
记得去年的一次面试,面试官让我谈谈对RDD的理解,RDD这东西叫做弹性分布式数据集,是Spark的核心概念
它是分布式的,可以分布在多台机器上,进行计算
它是弹性的,计算过程中内存不够时它会和磁盘进行数据交换
它表示已被分区,不可变的并能够被并行操作的数据集合
这些特性,想必大家都能说出来,我也是这么回答的,觉得问题很简单,可面试官回复我:仅看过几篇文章的人,也能有和你同样的回答,你对于RDD有独到的理解吗?
当时理解的太浅,回去后,就补习了一番
今天就来谈一谈对RDD的理解
先看一下官方在源码中对RDD的注释:
* Internally, each RDD is characterized by five main properties: |
通过官方的注释,我们可以了解到,每个RDD都有五个重要的属性
- 一个分区的列表。我们可以理解为是一组分片,分片就是数据集的基本组成单位,对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户创建RDD时,可以指定RDD的分片个数,若没有指定,则采用默认(默认值:程序所分配的CPU Cores数目),下图描述了分区存储的计算模型,每个分配的存储是有BlockManager实现的。每个分区都会被逻辑映射成BlockManager的一个block,而这个block会被一个Task负责计算。
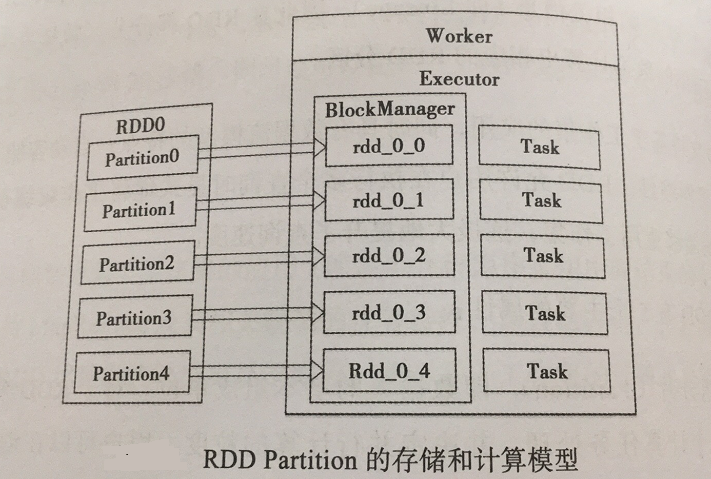
一个计算每个分区的函数。即RDD的计算分片compute函数,Spark中的RDD计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复核,不需要保存每次计算的结果。
RDD之间的依赖关系。这里要说一下RDD的依赖关系
RDD和它的依赖的parent RDD(s)的关系有两种不同的类型,即宽依赖和窄依赖
● 窄依赖指的是每一个parent RDD的partition最多被子RDD的一个partition使用
● 宽依赖是指多个子RDD的partition会依赖同一个parent RDD的partition
接下来,从不同类型的转换来进一步理解RDD的窄依赖和宽依赖的区别,如下图所示。
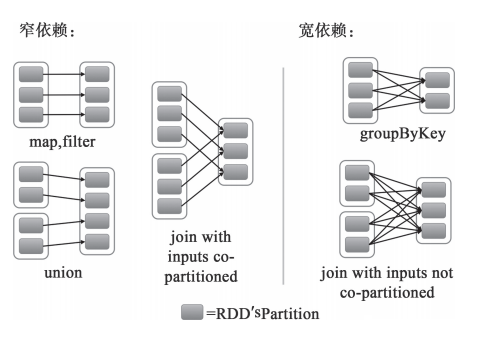
对于map和filter形式的转换来说,它们只是将Partition的数据根据转换的规则进行转化,并不涉及其他的处理,可以简单地认为只是将数据从一个形式转换到另一个形式。
对于union,只是将多个RDD合并成一个,parent RDD的Partition(s)不会有任何的变化,可以认为只是把parent RDD的Partition(s)简单进行复制与合并。
对于join,如果每个Partition仅仅和已知的、特定的Partition进行join,那么这个依赖关系也是窄依赖。对于这种有规则的数据的join,并不会引入昂贵的Shuffle。
对于窄依赖,由于RDD每个Partition依赖固定数量的parent RDD(s)的Partition(s),因此可以通过一个计算任务来处理这些Partition,并且这些Partition相互独立,这些计算任务也就可以并行执行了。
对于groupByKey,子RDD的所有Partition(s)会依赖于parent RDD的所有Partition(s),子RDD的Partition是parent RDD的所有Partition Shuffle的结果,因此这两个RDD是不能通过一个计算任务来完成的。同样,对于需要parent RDD的所有Partition进行join的转换,也是需要Shuffle,这类join的依赖就是宽依赖而不是前面提到的窄依赖了。
不同的操作依据其特性,可能会产生不同的依赖。例如map、filter操作会产生 narrow dependency 。reduceBykey操作会产生 wide / shuffle dependency。
通俗点来说,RDD的每个Partition,仅仅依赖于父RDD中的一个Partition,这才是窄。 就这么简单!
反正,子Rdd的partition和父Rdd的Partition如果是一对一就是窄依赖,这样理解就好区分了
捋一下这里的源码:
所有的依赖都要实现
trait Dependency[T]:
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}其中rdd就是依赖的parent RDD。
对于窄依赖的实现(有两种)
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
//返回子RDD的partitionId依赖的所有的parent RDD的Partition(s)
def getParents(partitionId: Int): Seq[Int]
override def rdd: RDD[T] = _rdd
}窄依赖是有两种具体实现,分别如下:
一种是一对一的依赖,即OneToOneDependency:
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int) = List(partitionId)
通过getParents的实现不难看出,RDD仅仅依赖于parent RDD相同ID的Partition。还有一个是范围的依赖,即RangeDependency,它仅仅被org.apache.spark.rdd.UnionRDD使用。UnionRDD是把多个RDD合成一个RDD,这些RDD是被拼接而成,即每个parent RDD的Partition的相对顺序不会变,只不过每个parent RDD在UnionRDD中的Partition的起始位置不同。因此它的getPartents如下:
override def getParents(partitionId: Int) = {
if(partitionId >= outStart && partitionId < outStart + length) {
List(partitionId - outStart + inStart)
} else {
Nil
}
}其中,inStart是parent RDD中Partition的起始位置,outStart是在UnionRDD中的起始位置,length就是parent RDD中Partition的数量。
对于宽依赖的实现(只有一种)
宽依赖的实现只有一种:ShuffleDependency。子RDD依赖于parent RDD的所有Partition,因此需要Shuffle过程:
class ShuffleDependency[K, V, C](
_rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Option[Serializer] = None,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]] {
override def rdd = _rdd.asInstanceOf[RDD[Product2[K, V]]]
//获取新的shuffleId
val shuffleId: Int = _rdd.context.newShuffleId()
//向ShuffleManager注册Shuffle的信息
val shuffleHandle: ShuffleHandle =
_rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.size, this)
_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
}注意:宽依赖支持两种Shuffle Manager。
即org.apache.spark.shuffle.hash.HashShuffleManager(基于Hash的Shuffle机制)和org.apache.spark.shuffle.sort.SortShuffleManager(基于排序的Shuffle机制)。
可选:KV RDD可重分区。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于key-value的RDD才会有Partitioner,非key-value的RDD的Partitioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
可选:移动计算,存储存取每个Partition的优先位置。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在块的位置。