
什么是left semi join
Semi Join,也叫半连接,是从分布式数据库中借鉴过来的方法。它的产生动机是:对于reduce join,跨机器的数据传输量非常大,这成了join操作的一个瓶颈,如果能够在map端过滤掉不会参加join操作的数据,则可以大大节省网络IO,提升执行效率。
主要是用于IN/EXISTS子查询的一种更高效的实现
select name,a.sex from student a where a.sex in (select id from sex)
替换成
select a.name,a.sex from student a left semi join sex b on a.sex = b.id;
特点
- left semi join 的限制是,join子句中右边的表只能在on子句中设置过滤条件,在where子句、select子句或其他地方过滤都不行。
- left semi join 是只传递表的 join key 给 map 阶段,因此left semi join 中最后 select 的结果只许出现左表。
- 因为 left semi join 是 in(keySet) 的关系,遇到右表重复记录,左表会跳过,而 join 则会一直遍历。这就导致右表有重复值得情况下 left semi join 只产生一条,join 会产生多条,也会导致 left semi join 的性能更高。
以下A表和B表进行 join 或 left semi join,然后 select 出所有字段,结果区别如下:
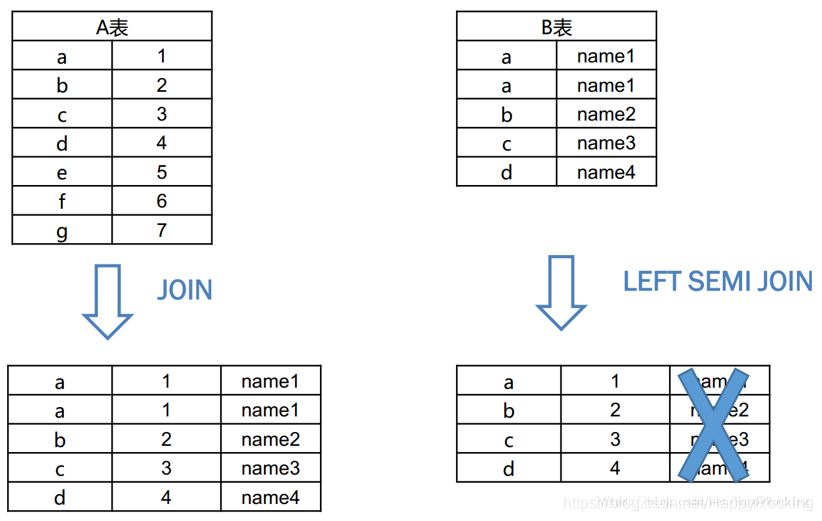
注意:蓝色叉的那一列实际是不存在left semi join中的,因为最后 select 的结果只许出现左表。
in/exists的底层实现
我们知道left semi join是map端join,主要是用于替换IN/EXISTS子查询提高查询效率。
但是in/exists的底层实现是什么,为什么需要使用left semi join作为替换呢?
使用的hive版本是hive-1.1.0-cdh5.16.2,查看sql的执行计划来看看left semi join、in、exists的执行逻辑有什么不同。
分别执行如下sql:
explain select name from student a where exists (select id from sex b where a.sex = b.id ); |
执行计划中都是使用的map端操作,而且都是使用的Left Semi Join
查看详细的执行计划分别执行如下sql:
explain extended select name from student a where exists (select id from sex b where a.sex = b.id ); |
发现详细的执行计划中还是只有map端的操作,并且还是使用的Left Semi Join。
得出结论,使用in/extsis底层都是使用的left semi join,说明in/extsis被优化过,可以跳过left semi join直接使用in/extsis