
什么是向量化查询执行
在标准的查询执行系统中,每次只处理一行数据,每次处理都要走过较长的代码路径和元数据解释,从而导致CPU使用率非常低。
而在向量化查询执行中,每次处理包含多行记录的一批数据,每一批数据中的每一列都会被存储为一个向量(一个原始数据类型的数组),这就极大地减少了执行过程中的方法调用、反序列化和不必要的if-else操作,大大减少CPU的使用时间。
如下图所示:
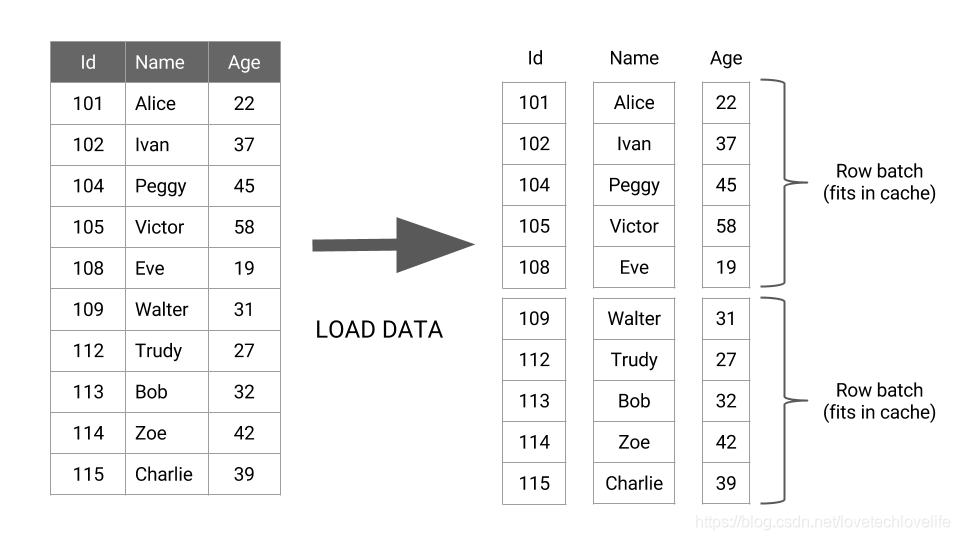
上图中可以看出,数据加载出来之后,每批数据中的每一列都会转成一个向量,在后续的执行过程中,数据是一批批的从一个操作符流经另一个操作符,而不是一行行的。
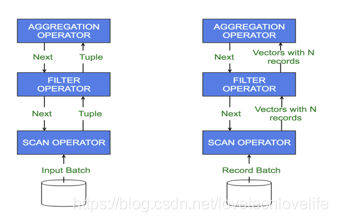
但是,向量化查询执行有一个限制,就是我们必须把要查询的数据存储为列式格式。比如
- 磁盘列式存储格式:ORC、Parquet
- 内存列式存储格式:Arrow
列式存储
列式存储与行式存储将数据按行进行存储不同的是,它将数据以每列进行组织。如下图:

列式存储的优势:
- 相同类型的数据放在一起进行存储,可以有更高的压缩率,减少了磁盘占用。
- 只返回指定查询的列,而不用返回整行记录之后再取出指定查询的列,最小化了I/O操作。
了解了列式存储的存储格式,我们就很容易明白,在使用列式存储格式的情况下,向量化查询才能方便地将每批数据中的每列值进行向量化。
Spark向量化查询执行
Spark支持三种形式的向量化查询:
- 内存列式存储
spark.sql.inMemoryColumnarStorage.enableVectorizedReader:为内存列式存储(比如前面提到的Apache Arrow)启用向量化读取,默认为true,从Spark 2.3.1开始支持此配置。 - Parquet格式
spark.sql.parquet.enableVectorizedReader:为parquet格式启用向量化查询,默认为true,从Spark 2.0.0开始支持此配置。 - ORC格式
spark.sql.orc.enableVectorizedReader:为ORC格式启用向量化查询,默认为true,从Spark 2.3.0开始支持此配置。
Hive向量化查询执行
Hive中,向量化查询执行在Hive 0.13.0及以后版本可用,默认情况下是关闭的,可通过下面配置启用:
set hive.vectorized.execution.enabled = true; |
Hive向量化执行支持数据类型有:tinyint、smallint、int、bigint、boolean、float、double、decimal、date、timestamp、string。
如果使用了其他数据类型,查询将不会使用向量化执行,而是每次只会查询一行数据。
可以通过explain来查看查询是否使用了向量化,如果输出信息中Execution mode的值为vectorized,则使用了向量化查询:
explain select count(*) from vectorizedtable; |