
Flink自带的DataSource API
单并行度:
socketTextStream
env.socketTextStream("aliyun", 9999)
fromCollection
val collect = env.fromCollection(
Access(20200514, "www.aa.com", 2000L) ::
Access(20200514, "www.bb.com", 6000L) ::
Access(20200514, "www.cc.com", 5000L) ::
Access(20200514, "www.aa.com", 4000L) ::
Access(20200514, "www.bb.com", 1000L) :: Nil
)fromElements
多并行度:
readTextFile
env.readTextFile("tunan-flink-stream/data/access.txt")
fromParallelCollection
env.fromParallelCollection(new NumberSequenceIterator(1, 10))
Flink自定义的DataSource
SourceFunction
从最简单的开始,开发一个不可并行的数据源并验证
实现SourceFunction接口
class SourceFunctionAccess extends SourceFunction[Access]{
var RUNNING = true
// 单并行度
override def run(ctx: SourceFunction.SourceContext[Access]): Unit = {
val random = new Random()
val domain = Array("www.aa.com", "www.bb.com", "www.cc.com")
while(RUNNING){
domain(random.nextInt(domain.length))
val time = System.currentTimeMillis()
ctx.collect(Access(time,domain(random.nextInt(domain.length)),random.nextInt(5000)))
}
}
override def cancel(): Unit = {
RUNNING = false
}
}
env.addSource(new SourceFunctionAccess())从上述代码可见,给addSource方法传入一个匿名类实例,该匿名类实现了SourceFunction接口
实现SourceFunction接口只需实现run和cancel方法,run方法产生数据,cancel是job被取消时执行的方法
ParallelSourceFunction
如果自定义DataSource中有复杂的或者耗时的操作,那么增加DataSource的并行度,让多个SubTask同时进行这些操作,可以有效提升整体吞吐量(前提是硬件资源充裕);
接下来实战可以并行执行的DataSource,原理是DataSoure实现ParallelSourceFunction接口,代码如下,可见和SourceFunctionDemo几乎一样,只是addSource方发入参不同,该入参依然是匿名类,不过实现的的接口变成了ParallelSourceFunction
class ParallelSourceFunctionAccess extends ParallelSourceFunction[Access]{
var RUNNING = true
override def run(ctx: SourceFunction.SourceContext[Access]): Unit = {
val random = new Random()
val domain = Array("www.aa.com", "www.bb.com", "www.cc.com")
while(RUNNING){
domain(random.nextInt(domain.length))
val time = System.currentTimeMillis()
ctx.collect(Access(time,domain(random.nextInt(domain.length)),random.nextInt(5000)))
}
}
override def cancel(): Unit = RUNNING = false
}
env.addSource(new ParallelSourceFunctionAccess())
RichSourceFunction
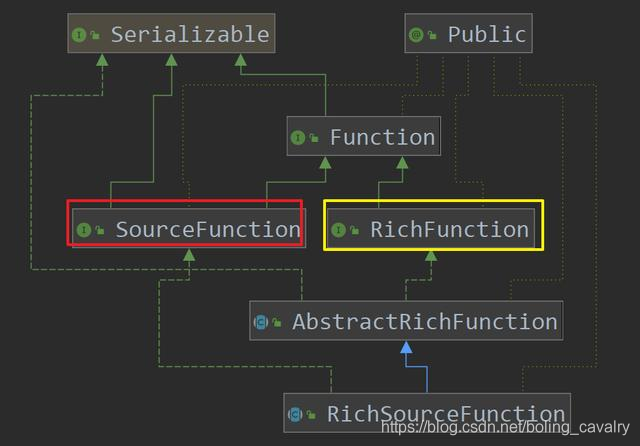
对RichSourceFunction的理解是从继承关系开始的,如下图,SourceFunction和RichFunction的特性最终都体现在RichSourceFunction上,SourceFunction的特性是数据的生成(run方法),RichFunction的特性是对资源的连接和释放(open和close):
接下来开始实战,目标是从MySQL获取数据作为DataSource,然后消费这些数据;
请提前准备好可用的MySql数据库,然后执行以下SQL,创建库、表、记录:
在pom.xml中增加mysql依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.34</version>
</dependency>代码内容如下:
-- jdbc
class MySQLSource extends RichSourceFunction[Student] {
val SQL = "select * from student"
var conn: Connection = _
var state: PreparedStatement = _
var rs: ResultSet = _
private var isRunning = true
override def open(parameters: Configuration): Unit = {
conn = MySQLUtils.getConnection
state = conn.prepareStatement(SQL)
}
override def close(): Unit = {
conn = null
state = null
rs = null
}
override def run(ctx: SourceFunction.SourceContext[Student]): Unit = {
rs = state.executeQuery()
while (rs.next() && isRunning) {
val id = rs.getInt("id")
val name = rs.getString("name")
val age = rs.getInt("age")
val sex = rs.getString("sex")
val school = rs.getString("school")
ctx.collect(Student(id, name, age, sex, school))
}
}
override def cancel(): Unit = {
isRunning = false
}
}
-- scalike
class ScalikeJDBCSource extends RichSourceFunction[Student]{
val sql = "select * from student"
override def open(parameters: Configuration): Unit = {
DBs.setup()
println("初始化一个")
}
override def close(): Unit ={
DBs.close()
println("断开连接一个")
}
override def run(ctx: SourceFunction.SourceContext[Student]): Unit = {
DB.readOnly(implicit session => {
SQL(sql).map(rs => {
val id = rs.int("id")
val name = rs.string("name")
val age = rs.int("age")
val sex = rs.string("sex")
val school = rs.string("school")
ctx.collect(Student(id, name, age, sex, school))
}).list().apply()
})
}
override def cancel(): Unit = ???
}上面的代码中,MySQLSource继承了RichSourceFunction,作为一个DataSource,可以作为addSource方法的入参;
open和close方法都会被数据源的SubTask调用,open负责创建数据库连接对象,close负责释放资源;
open方法中直接写死了数据库相关的配置(不可取);
run方法在open之后被调用,作用和之前的DataSource例子一样,负责生产数据,这里是用前面准备好的preparedStatement对象直接去数据库取数据;
RichParallelSourceFunction
实战到了这里,还剩RichParallelSourceFunction这个抽象类我们还没有尝试过,但我觉得这个类可以不用在文中多说了,咱们把RichlSourceFunction和RichParallelSourceFunction的类图放在一起看看:
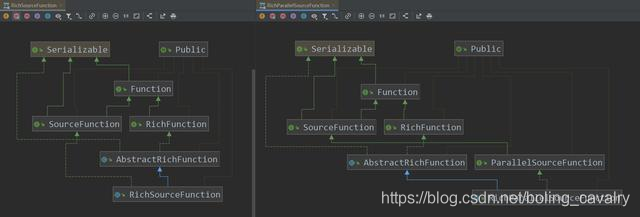
从上图可见,在RichFunction继承关系上,两者一致,在SourceFunction的继承关系上,RichlSourceFunction和RichParallelSourceFunction略有不同,RichParallelSourceFunction走的是ParallelSourceFunction这条线,而SourceFunction和ParallelSourceFunction的区别,前面已经讲过了,因此,结果不言而喻:继承RichParallelSourceFunction的DataSource的并行度是可以大于1的;
class RichParallelSourceFunctionAccess extends RichParallelSourceFunction[Access] {
var RUNNING = true
override def open(parameters: Configuration): Unit = {
println(" ==========open.invoke============ ")
}
override def close(): Unit = {
println(" ==========close.invoke============ ")
}
override def run(ctx: SourceFunction.SourceContext[Access]): Unit = {
val random = new Random()
val domain = Array("www.aa.com", "www.bb.com", "www.cc.com")
for (i <- 1 to 10){
domain(random.nextInt(domain.length))
val time = System.currentTimeMillis()
ctx.collect(Access(time,domain(random.nextInt(domain.length)),random.nextInt(5000)+i))
}
}
override def cancel(): Unit = RUNNING = false
}