要随意修改。
下面是两个 最重要的设置:
number_of_shards每个索引的主分片数,默认值是
5。这个配置在索引创建后不能修改。number_of_replicas每个主分片的副本数,默认值是
1。对于活动的索引库,这个配置可以随时修改。
例如,我们可以创建只有 一个主分片,没有副本的小索引:
PUT /my_temp_index |
然后,我们可以用 update-index-settings API 动态修改副本数:
PUT /my_temp_index/_settings |
Spark 读写ES
ES官方提供了对spark的支持,可以直接通过spark读写es,具体可以参考ES Spark Support文档(文末有地址)。
以下是pom依赖,具体版本可以根据自己的es和spark版本进行选择:
<dependency> |
Spark SQL - ES
主要提供了两种读写方式:一种是通过DataFrameReader/Writer传入ES Source实现;另一种是直接读写DataFrame实现。在实现前,还要列一些相关的配置:
配置
| 参数 | 描述 |
|---|---|
| es.nodes.wan.only | true or false,在此模式下,连接器禁用发现,并且所有操作通过声明的es.nodes连接 |
| es.nodes | ES节点 |
| es.port | ES端口 |
| es.index.auto.create | true or false,是否自动创建index |
| es.resource | 资源路径 |
| es.mapping.id | es会为每个文档分配一个全局id。如果不指定此参数将随机生成;如果指定的话按指定的来 |
| es.batch.size.bytes | es批量API的批量写入的大小(以字节为单位) |
| es.batch.write.refresh | 批量更新完成后是否调用索引刷新 |
| es.read.field.as.array.include | 读es的时候,指定将哪些字段作为数组类型 |
列了一些常用的配置,更多配置查看ES Spark Configuration文档
DataFrameReader读ES
import org.elasticsearch.spark.sql._ |
DataFrameWriter写ES
import org.elasticsearch.spark.sql._ |
读DataFrame
jar包中提供了esDF()方法可以直接读es数据为DataFrame,以下是源码截图。
简单说一下各个参数:
resource:资源路径,例如hive_table/docs
cfg:一些es的配置,和上面代码中的options差不多
query:指定DSL查询语句来过滤要读的数据,例如”?q=user_group_id:3“表示读user_group_id为3的数据
val options = Map( |
写DataFrame
jar包中提供了saveToEs()方法可以将DataFrame写入ES,以下是源码截图。
resource:资源路径,例如hive_table/docs
cfg:一些es的配置,和上面代码中的options差不多
import org.elasticsearch.spark.sql._ |
Structured Streaming - ES
es也提供了对Structured Streaming的集成,使用Structured Streaming可以实时的写入ES。
import org.elasticsearch.spark.sql._ |
可能遇到的问题
数组类型转换错误
报错信息:type (scala.collection.convert.Wrappers.JListWrapper) cannot be converted to the string type
因为es的mapping只会记录字段的类型,不会记录是否是数组,也就是说如果是int数组,es的mapping只是记录成int。
可以在option中加一个es.read.field.as.array.include,标明数组字段
-> "数组字段的名字" |
如果是object里的某个字段,写成”object名字.数组字段名字”,如果是多个字段,字段名之间用逗号分隔
Timestamp被转为Long
DataFrame的Timestamp类型数据写入ES后,就变成了Number类型。
这可能不算个问题,时间戳本质上就是Long类型的毫秒值;但是在Hive中Timestamp是”yyyy-MM-dd HH:mm:ss”的类型,个人觉得很别扭。
尝试将Timestamp类型字段转成Date类型,写入ES后还是Number类型。网上搜了一圈也没有什么好的办法,大家有什么解决办法欢迎交流。
References
ES Spark Support文档: https://www.elastic.co/guide/en/elasticsearch/hadoop/current/spark.html#spark
ES Spark Configuration: https://www.elastic.co/guide/en/elasticsearch/hadoop/current/configuration.html
Spark 读写 ES 调优记录
问题记录
项目中有两个索引数据量较大,虽然API支持读前过滤,但是过滤后的数据读起来还是很慢。本身指标计算不复杂,计算时间很短,读数据成为短板。
| 索引名 | shard数 | 数据量 | 过滤后 |
|---|---|---|---|
| leads | 5 | 7千万 | 1千万 |
| leads_call | 5 | 9千万 | 100万 |
读数据优化
1.优化查询
使用spark.sparkContext.esRDD(esResource(esIndex), query)读的数据,发现自己的rangeQuery还不如matchAllQuery读的快,发现es在根据字段进行range查询时,如果这个range不是数字(可能还有其他类型)类型,查询本身就很慢。2.优化es-rdd读取方式
更改索引的mapping后,速度的确提升很多,但是读数据依然是短板。
从文档中发现,改了如下参数=10000
=falsescroll.size默认设置好像才10,读数据是走的http,我过滤后的数据有1千万多,第二个参数是关闭slice优化,默认是打开的,会根据索引的数据量和spark.es.input.max.docs.per.partition大小划分分区,默认每个分区是10万。
经测试发现,如果不关闭slice优化,且走这个默认值,读的esRDD的确会有多个分区,也会有多个task并发读,但是task太多反而耽误了速度,读得较慢。在关必slice优化的情况下,分区数为shard数,读leads索引耗时2.4min左右,快了不少。
3.增加executor数,提供读数据的并发度。
由于指标需要5min更新一次,整个计算过程耗时4min左右,读数据上还需要提速。
由于spark中的stage没有依赖关系可以并发执行,增加executor后,两个索引同时读取。
4.打开slice优化/增加shard数
即使提高任务的并发度,但是读leads索引的stage依然太慢。目前是5个分区在并发读,在打开slice优化,并设置每个分区为文档数为100万后
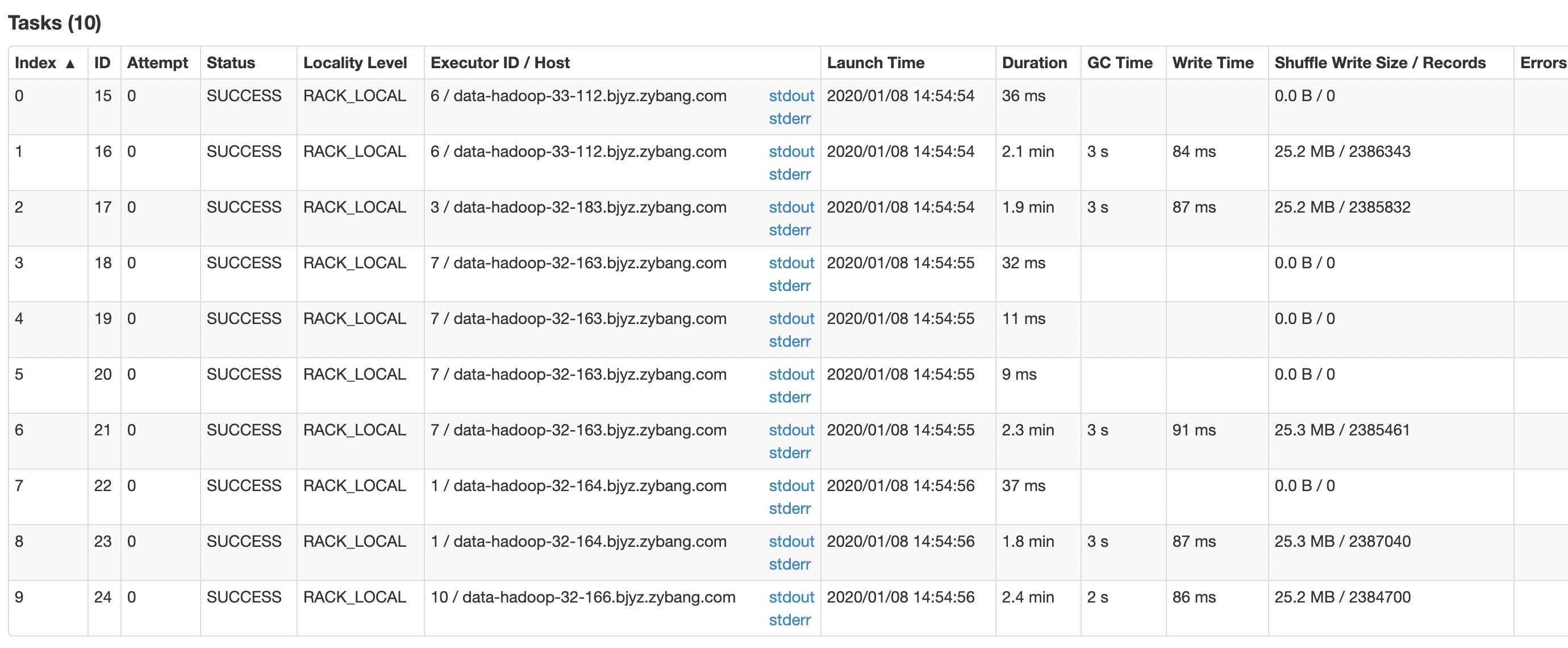
虽然分区数提高了,但是数据分布并不均匀,造成这种现象可能和多种因素有关。由于slice优化不理想,这里采取增加索引shard数的方式,将shard加至10,并且关闭slice优化,效果比较理想。
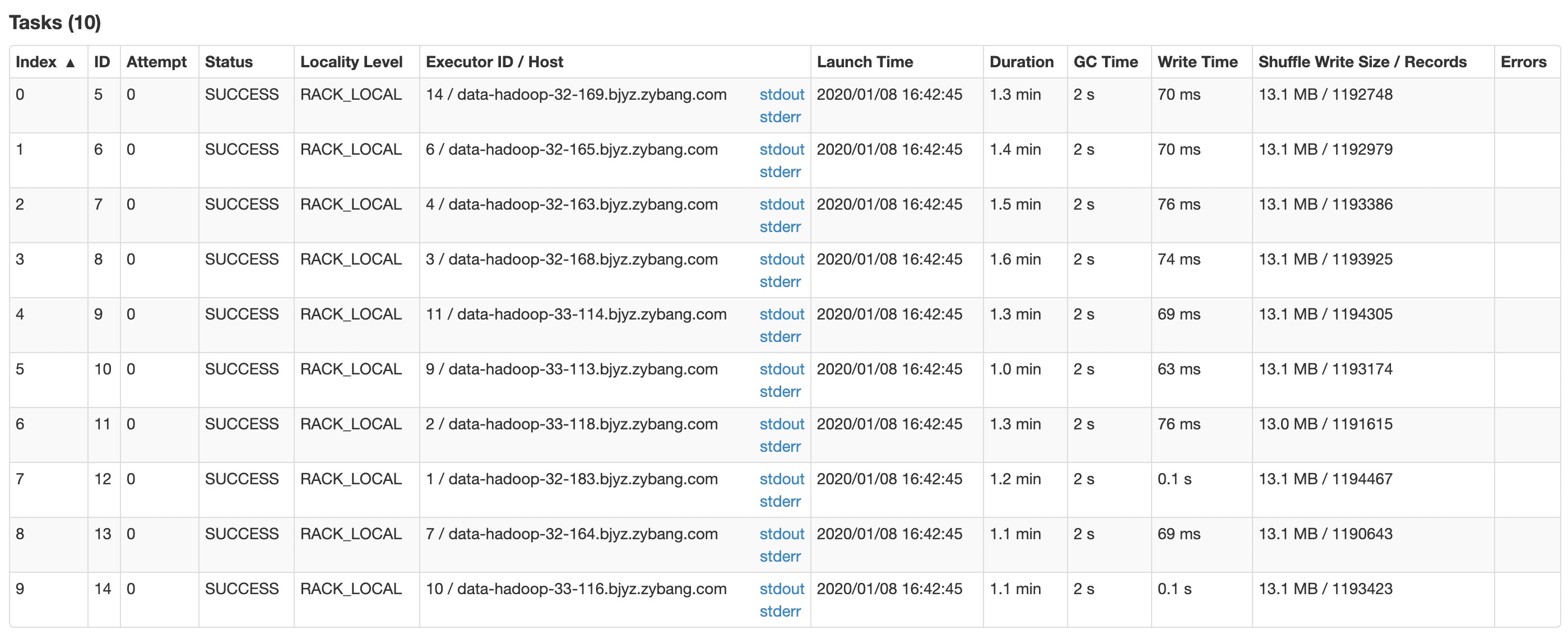
写数据优化
项目中数据经过聚合计算后,数据量只有100万左右,因此写数据并不是短板,只是简单配置了参数。
=5000 |
第一个参数设置批写入的bulk大小,默认值是1000,
第二参数关闭批写入后主动刷新索引的操作
总结
经过层层优化,整个计算任务控制在了3min中左右,任务时间得到缩短,但是读数据依然占的比重较大,个人感觉es本身并不适合大批量数据读写的场景。如果执行计算任务的数据量很大,es和spark并不搭,可以考虑Hbase+spark的方式替代。反之,如果数据可以提前过滤,并且过滤后的数据并不多的情况下,使用es+spark是一种不错的选择。
使用spark读写es可以使用ES提供的包,es提供了对hadoop,spark等大数据组件的包,es-spark包地址:https://www.elastic.co/guide/en/elasticsearch/hadoop/6.3/spark.html