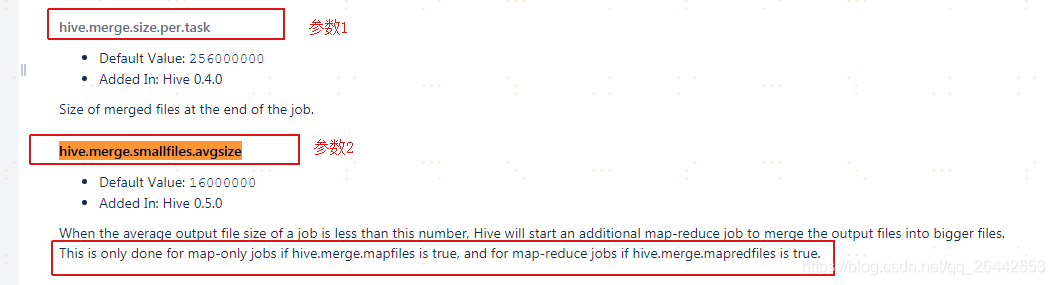
-- 设置小文件合并 set hive.merge.mapfiles=true; set hive.merge.mapredfiles=true; set hive.merge.size.per.task = 256000000 ; set hive.merge.smallfiles.avgsize= 256000000 ;
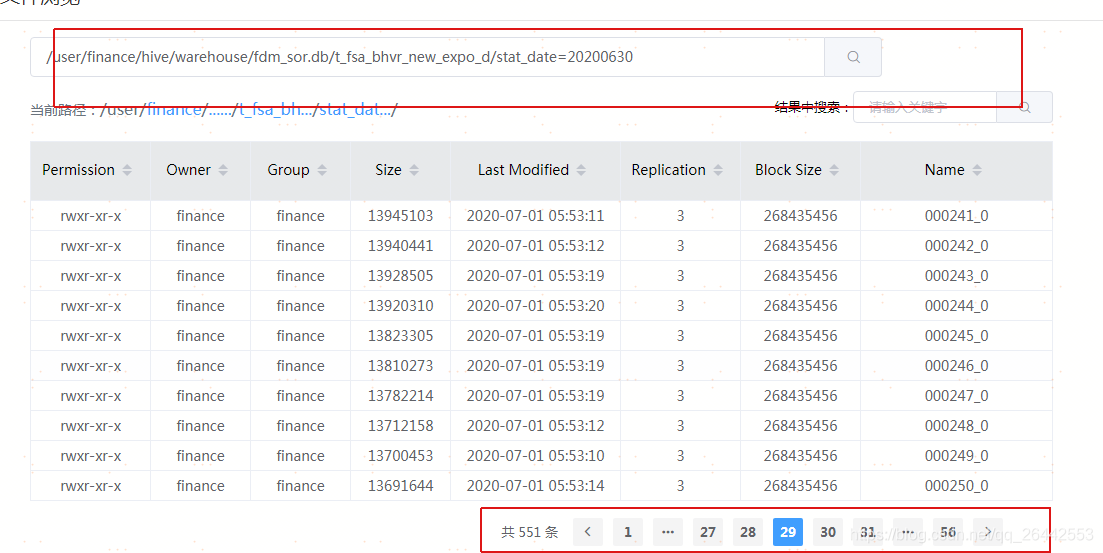
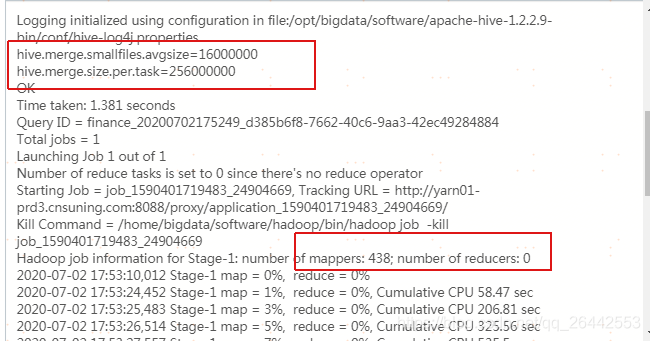
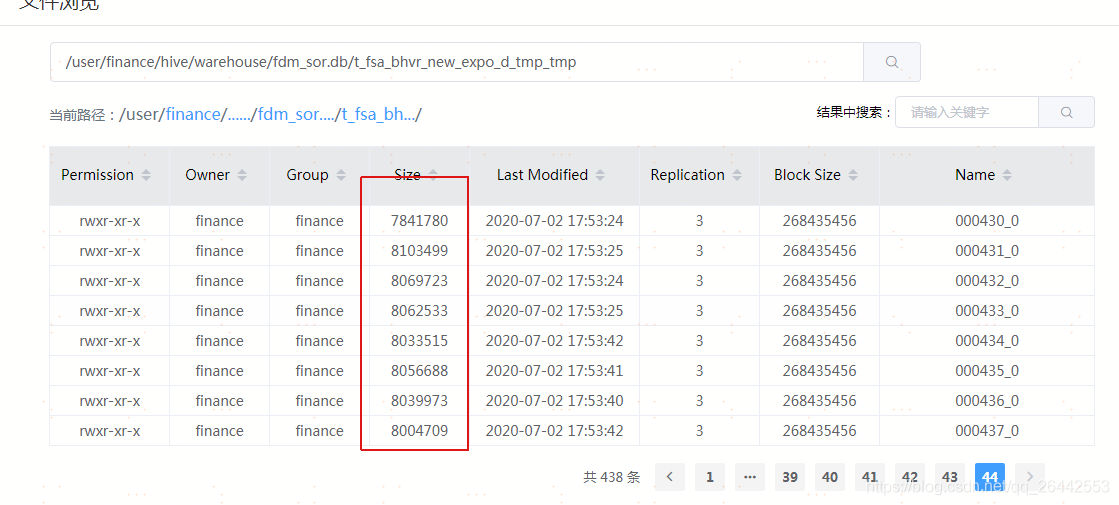
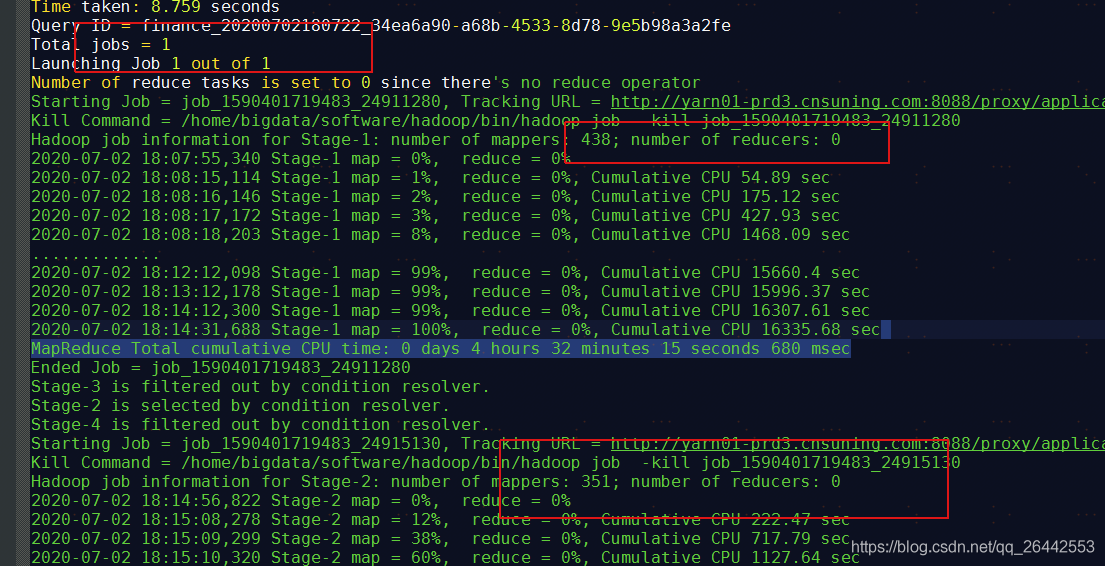
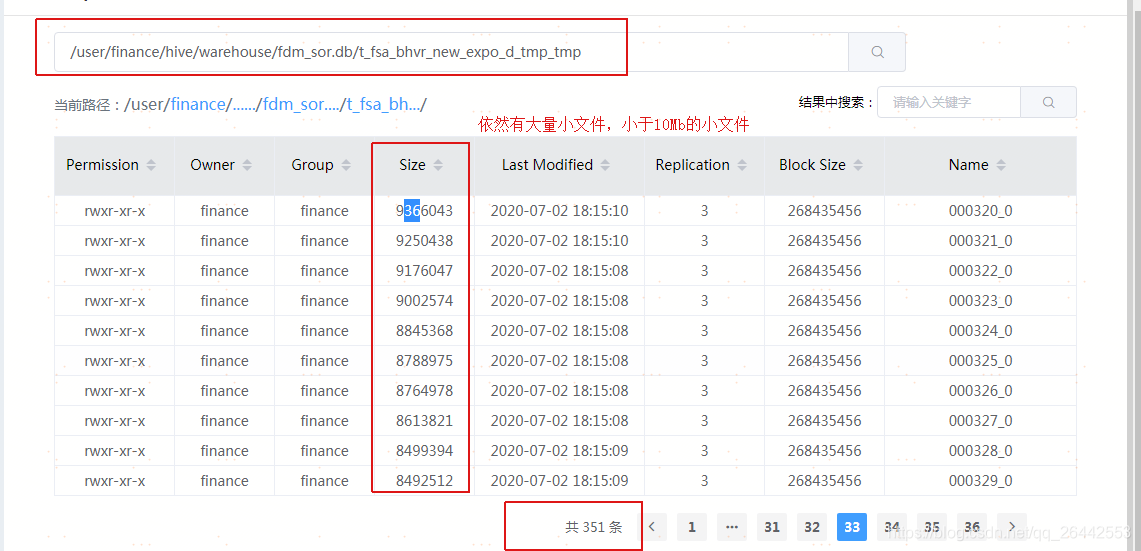
set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; --官方默认值,也是当前平台默认值 set hive.merge.smallfiles.avgsize=16000000; --官方默认值,也是当前平台默认值 set hive.merge.size.per.task=256000000; --官方默认值,也是当前平台默认值 set hive.merge.mapfiles =true ; --官方默认值,也是当前平台默认值 set hive.merge.mapredfiles = true ; --官方默认值,也是当前平台默认值 droptableifexists FDM_SOR.T_FSA_BHVR_NEW_EXPO_D_tmp_tmp; createtable FDM_SOR.t_fsa_bhvr_new_expo_d_tmp_tmp storedas orc as select * from FDM_SOR.t_fsa_bhvr_new_expo_d where stat_date = '20200630'
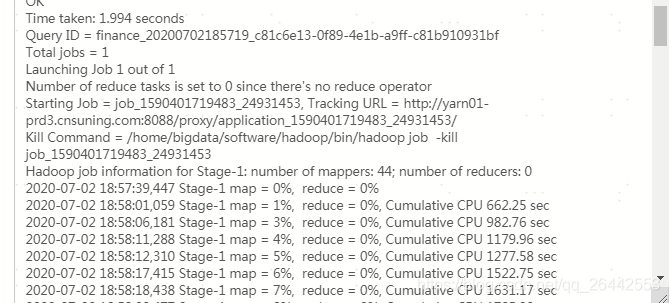
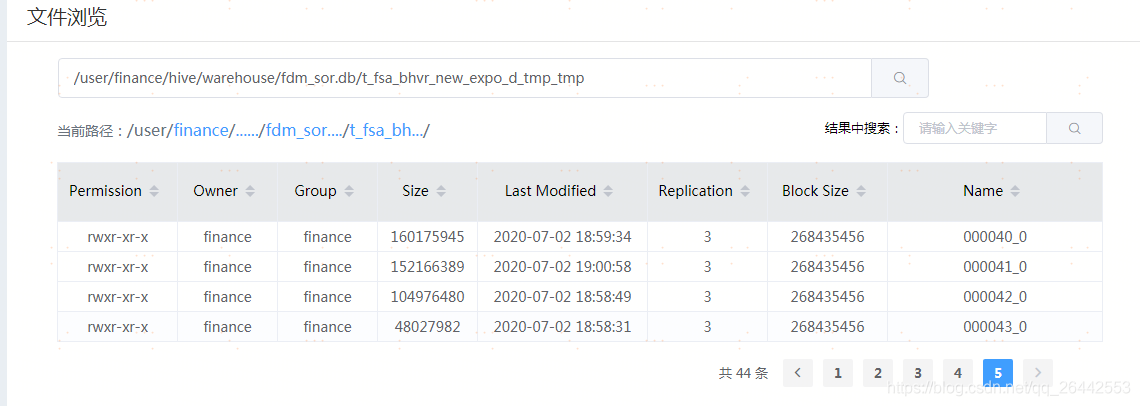
set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; --官方默认值,也是当前平台默认值 set hive.merge.smallfiles.avgsize=256000000; --改了这个值,由默认的16Mb,改成256Mb set hive.merge.size.per.task=256000000; --官方默认值,也是当前平台默认值 set hive.merge.mapfiles =true ; --官方默认值,也是当前平台默认值 set hive.merge.mapredfiles = true ; --官方默认值,也是当前平台默认值 droptableifexists FDM_SOR.T_FSA_BHVR_NEW_EXPO_D_tmp_tmp; createtable FDM_SOR.t_fsa_bhvr_new_expo_d_tmp_tmp storedas orc as select * from FDM_SOR.t_fsa_bhvr_new_expo_d where stat_date = '20200630'
set mapred.max.split.size=256000000; set mapred.min.split.size.per.node=100000000; set mapred.min.split.size.per.rack=100000000; set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; set hive.merge.mapfiles = true ; set hive.merge.mapredfiles = true ; set hive.merge.size.per.task = 256000000 ; set hive.merge.smallfiles.avgsize=160000000 ; droptableifexists FDM_SOR.T_FSA_BHVR_NEW_EXPO_D_tmp_tmp; createtable FDM_SOR.T_FSA_BHVR_NEW_EXPO_D_tmp_tmp storedas orc as select * from FDM_SOR.T_FSA_BHVR_NEW_EXPO_D where stat_date = '20200630'