
最近集群中一些任务经常在reduce端跑出Shuffle OOM的错误,具体错误如下:
2016-12-15 08:10:57,726 WARN [main] org.apache.hadoop.mapred.YarnChild: Exception running child : org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: error in shuffle in fetcher#18 |
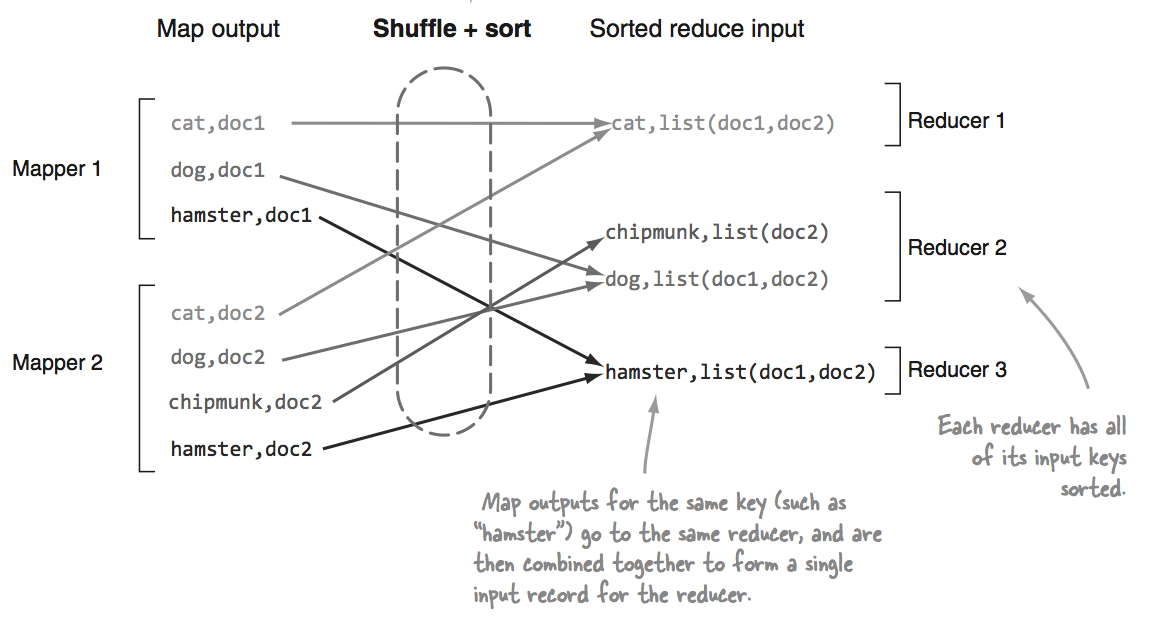
先看一下基本流程,map端进行处理后将结果放在map端local路径中,map端不断心跳汇报给namenode,在适当的阶段(另外可以写一个流程说明),reduce启动,reduce发送心跳给namenode,获取已经结束的maptask对象。之后对已经结束的map进程的数据进行拉取俗称Shuffle,拉取是通过Fetcher线程进行的,随后进行sort。
有关的几个重要参数:
public static final String SHUFFLE_INPUT_BUFFER_PERCENT = “mapreduce.reduce.shuffle.input.buffer.percent”; 默认0.7 |
这个问题是在Fetcher过程中爆出的。首先解释一下参数:
- 第一个参数SHUFFLE_INPUT_BUFFER_PERCENT是指在总的HeapSize中shuffle占得内存百分比,我们总的HeapSize是1.5G,那大概Fetcher就是1.0G。
- SHUFFLE_MEMORY_LIMIT_PERCENT是指的map copy过来的数据是放内存中还是直接写磁盘。 超过1.5G*0.7*0.25=250M的都放在磁盘中,其它开辟内存空间,放在内存中。
- SHUFFLE_MERGE_PERCENT是指merge的百分比,超过这个百分比后停止fetcher,进行merge,merge到磁盘中。
另外如果是reduce 内存不够引起的shuffle oom,可以增加reduce数(set mapreduce.job.reduces=xxx)或者
(set hive.exec.reducers.bytes.per.reducer=150000000;) ,默认是1G(现在的版本默认是256M)
跑出OOM后,调了下jvm参数,获取heapdump数据,根据MAT获取以下数据。数据如下:
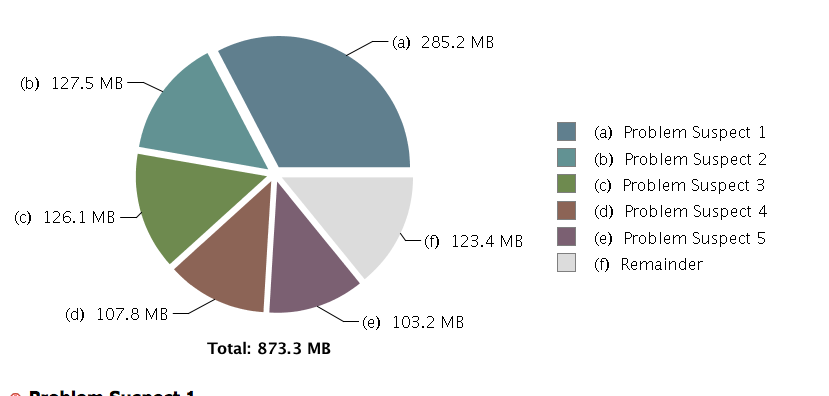
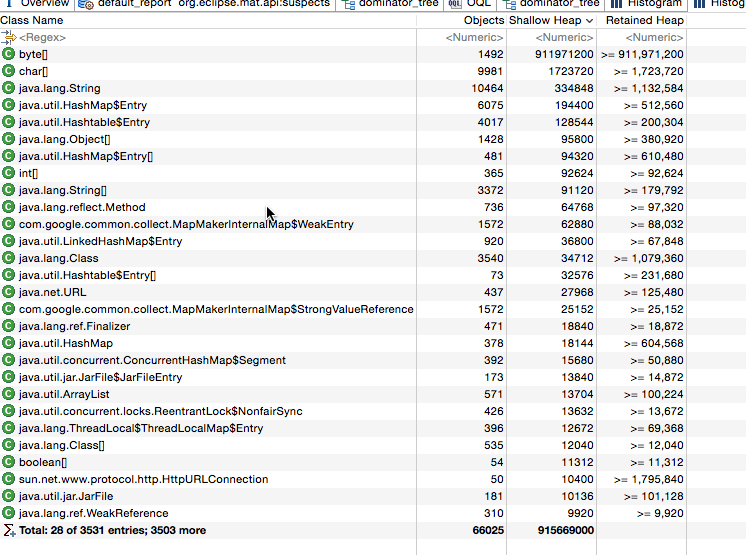
首先发现整体的内存并没有到1.5G。其次,看了下内存对象分布,byte数组占了很大比例,这也很正常,所有内存中的buffer都是以byte数组形式出现的。在对比一下byte数组大小,大于900M,这就有一个问题了,首先整体HeapSize是1.5G,old区大概是1个G,这时候如果byte数组是900M来一个100M+的拷贝,由于是大内存开辟,不会进入Young区,直接开辟内存空间到Old区,而Old区即使fullgc也没有那么多连续空间,所以分配失败,报OOM错误。这时,只是一个假设,调整Xmn参数,减小Young区内存大小,增大Old区进行测试,成功,印证了想法。
但是对于我们跑任务调整jvm参数毕竟不现实,那么我们根据经验调整SHUFFLE_INPUT_BUFFER_PERCENT参数就可以了,调整为0.6即可解决问题。
另一种方法是调低mapreduce.reduce.shuffle.memory.limit.percent的值,默认为0.25,现在调成0.1即可解决问题,但是由于写的内存从0.25变成0.1,速度会变慢。相反如果我们想拉取较多的数据进内存的话,可以适当调大这个值。