
目录
- Phoenix配置
- Phoenix创建二级索引
- Phoenix基本优化
- Phoenix表优化
- Phoenix性能优化
Phoenix配置
添加如下配置到Hbase的Hregionserver节点的hbase-site.xml
<!-- phoenix regionserver 配置参数 -->
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<property>
<name>hbase.region.server.rpc.scheduler.factory.class</name>
<value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
<property>
<name>hbase.rpc.controllerfactory.class</name>
<value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>添加如下配置到Hbase中Hmaster节点的hbase-site.xml中
<!-- phoenix master 配置参数 -->
<property>
<name>hbase.master.loadbalancer.class</name>
<value>org.apache.phoenix.hbase.index.balancer.IndexLoadBalancer</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.phoenix.hbase.index.master.IndexMasterObserver</value>
</property>常见问题汇总
注意:网上配置文档里有这一条,但在实际测试中(测试环境hbase-1.3.1,网上0.98.6),加入该条的regionserver会在hbase启动时失败,对应节点上没有HregionServer进程,去掉该配置后正常启动,且能正常创建local index。
<property>
<name>hbase.coprocessor.regionserver.classes</name>
<value>org.apache.hadoop.hbase.regionserver.LocalIndexMerger</value>
</property>
Phoenix创建二级索引
2020-12-15更新
phoenix索引 |
全局索引 global index是默认的索引格式
适用于多读少写的业务场景。写数据的时候会消耗大量开销,因为索引表也要更新,而索引表是分布在不同的数据节点上的,跨节点的数据传输带来了较大的性能消耗。
在读数据的时候Phoenix会选择索引表来降低查询消耗的时间。如果想查询的字段不是索引字段的话索引表不会被使用,也就是说不会带来查询速度的提升。
# 全局索引必须是查询语句中所有列都包含在全局索引中,它才会生效。
CREATE INDEX MY_INDEX ON STUDENT("info"."dt");查询语句:
select "dt" from STUDENT where "dt" >= '2018-08-08'; #可以使用到索引表MY_INDEX
select "name","age","dt" from STUDENT where "dt" >= '2018-08-08'; #这样子就不会用到索引表MY_INDEX,因为name和age不在索引表中;所以使用全局索引,必须要所有的列都包含在索引中。那么怎样才能使用上索引呢?有两种方法:
创建索引的时候使用覆盖索引
CREATE INDEX MY_INDEX ON STUDENT("info"."dt") INCLUDE("info"."name", "info"."age"); # INCLUED之前的索引,只能建立一个才会走range scan索引,不然就是full scan
这种索引会把name加到索引表里面,同时name也会随着原数据表中的变化而变化。这种方式很明显的缺点是索引表的大小较大,然后就是全局索引不适合写特别多的情况。
Covered Index 覆盖索引的二级索引。这种索引在获取数据的过程中,内部不需要再去HBase上获取任何数据,你查询需要返回的列的数据都会被存储在索引中。
要想达到这种效果,你的select 的列,where 的列都需要在索引中出现。注意关键字INCLUDE(注意跟异步索引的区别),就是包含需要返回数据结果的列。这种索引方式的最大好处就是速度快,而我们也知道,索引就是空间换时间,所以缺点也很明显,存储空间耗费较多。Phoenix的索引其实就是建了一张HBase的表。你可以通过HBase Shell的list命令看到。
使用类似于Oracle的Hint,强制索引
select /*+ INDEX(STUDENT MY_INDEX)*/ "name","age" from STUDENT where "dt" >= '2018-08-08';
查询引擎会使用MY_INDEX这个索引,由于它会发现索引表中没有name,age数据,所以每一行它都会去原数据表中获取name,age的值。这个强制索引只有在你认为索引有比较好的选择性的时候才是好的选择,也就是说dt大于2018-08-08的行数不多。不然的话,使用Phoenix默认的全表扫描的性能也许会更好。
本地索引 Local index适用于写操作频繁的场景
本地索引适合那些写多读少,或者存储空间有限的场景。和全局索引一样,Phoenix也会在查询的时候自动选择是否使用本地索引。
索引数据和真实数据存储在同一台机器上,这样做主要是为了避免网络数据传输的开销。如果你的查询条件没有完全覆盖索引列,本地索引还是可以生效。因为无法提前确定数据在哪个Region上,所以在读数据的时候,还需要检查每个Region上的数据而带来一些性能损耗。
如下示例,创建了本地索引
CREATE LOCAL INDEX my_index ON my_table (my_index)
local index的设计方式,索引数据直接写在原表rowkey中,列族不写任何实际信息,local index的rowkey的设计方位是:
- 原数据region的start key+”\x00”+二级索引字段1+”\x00”+二级索引字段2(复合索引)…+”\x00”+原rowkey
第一条信息”原数据region的start key”,这样做的目的是保证索引数据和原数据在一个region上,定位到二级索引后根据原rowkey就可以很快在本region上获取到其它信息,减少网络开销和检索成本。 - 查询的时候,会在不同的region里面分别对二级索引字段定位,查到原rowkey后在本region上获取到其它信息。
- 因为这种索引设计方式只写索引数据,省了不少空间的占用,根据索引信息拿到原rowkey后再根据rowkey到原数据里面获取其它信息。所以这种表的应用场景定位是
写的快,读得慢。
- 原数据region的start key+”\x00”+二级索引字段1+”\x00”+二级索引字段2(复合索引)…+”\x00”+原rowkey
local index 和 global index 比较
索引数据
global index单独把索引数据存到一张表里,保证了原始数据的安全,侵入性小。
local index把数据写到原始数据里面,侵入性强,原表的数据量=原始数据+索引数据,使原始数据更大
性能方面
global index要多写出来一份数据,写的压力就大一点,但读的速度就非常快。
local index只用写一份索引数据,节省不少空间,但多了一步通过rowkey查找数据,写的速度非常快,读的速度就没有直接取自己的列族数据快。
异步创建索引
一般我们可以使用CREATE INDEX来创建一个索引,这是一种同步的方法。但是有时候我们创建索引的表非常大,我们需要等很长时间。Phoenix 4.5以后有一个异步创建索引的方式,使用关键字ASYNC来创建索引:
create index MY_INDEX on FRUITS("info"."name") include ("info"."color") async;
这时候创建的索引表中不会有数据。你还必须要单独的使用命令行工具来执行数据的创建。当语句给执行的时候,后端会启动一个map reduce任务,只有等到这个任务结束,数据都被生成在索引表中后,这个索引才能被使用。启动工具的方法:
${HBASE_HOME}/bin/hbase org.apache.phoenix.mapreduce.index.IndexTool \
--schema MY_SCHEMA \
--data-table FRUITS --index-table MY_INDEX \
--output-path ASYNC_IDX_HFILES注:
--schema MY_SCHEMA,不加这个就是默认的schema注意上边尽量不要用小写,即使””双引号里边写的是小写它也不识别;
这个任务不会因为客户端给关闭而结束,是在后台运行。你可以在指定的文件ASYNC_IDX_HFILES中找到最终实行的结果。
15:04:01,579 INFO [main] index.IndexTool: Loading HFiles from ASYNC_IDX_HFILES/MY_INDEX
15:04:01,723 WARN [main] mapreduce.LoadIncrementalHFiles: Skipping non-directory hdfs://hadoop101:9000/user/kris/ASYNC_IDXEX/_SUCCESS
15:04:01,909 INFO [LoadIncrementalHFiles-0] hfile.CacheConfig: Created cacheConfig: CacheConfig:disabled
15:04:01,985 INFO [LoadIncrementalHFiles-0] mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://hadoop101:9000/usIDX_HFILES/MY_INDEX/info/6b69a7babd4e4c629b6bee988cf15c5d first=water\x001005 last=watermelon\x001006
15:04:02,136 INFO [main] index.IndexToolUtil: Updated the status of the index MY_INDEX to ACTIVE综上三种提升效率查询方式
1) CREATE INDEX my_index ON my_table (v1) INCLUDE (v2)
2) SELECT /*+ INDEX(my_table my_index) */ v2 FROM my_table WHERE v1 = 'foo'
3) CREATE LOCAL INDEX my_index ON my_table (v1)如何删除索引
use “test”,再删索引
drop index "my_index" on "student"不行,必须前边加schema,默认的不需要加DROP INDEX "my_index" ON "test"."student"
用phoenix只是用hbase自身实现了hbase自己的二级索引,用hbase自己rowkey查询的特点来设计索引数据的rowkey,性能方面完全要靠一次检索索引数据的数据量大小了。
Phoenix基本优化
可以在hbase-site.xml里配置以下调优参数
index.builder.threads.max |
Phoenix表优化
Phoenix客户端在成功提交一个操作并且得到成功响应后,就代表你所做的操作已经成功应用到原表和相关的索引表中。换句话说,索引表的维护和处理原表数据是同步的,并且各自是强一致性保证的。但是因为索引表和原表是在不同的表中,根据表的属性和索引的类型,当服务端崩溃导致一次提交失败时,原表和索引表中的数据就会有一些变化。所以在使用二级索引的时候,就要根据需求个用例充分考虑。
下面列出了一些不同级别的一致性保证供你选择。
事务表
如果把表定义成事务表(Transactional),你将获得最高级别的一致性保证。原表的操作和索引表的操作完全就是一个原子操作。如果提交失败,原表和索引表的数据都不会被更新,如果启用了这种级别的一致性,你的原表和索引表永远都保持同步。目前这个功能还是beta版本阶段,它是实现依赖于另一个Apache项目Apache Tephra。它是一个分布式事务框架。
那为什么不把所有的表都设置能事务的呢?特别是一些被声明了是不可变的表(只写一次,不修改的表),因为这个时候事务的损耗是非常小的。但是一旦你的表中的数据会变化,那么你就要承担一些冲突检测和事务管理器的开销;同时做事务表中建二级索引,会潜在的降低系统的可用性,因为原表和二级索引表都必须可用行,不然都会失败。
不可变表
不可变表中的数据之写入一次,之后就再也不会被更新了。对于这种表,Phoenix会做特别的优化,降低写入的损耗和增量维护的损耗。这类数据通常就是一些时间序列的数据,比如日志、事件、或者传感器的周期数据等等。这类表结构需要在见表的时候加上 IMMUTABLE_ROWS=true 语句,这样数据表就会被优化。默认建表是可变的。
CREATE TABLE HAO2 (k VARCHAR PRIMARY KEY, v VARCHAR) IMMUTABLE_ROWS=true; |
在不可变表上面建的所有的索引都是不可变的。对于全局的不可变索引来说,索引全部由客户端来维护,原表的数据变化会触发索引的修改。本地索引在服务端维护。需要注意的是,Phoenix没有强制在一张申明了不可变的原表上修改数据,索引将不再与原表同步。
如果你有一个已经存在的表,想把不可变索引修改成可变索引的话,可以用如下语句实现:
alter table HAO2 set IMMUTABLE_ROWS = false; |
另外,非事务性、不可变表的索引没有自动处理提交失败的机制。保持表和索引之间的一致性留给客户端处理。因为更新是幂等的,最简单的解决方案是客户端不断尝试直到成功。
易变的表
对于非事务的可变表,我们通过添加索引更新到原表的WAL日志里来维护索引信息的更新。只有当WAL同步后,才会去真的更新索引或原表。Phoenix写索引文件是并行的,这样有助于性能的提高,吞吐量增大。如果我们正在更新索引的时候,服务器挂了,我们会找到对应的WAL,重新执行所有的更新。更新的幂等性保证了数据的准确性。
不过需要注意一下几点:
由于是非事务表,有时候也可能出现原表和索引表的数据不同步。
就像上文所说,Phoenix是有可能在很短暂的时间里数据和索引不一致的,但是这是一个很短的过程,一般来说不会有影响。
HBase保证了每一个数据行或索引行都保证要么写入,要么丢失,你不可能看到一条数据有部分列写入而部分列没有写入。
数据是先入HBase原表,然后再插入索引表。
为了保证易变的表和索引同步,Phoenix主要提供三种级别:
如果不一致,禁止原表写入
这是最高级别的一致性级别,需要也别设置。当索引表更新出错的时候,原表会暂时禁用,不能写或更新数据。这个时候索引会自动重建,等索引和原表同步后,索引和原表才能恢复使用。
主要有两个配置项配置在服务端:
phoenix.index.failure.block.write:是否禁止原表的写入,这个需要设置成true,不然索引的重建追不上原表数据的增加。phoenix.index.failure.handling.rebuild:默认true,在索引表出错后,是否自动启动后台任务,重建索引。
如果不一致,禁用索引表
这是Phoenix的默认级别。如果写入索引表失败,索引表会标记成失效并且禁用索引,然后启动后台任务重建部分索引,等到完成之后再次激活索引。这种级别下,索引的失效和重建不会影响HBase原表的操作,只是在查询的时候索引不能使用了。
主要有二个服务端配置项:
phoenix.index.failure.handling.rebuild:默认是true,是否在索引操作失败后自动后台重建索引。phoenix.index.failure.handling.rebuild.interval:检测是否要部分重建索引的时间间隔,多少毫秒检测一次。默认值是:10000,也就是10秒。
如果不一致,需要人工重建索引
这是最低级别的同步策略。如果写入索引失败,Phoenix不会自动重建,而是需要人工命令重建索引。
服务端配置如下:
phoenix.index.failure.handling.rebuild:需要设置成false,不自动重建。
索引重建
Phoenix的索引重建是把索引表清空后重新装配数据。入上文所说,重建有可能是某个操作失败后系统后台自动的行为,也可以是人工来重建。人工重建的语法如下:
alter index index1_local on hao1 rebuild; |
Phoenix性能优化
1. SALT_BUCKETS
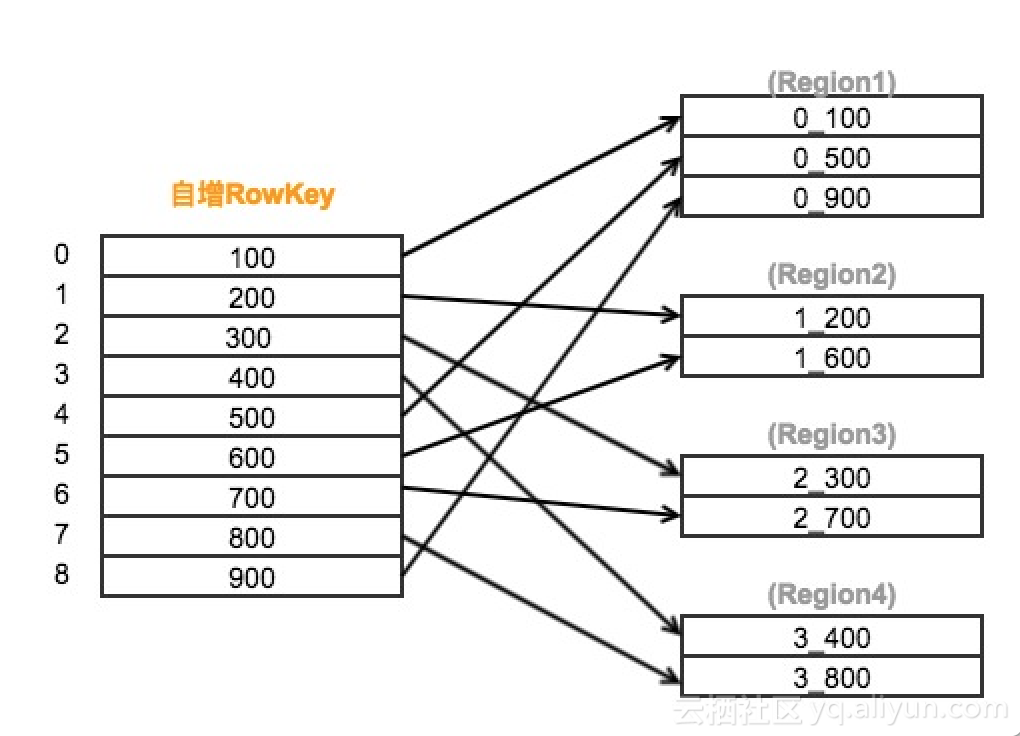
HBASE建表之初默认一个region,当写入数据超过region分裂阈值时才会触发region分裂。我们可以通过SALT_BUCKETS方法加盐,在表构建之初就对表进行预分区。SALT_BUCKETS值的范围是1~256(2的8次方),一般将预分区的数量设置为0.5~1 倍核心数。
加盐的原理是在原始的rowkey前加上一个byte,并填充由rowkey计算得出的hash值,使得原本连续的rowkeys被均匀打散到多个region中,有效地解决了读写热点问题。较多的region同时也增加了表读写并行度,从而提升了HBase表的读写效率。
#表指定分区数 |
加盐原理图解
2. Pre-split
除了使用加盐直接指定分区数外,我们也可以使用split on手动设置分区。这种方法同样是在构建之初就对表进行预分区,较多的region能够增加hbase的并行度,从而提升读取、写入效率。由于对rowkey不引入额外的byte,因此不会改变rowkey的原始顺序。
#对表指定五个分区 |
3. 分列族
由于HBase表的不同列族是分开存储,因此把相关性大的列放在同一个列族,能够减少数据检索时扫描的数据量,从而提升读的效率。
#对列指定a、b两个列族 |
4. 使用压缩
在数据量大的表上可以使用压缩算法来减少存储占用空间,从而提高性能 。常用的压缩方法有GZ,lzo等。
#对表实施GZ压缩 |
5. 二级索引
以Phoenix的全局索引为例,对departmentid建立全局索引,实际上是建立了一张索引表,索引表的rowkey由departmentid与原表rowkey拼接而来。由于departmentid是索引表rowkey的主维度,因此能够快速被查找并获取到对应的原表rowkey,再通过原表rowkey可以从原表中快速获取数据。
#建表 |