
思维导图

NIO概述
定义
java.nio全称java non-blocking IO,是指JDK1.4 及以上版本里提供的新api(New IO) ,为所有的原始类型(boolean类型除外)提供缓存支持的数据容器,使用它可以提供非阻塞式的高伸缩性网络(来源于百度百科)。
为什么使用NIO
在上面的描述中提到,是在JDK1.4以上的版本才提供NIO,那在之前使用的是什么呢?答案很简单,就是BIO(阻塞式IO),也就是我们常用的IO流。
BIO的问题其实不用多说了,因为在使用BIO时,主线程会进入阻塞状态,这就非常影响程序的性能,不能充分利用机器资源。但是这样就会有人提出疑问了,那我使用多线程不就可以了吗?
但是在高并发的情况下,会创建很多线程,线程会占用内存,线程之间的切换也会浪费资源开销。
而NIO只有在连接/通道真正有读写事件发生时(事件驱动),才会进行读写,就大大地减少了系统的开销。不必为每一个连接都创建一个线程,也不必去维护多个线程。
避免了多个线程之间的上下文切换,导致资源的浪费。
缓冲区
什么是缓冲区
我们先看以下这张类图,可以看到Buffer有七种类型。

Buffer是一个内存块。在NIO中,所有的数据都是用Buffer处理,有读写两种模式。所以NIO和传统的IO的区别就体现在这里。传统IO是面向Stream流,NIO而是面向缓冲区(Buffer)。
常用的类型ByteBuffer
一般我们常用的类型是ByteBuffer,把数据转成字节进行处理。实质上是一个byte[]数组。
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer>{ |
创建Buffer的方式
主要分成两种:JVM堆内内存块Buffer、堆外内存块Buffer。
创建堆内内存块(非直接缓冲区)的方法是:
//创建堆内内存块HeapByteBuffer |
创建堆外内存块(直接缓冲区)的方法:
//创建堆外内存块DirectByteBuffer |
HeapByteBuffer与DirectByteBuffer的区别
其实根据类名就可以看出,HeapByteBuffer所创建的字节缓冲区就是在JVM堆中的,即JVM内部所维护的字节数组。而DirectByteBuffer是直接操作操作系统本地代码创建的内存缓冲数组。
DirectByteBuffer的使用场景:
- java程序与本地磁盘、socket传输数据
- 大文件对象,可以使用。不会受到堆内存大小的限制。
- 不需要频繁创建,生命周期较长的情况,能重复使用的情况。
HeapByteBuffer的使用场景:
除了以上的场景外,其它情况还是建议使用HeapByteBuffer,没有达到一定的量级,实际上使用DirectByteBuffer是体现不出优势的。
Buffer的初体验
接下来,使用ByteBuffer做一个小例子,熟悉一下:
public static void main(String[] args) throws Exception { |
这上面有一个flip()方法是很重要的。意思是切换到读模式。上面已经提到缓存区是双向的,既可以往缓冲区写入数据,也可以从缓冲区读取数据。但是不能同时进行,需要切换。那么这个切换模式的本质是什么呢?
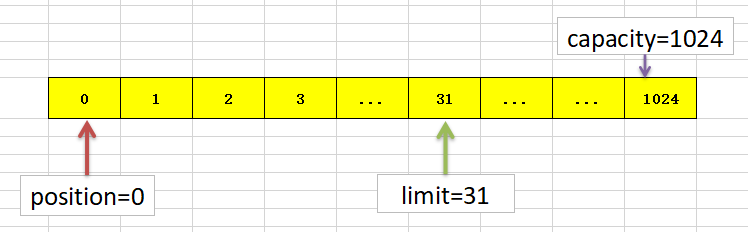
三个重要参数
//位置,默认是从第一个开始 |
那么我们以上面的例子,一句一句代码进行分析:
String msg = "java技术爱好者,起飞!"; |
当创建一个缓冲区时,参数的值是这样的:
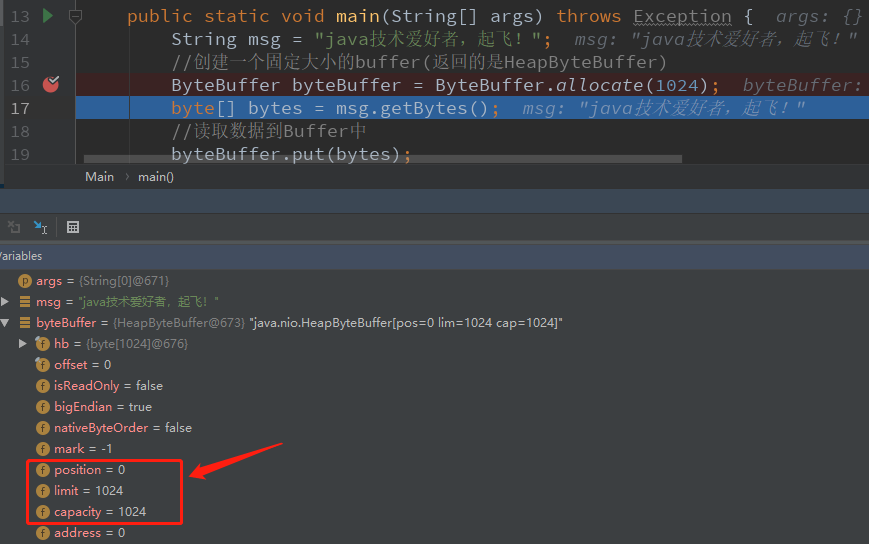

当执行到byteBuffer.put(bytes),当put()进入多少数据,position就会增加多少,参数就会发生变化:
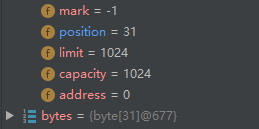
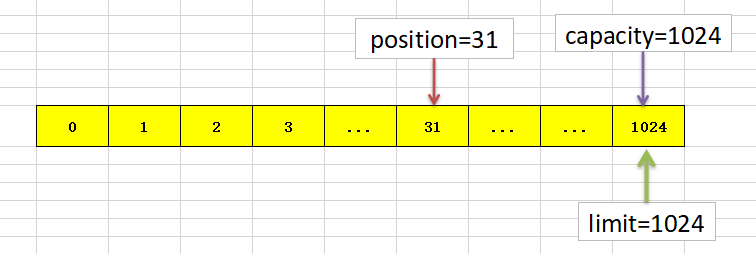
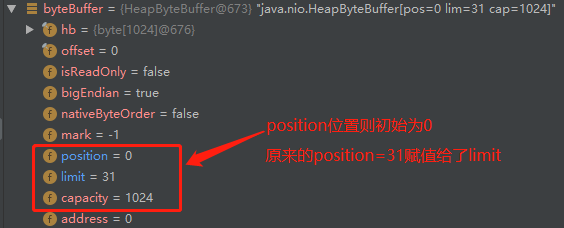
接下来关键一步byteBuffer.flip(),会发生如下变化:
flip()方法的源码如下:
public final Buffer flip() { |
为什么要这样赋值呢?因为下面有一句循环条件判断:
byteBuffer.hasRemaining(); |
接下来就是在while循环中get()读取数据,读取完之后。
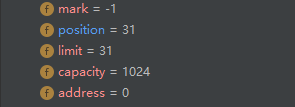

最后当position等于limit时,循环判断条件不成立,就跳出循环,读取完毕。
所以可以看出实质上capacity容量大小是不变的,实际上是通过控制position和limit的值来控制读写的数据。