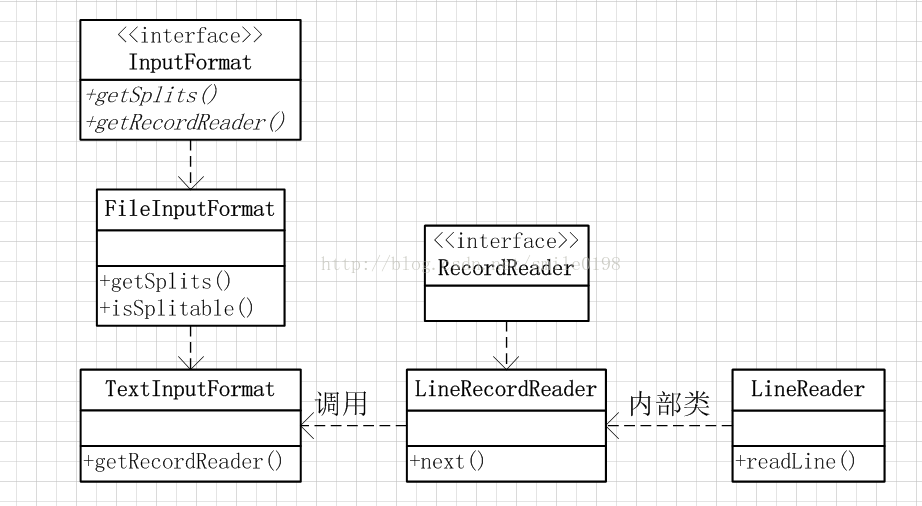
类关系
主要功能: 获取splits
概念:
goalSize: totalsize/numSplits ; minSize: InputSplit 最小值 配置参数 blockSize: block大小
公式: splitSize = max(minSize, min(goalSize,blockSize))
源码:
public InputSplit[] getSplits(JobConf job, int numSplits) throws IOException { StopWatch sw = new StopWatch().start(); FileStatus[] files = listStatus(job); job.setLong(NUM_INPUT_FILES, files.length); long totalSize = 0 ; for (FileStatus file: files) { if (file.isDirectory()) { throw new IOException("Not a file: " + file.getPath()); } totalSize += file.getLen(); } long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits); long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input. FileInputFormat.SPLIT_MINSIZE, 1 ), minSplitSize); ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits); NetworkTopology clusterMap = new NetworkTopology(); for (FileStatus file: files) { Path path = file.getPath(); long length = file.getLen(); if (length != 0 ) { FileSystem fs = path.getFileSystem(job); BlockLocation[] blkLocations; if (file instanceof LocatedFileStatus) { blkLocations = ((LocatedFileStatus) file).getBlockLocations(); } else { blkLocations = fs.getFileBlockLocations(file, 0 , length); } if (isSplitable(fs, path)) { long blockSize = file.getBlockSize(); long splitSize = computeSplitSize(goalSize, minSize, blockSize); long bytesRemaining = length; while (((double ) bytesRemaining)/splitSize > SPLIT_SLOP) { String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length-bytesRemaining, splitSize, clusterMap); splits.add(makeSplit(path, length-bytesRemaining, splitSize, splitHosts[0 ], splitHosts[1 ])); bytesRemaining -= splitSize; } if (bytesRemaining != 0 ) { String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length - bytesRemaining, bytesRemaining, clusterMap); splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining, splitHosts[0 ], splitHosts[1 ])); } } else { String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0 ,length,clusterMap); splits.add(makeSplit(path, 0 , length, splitHosts[0 ], splitHosts[1 ])); } } else { splits.add(makeSplit(path, 0 , length, new String[0 ])); } } sw.stop(); if (LOG.isDebugEnabled()) { LOG.debug("Total # of splits generated by getSplits: " + splits.size() + ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS)); } return splits.toArray(new FileSplit[splits.size()]); }
TextInputFormat 主要方法:getRecordReader,作用就是调用recordReader
public RecordReader<LongWritable, Text> getRecordReader ( InputSplit genericSplit, JobConf job, Reporter reporter) throws IOException { reporter.setStatus(genericSplit.toString()); String delimiter = job.get("textinputformat.record.delimiter" ); byte [] recordDelimiterBytes = null ; if (null != delimiter) { recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8); } return new LineRecordReader(job, (FileSplit) genericSplit, recordDelimiterBytes); }
LineRecordReader 主要功能:读取split内容,通过next方法将每一行内容赋值给value,行坐标赋值给key,给调用方。这里面解决了一个行切分的问题,一行记录被切分到两个split中,解决办法是,每次不读取split的第一行,在读取到split末尾时 多读一行,这样就解决了切分的问题
在构造方法中有下面一段代码,就是将游标跳过第一行
if (start != 0 ) {start += in.readLine(new Text(), 0 , maxBytesToConsume(start)); } this .pos = start;
读取方法:
public synchronized boolean next (LongWritable key, Text value) throws IOException { while (getFilePosition() <= end || in.needAdditionalRecordAfterSplit()) { key.set(pos); int newSize = 0 ; if (pos == 0 ) { newSize = skipUtfByteOrderMark(value); } else { newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos)); pos += newSize; } if (newSize == 0 ) { return false ; } if (newSize < maxLineLength) { return true ; } LOG.info("Skipped line of size " + newSize + " at pos " + (pos - newSize)); } return false ; }
LineReader 读取类,每次拿64K的数据到buffer中,然后按换行符切分行,返回一行的内容