概念
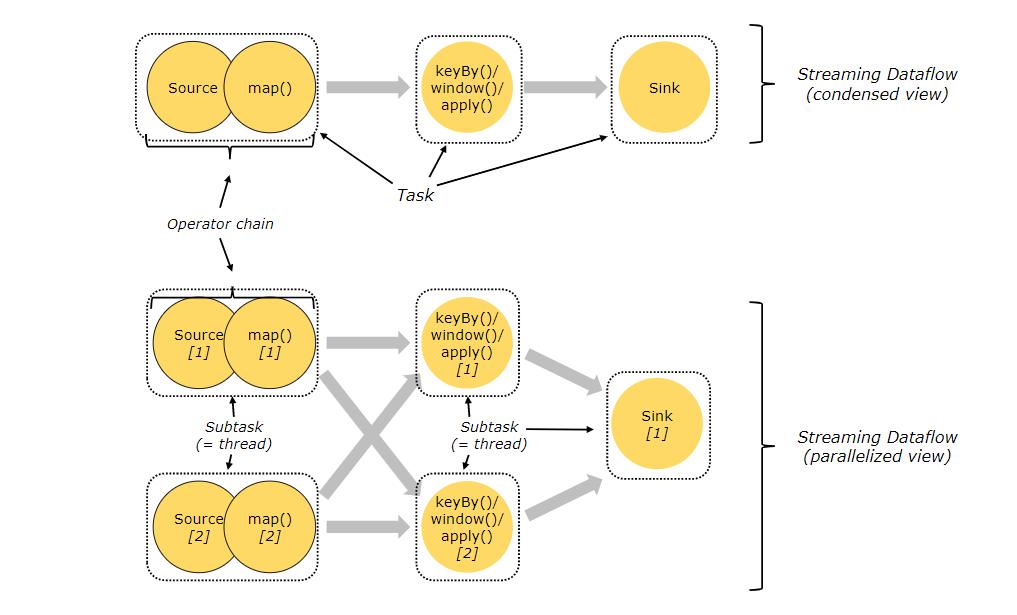
Task(任务):Task 是一个阶段多个功能相同 subTask 的集合,类似于 Spark 中的 TaskSet (Stage)。
subTask(子任务):subTask 是 Flink 中任务最小执行单元,是一个 Java 类的实例,这个 Java 类中有属性和方法,完成具体的计算逻辑。
Operator Chains(算子链):没有 shuffle 的多个算子合并在一个 subTask 中,就形成了 Operator Chains,类似于 Spark 中的 Pipeline。
Slot(插槽):Flink 中计算资源进行隔离的单元,一个 Slot 中可以运行多个 subTask,但是这些 subTask 必须是来自同一个 application 的不同阶段的 subTask。
State(状态):Flink 在运行过程中计算的中间结果
DATAFLOWS数据流介绍
Dataflows数据流介绍,参考自 Flink 官方文档。
Flink 程序的基本构建是 流(Stream)和转换(Transform)。
从概念上讲,流是对当前数据流向的记录(流也可能是永无止境的) ,而转换是将一个或多个流作为输入,根据需要求转换成我们要的格式的流的过程。
当程序执行时,Flink程序会将数据流进行映射、转换运算成我们要的格式的流。每个数据流都以一个或多个源(Source)开始,并以一个或多个接收器(Sink)结束,数据流类似于任意有向无环图(DAG)。
串行数据流
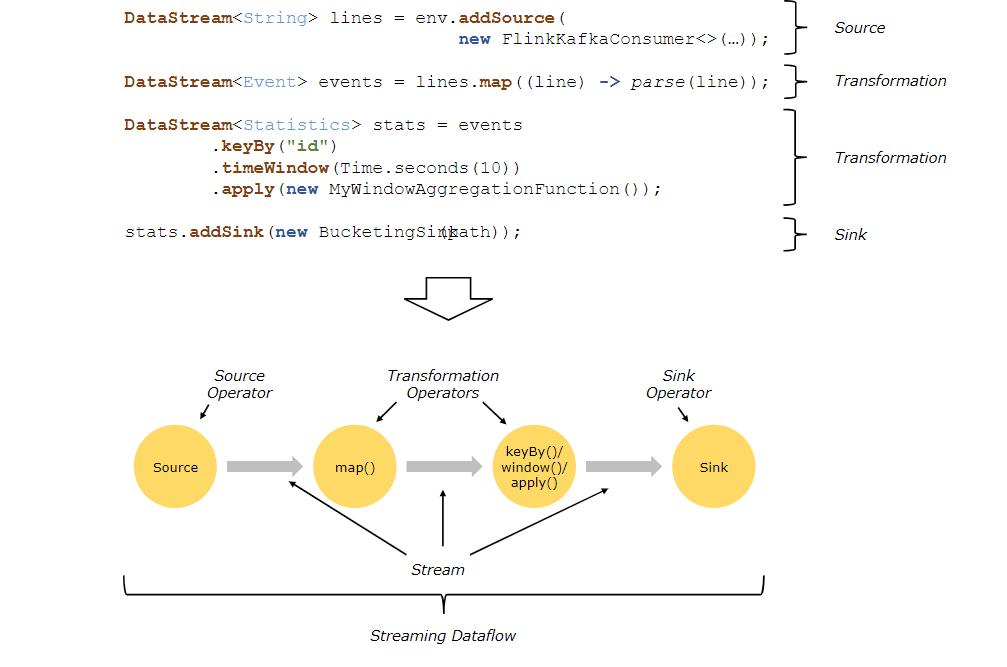
多个 Operator 之间,通过 Stream 流进行连接,Source、Transformation、Sink之间就形成了一个有向非闭环的 Dataflow Graph(数据流图)。
并行数据流
Flink 中的程序本质上是并行的。在执行期间,每一个算子(Transformation)都有一个或多个算子subTask(Operator SubTask),每个算子的 subTask 之间都是彼此独立,并在不同的线程中执行,并且可能在不同的机器或容器上执行。
Operator subTask 的数量指的就是算子的并行度。同一程序的不同算子也可能具有不同的并行度(因为可以通过 setParallelism() 方法来修改并行度)
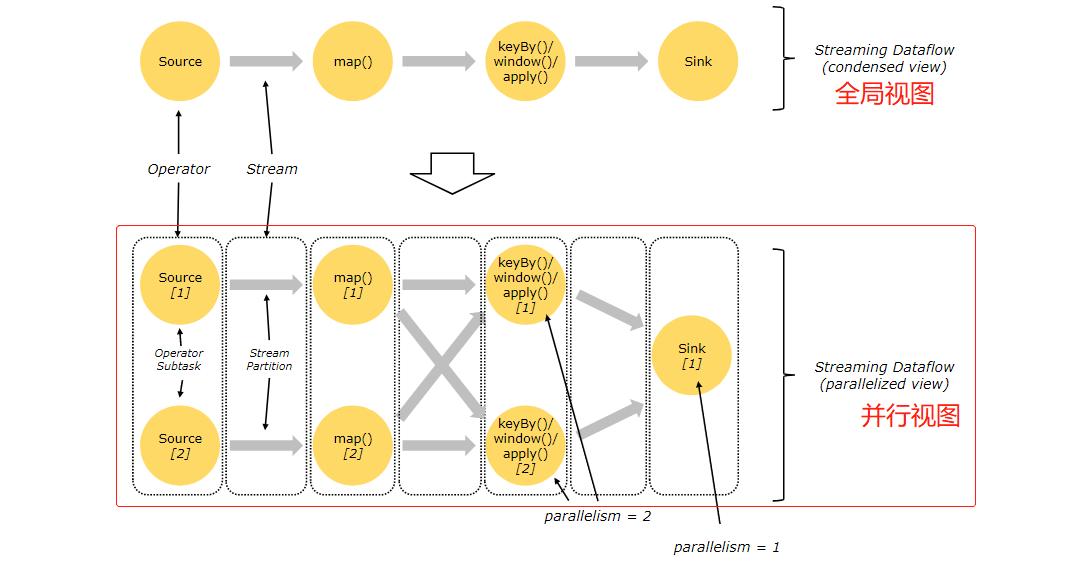
如何划分 TASK 的依据
- 并行度发生变化时;
- keyBy() /window()/apply() 等发生 Rebalance 重新分配;
- 调用 startNewChain() 方法,开启一个新的算子链;
- 调用 diableChaining()方法,即:告诉当前算子操作不使用 算子链 操作。
针对内存密集型、CPU密集型,使用 startNewChins()、disableChaining()方法,可以将当前算子单独放到一个 Task 中,使其独享当前Task的所有资源,以此来提升计算效率。
如何计算 TASK 和 SUBTASK 个数
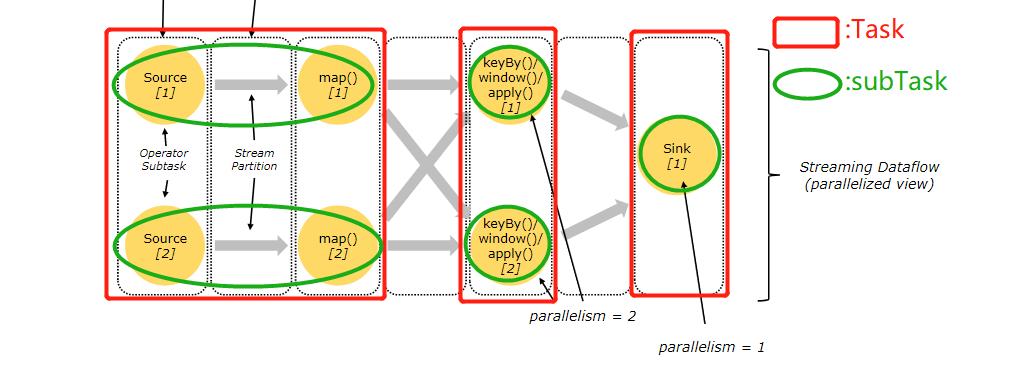
上图并行数据流,一共有 3个 Task,5个 subTask。
流可以按照一对一模式或重新分配模式在两个 Operator 算子之间传输数据:
- 一对一的流:(
例如上图中的 Source 和 map() 算子之间的流)它们都保留各自元素的分区和排序。即:map() 算子的 subtask[1] 将会与产生相同元素顺序的Source() 算子的 subtask[1] 关联,进行数据传输。 - 重新分配的流:(例如上图的
map()和 keyBy()/window()之间以及keyBy ()/window()和Sink之间)重新分配流会改变流的分区。每个算子subTask都将数据发送到不同的目标subTask,具体 subTask 取决于所选算子使用的转换方法。例如: keyBy() 通过 Hash 散列重新分区、broadcast()广播、或者 rebalance() (随机重新分区)。
DEMO进行TASK划分
object TaskDemo { |
TASK总数:4

SUBTASK总数:11

OPERATOR CHAINS介绍
Operator Chains介绍,参考自:Flink官方文档
Flink 将多个 subTask 合并成一个 Task(任务),这个过程叫做 Operator Chains,每个任务由一个线程执行。使用 Operator Chains(算子链) 可以将多个分开的 subTask 拼接成一个任务。Operator Chains 是一个有用的优化,它减少了线程到线程的切换和缓冲的开销,并在降低延迟的同时提高了总体吞吐量。
下图中的示例,数据流由五个子任务执行,因此由五个并行线程执行。